27 Feb 2024
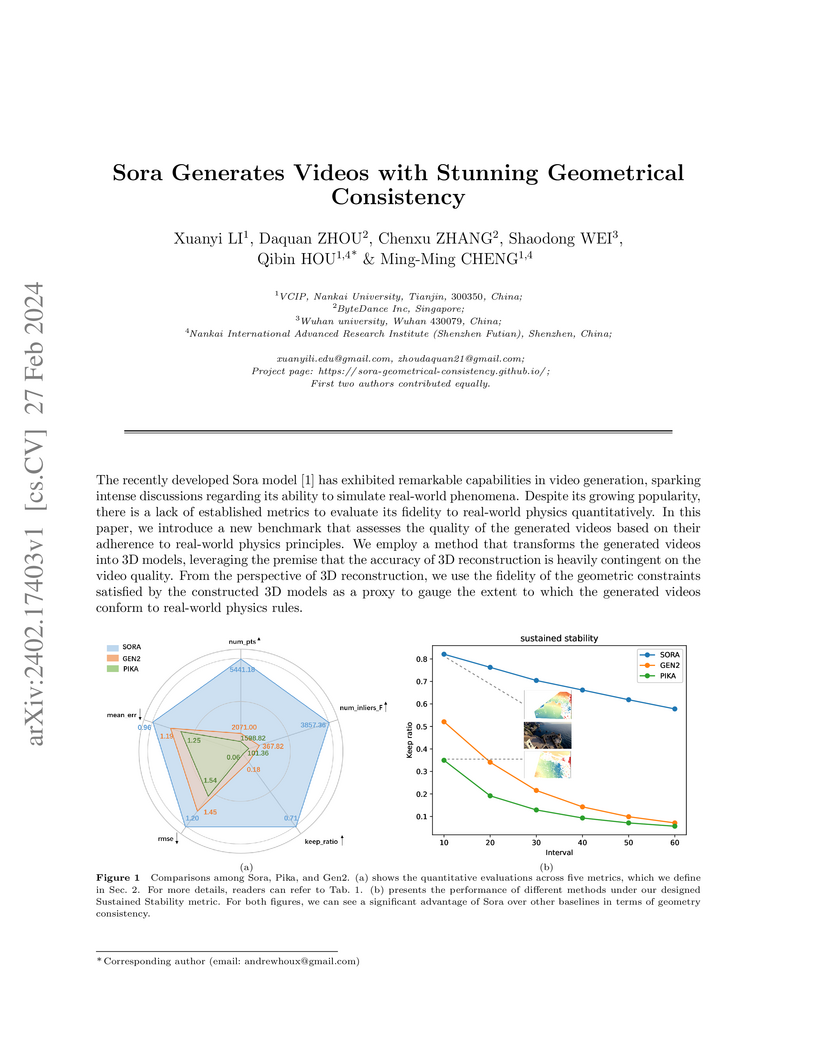
Researchers at Nankai University and ByteDance developed a quantitative benchmark to assess the geometrical consistency of AI-generated videos using 3D reconstruction techniques. Their analysis showed that OpenAI's Sora model produces videos with markedly higher physical fidelity and sustained temporal stability compared to contemporary text-to-video models like Pika Labs and Gen-2.

29 May 2025

Novel view synthesis for underwater scene reconstruction presents unique
challenges due to complex light-media interactions. Optical scattering and
absorption in water body bring inhomogeneous medium attenuation interference
that disrupts conventional volume rendering assumptions of uniform propagation
medium. While 3D Gaussian Splatting (3DGS) offers real-time rendering
capabilities, it struggles with underwater inhomogeneous environments where
scattering media introduce artifacts and inconsistent appearance. In this
study, we propose a physics-based framework that disentangles object appearance
from water medium effects through tailored Gaussian modeling. Our approach
introduces appearance embeddings, which are explicit medium representations for
backscatter and attenuation, enhancing scene consistency. In addition, we
propose a distance-guided optimization strategy that leverages pseudo-depth
maps as supervision with depth regularization and scale penalty terms to
improve geometric fidelity. By integrating the proposed appearance and medium
modeling components via an underwater imaging model, our approach achieves both
high-quality novel view synthesis and physically accurate scene restoration.
Experiments demonstrate our significant improvements in rendering quality and
restoration accuracy over existing methods. The project page is available at
this https URL

30 Mar 2024
Transformer-based approaches have achieved superior performance in image restoration, since they can model long-term dependencies well. However, the limitation in capturing local information restricts their capacity to remove degradations. While existing approaches attempt to mitigate this issue by incorporating convolutional operations, the core component in Transformer, i.e., self-attention, which serves as a low-pass filter, could unintentionally dilute or even eliminate the acquired local patterns. In this paper, we propose HIT, a simple yet effective High-frequency Injected Transformer for image restoration. Specifically, we design a window-wise injection module (WIM), which incorporates abundant high-frequency details into the feature map, to provide reliable references for restoring high-quality images. We also develop a bidirectional interaction module (BIM) to aggregate features at different scales using a mutually reinforced paradigm, resulting in spatially and contextually improved representations. In addition, we introduce a spatial enhancement unit (SEU) to preserve essential spatial relationships that may be lost due to the computations carried out across channel dimensions in the BIM. Extensive experiments on 9 tasks (real noise, real rain streak, raindrop, motion blur, moiré, shadow, snow, haze, and low-light condition) demonstrate that HIT with linear computational complexity performs favorably against the state-of-the-art methods. The source code and pre-trained models will be available at this https URL.
There are no more papers matching your filters at the moment.
