
08 Dec 2025

Researchers from Fudan University and Shanghai Innovation Institute introduced RoPE++, an extension of Rotary Position Embeddings that re-incorporates the previously discarded imaginary component of attention scores to improve long-context modeling in Large Language Models. This method consistently outperforms standard RoPE on various benchmarks and offers significant KV-cache and parameter efficiency.

09 Dec 2025

Recent advances in diffusion transformers have empowered video generation models to generate high-quality video clips from texts or images. However, world models with the ability to predict long-horizon futures from past observations and actions remain underexplored, especially for general-purpose scenarios and various forms of actions. To bridge this gap, we introduce Astra, an interactive general world model that generates real-world futures for diverse scenarios (e.g., autonomous driving, robot grasping) with precise action interactions (e.g., camera motion, robot action). We propose an autoregressive denoising architecture and use temporal causal attention to aggregate past observations and support streaming outputs. We use a noise-augmented history memory to avoid over-reliance on past frames to balance responsiveness with temporal coherence. For precise action control, we introduce an action-aware adapter that directly injects action signals into the denoising process. We further develop a mixture of action experts that dynamically route heterogeneous action modalities, enhancing versatility across diverse real-world tasks such as exploration, manipulation, and camera control. Astra achieves interactive, consistent, and general long-term video prediction and supports various forms of interactions. Experiments across multiple datasets demonstrate the improvements of Astra in fidelity, long-range prediction, and action alignment over existing state-of-the-art world models.

08 Dec 2025

Apple researchers introduced FAE (Feature Auto-Encoder), a minimalist framework using a single attention layer and a double-decoder architecture to adapt high-dimensional self-supervised visual features into compact, generation-friendly latent spaces. FAE achieves competitive FID scores on ImageNet (1.29) and MS-COCO (6.90) for image generation while preserving semantic understanding capabilities of the original pre-trained encoders.

08 Dec 2025
The paper introduces Group Representational Position Encoding (GRAPE), a unified group-theoretic framework that re-conceptualizes and unifies existing positional encoding mechanisms like RoPE and ALiBi. It provides a principled design space for new encodings, demonstrating improved training stability and superior zero-shot performance in large language models.
09 Dec 2025

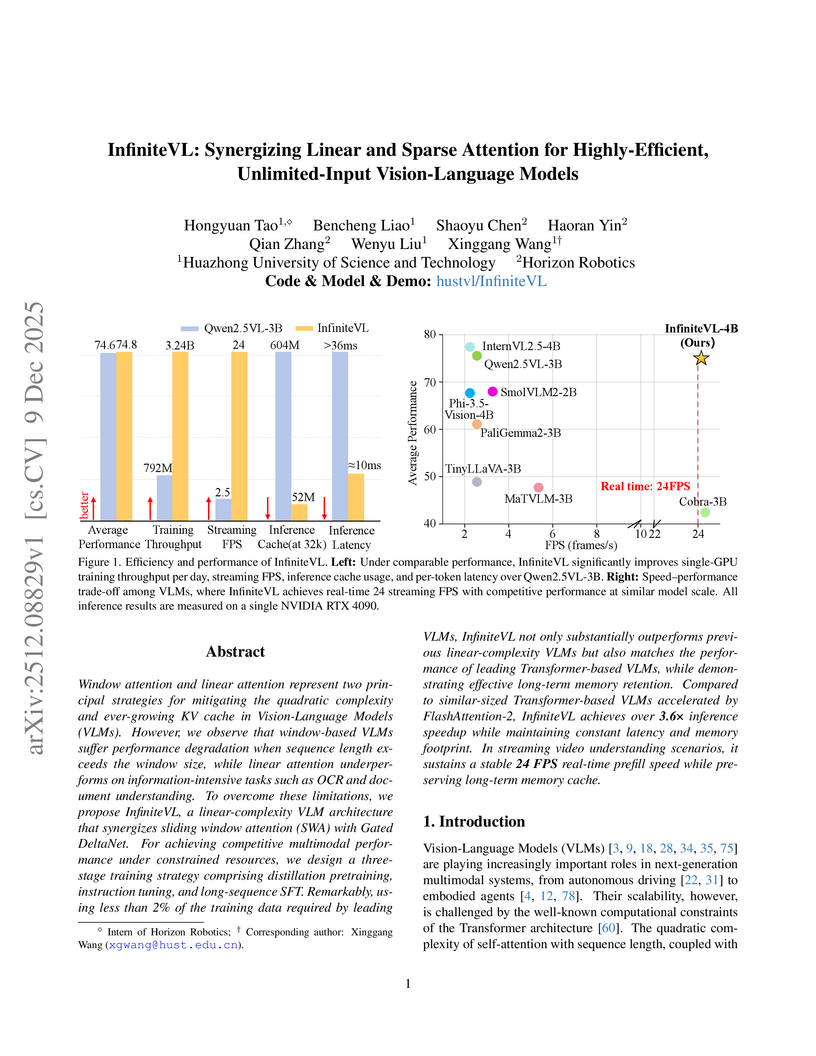
Window attention and linear attention represent two principal strategies for mitigating the quadratic complexity and ever-growing KV cache in Vision-Language Models (VLMs). However, we observe that window-based VLMs suffer performance degradation when sequence length exceeds the window size, while linear attention underperforms on information-intensive tasks such as OCR and document understanding. To overcome these limitations, we propose InfiniteVL, a linear-complexity VLM architecture that synergizes sliding window attention (SWA) with Gated DeltaNet. For achieving competitive multimodal performance under constrained resources, we design a three-stage training strategy comprising distillation pretraining, instruction tuning, and long-sequence SFT. Remarkably, using less than 2\% of the training data required by leading VLMs, InfiniteVL not only substantially outperforms previous linear-complexity VLMs but also matches the performance of leading Transformer-based VLMs, while demonstrating effective long-term memory retention. Compared to similar-sized Transformer-based VLMs accelerated by FlashAttention-2, InfiniteVL achieves over 3.6\times inference speedup while maintaining constant latency and memory footprint. In streaming video understanding scenarios, it sustains a stable 24 FPS real-time prefill speed while preserving long-term memory cache. Code and models are available at this https URL.
07 Dec 2025
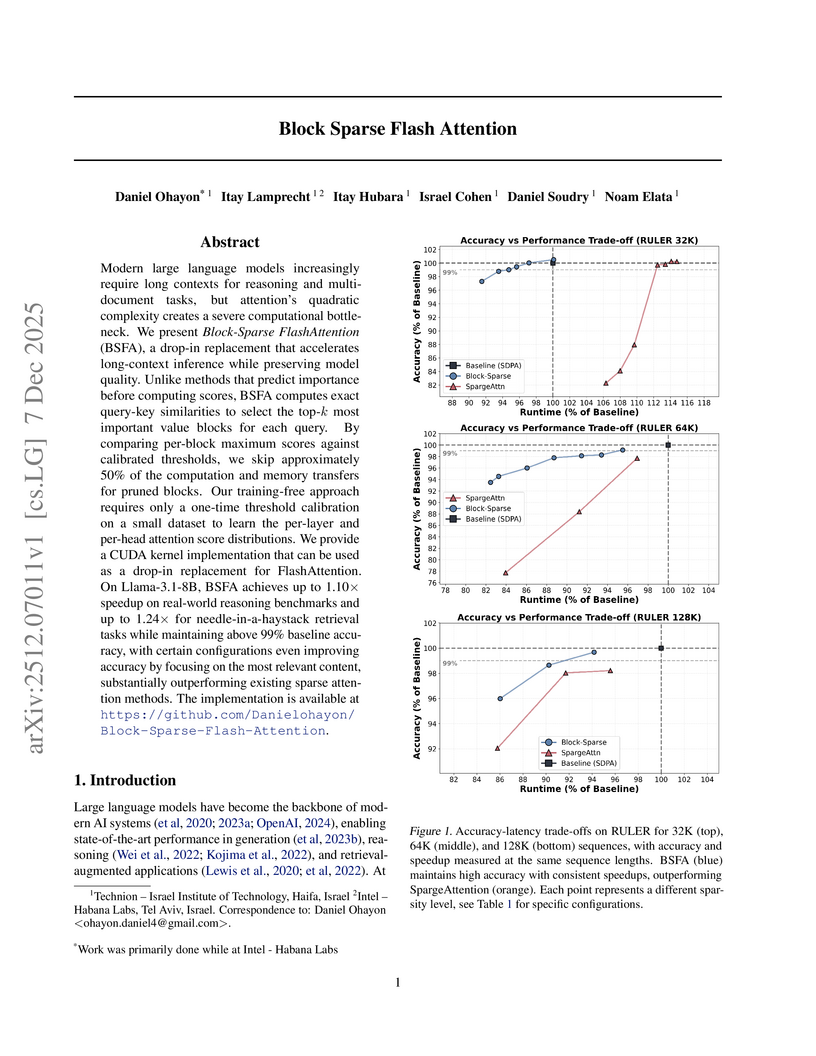
Modern large language models increasingly require long contexts for reasoning and multi-document tasks, but attention's quadratic complexity creates a severe computational bottleneck. We present Block-Sparse FlashAttention (BSFA), a drop-in replacement that accelerates long-context inference while preserving model quality. Unlike methods that predict importance before computing scores, BSFA computes exact query-key similarities to select the top-k most important value blocks for each query. By comparing per-block maximum scores against calibrated thresholds, we skip approximately 50% of the computation and memory transfers for pruned blocks. Our training-free approach requires only a one-time threshold calibration on a small dataset to learn the per-layer and per-head attention score distributions. We provide a CUDA kernel implementation that can be used as a drop-in replacement for FlashAttention. On Llama-3.1-8B, BSFA achieves up to 1.10x speedup on real-world reasoning benchmarks and up to 1.24x for needle-in-a-haystack retrieval tasks while maintaining above 99% baseline accuracy, with certain configurations even improving accuracy by focusing on the most relevant content, substantially outperforming existing sparse attention methods. The implementation is available at this https URL

07 Dec 2025


Meta AI developed Saber, a framework for zero-shot Reference-to-Video generation that leverages a masked training strategy on general video-text datasets, eliminating the need for specialized R2V data. It achieves superior identity consistency and overall performance on benchmarks like OpenS2V-Eval compared to methods trained on costly R2V datasets.

07 Dec 2025
An independent research team secured 1st place in the 2025 BEHAVIOR Challenge, achieving a 26% q-score by enhancing a Vision-Language-Action model (Pi0.5) with innovations like correlated noise for flow matching, "System 2" stage tracking, and practical inference-time heuristics. The approach demonstrated emergent recovery behaviors and addressed challenges in long-horizon, complex manipulation tasks.

07 Dec 2025
Researchers at Southern Methodist University systematically compared various memory encoding and injection methods for transformer-based world models, finding that State-Space Models (SSMs) combined with attention-based injection offer a scalable approach for enhancing long-term recall. This hybrid strategy significantly improved consistency over extended imagination horizons compared to a vanilla Vision Transformer, effectively mitigating perceptual drift.

08 Dec 2025
A two-stage self-supervised framework integrates the Joint-Embedding Predictive Architecture (JEPA) with Density Adaptive Attention Mechanisms (DAAM) to learn robust speech representations. This approach generates efficient, reversible discrete speech tokens at an ultra-low rate of 47.5 tokens/sec, designed for seamless integration with large language models.

08 Dec 2025
The Multi-view Pyramid Transformer (MVP) introduces a scalable architecture for efficient 3D reconstruction from numerous input images, leveraging a dual attention hierarchy and pyramidal feature aggregation. It processes up to 128 views in under one second on a single H100 GPU, achieving superior quality compared to prior single-pass models and often matching or exceeding optimization-based 3D Gaussian Splatting on various benchmarks.

07 Dec 2025
Researchers from Peking University and Huawei Technologies developed a principled framework for adapting pre-trained autoregressive (AR) models into Block-Diffusion Language Models (DLMs). The adapted 7B-class model, NBDIFF-7B, achieved state-of-the-art performance among diffusion LLMs, with a macro average of 64.3 for its base version and 78.8 for its instruct version across diverse benchmarks.

09 Dec 2025


Vision-language models (VLMs) have transformed multimodal reasoning, but feeding hundreds of visual patch tokens into LLMs incurs quadratic computational costs, straining memory and context windows. Traditional approaches face a trade-off: continuous compression dilutes high-level semantics such as object identities, while discrete quantization loses fine-grained details such as textures. We introduce HTC-VLM, a hybrid framework that disentangles semantics and appearance through dual channels, i.e., a continuous pathway for fine-grained details via ViT patches and a discrete pathway for symbolic anchors using MGVQ quantization projected to four tokens. These are fused into a 580-token hybrid sequence and compressed into a single voco token via a disentanglement attention mask and bottleneck, ensuring efficient and grounded representations. HTC-VLM achieves an average performance retention of 87.2 percent across seven benchmarks (GQA, VQAv2, MMBench, MME, POPE, SEED-Bench, ScienceQA-Image), outperforming the leading continuous baseline at 81.0 percent with a 580-to-1 compression ratio. Attention analyses show that the compressed token prioritizes the discrete anchor, validating its semantic guidance. Our work demonstrates that a minimalist hybrid design can resolve the efficiency-fidelity dilemma and advance scalable VLMs.

07 Dec 2025


Recent advances in Video Large Language Models (VLLMs) have achieved remarkable video understanding capabilities, yet face critical efficiency bottlenecks due to quadratic computational growth with lengthy visual token sequences of long videos. While existing keyframe sampling methods can improve temporal modeling efficiency, additional computational cost is introduced before feature encoding, and the binary frame selection paradigm is found suboptimal. Therefore, in this work, we propose Dynamic Token compression via LLM-guided Keyframe prior (DyToK), a training-free paradigm that enables dynamic token compression by harnessing VLLMs' inherent attention mechanisms. Our analysis reveals that VLLM attention layers naturally encoding query-conditioned keyframe priors, by which DyToK dynamically adjusts per-frame token retention ratios, prioritizing semantically rich frames while suppressing redundancies. Extensive experiments demonstrate that DyToK achieves state-of-the-art efficiency-accuracy tradeoffs. DyToK shows plug-and-play compatibility with existing compression methods, such as VisionZip and FastV, attaining 4.3x faster inference while preserving accuracy across multiple VLLMs, such as LLaVA-OneVision and Qwen2.5-VL. Code is available at this https URL .

09 Dec 2025
We present a central-peripheral vision-inspired framework (CVP), a simple yet effective multimodal model for spatial reasoning that draws inspiration from the two types of human visual fields -- central vision and peripheral vision. Existing approaches primarily rely on unstructured representations, such as point clouds, voxels, or patch features, and inject scene context implicitly via coordinate embeddings. However, this often results in limited spatial reasoning capabilities due to the lack of explicit, high-level structural understanding. To address this limitation, we introduce two complementary components into a Large Multimodal Model-based architecture: target-affinity token, analogous to central vision, that guides the model's attention toward query-relevant objects; and allocentric grid, akin to peripheral vision, that captures global scene context and spatial arrangements. These components work in tandem to enable structured, context-aware understanding of complex 3D environments. Experiments show that CVP achieves state-of-the-art performance across a range of 3D scene understanding benchmarks.

09 Dec 2025

GUI grounding, which translates natural language instructions into precise pixel coordinates, is essential for developing practical GUI agents. However, we observe that existing grounding models exhibit significant coordinate prediction instability, minor visual perturbations (e.g. cropping a few pixels) can drastically alter predictions, flipping results between correct and incorrect. This instability severely undermines model performance, especially for samples with high-resolution and small UI elements. To address this issue, we propose Multi-View Prediction (MVP), a training-free framework that enhances grounding performance through multi-view inference. Our key insight is that while single-view predictions may be unstable, aggregating predictions from multiple carefully cropped views can effectively distinguish correct coordinates from outliers. MVP comprises two components: (1) Attention-Guided View Proposal, which derives diverse views guided by instruction-to-image attention scores, and (2) Multi-Coordinates Clustering, which ensembles predictions by selecting the centroid of the densest spatial cluster. Extensive experiments demonstrate MVP's effectiveness across various models and benchmarks. Notably, on ScreenSpot-Pro, MVP boosts UI-TARS-1.5-7B to 56.1%, GTA1-7B to 61.7%, Qwen3VL-8B-Instruct to 65.3%, and Qwen3VL-32B-Instruct to 74.0%. The code is available at this https URL.

08 Dec 2025
Large Language Models (LLMs) have demonstrated remarkable performance in code intelligence tasks such as code generation, summarization, and translation. However, their reliance on linearized token sequences limits their ability to understand the structural semantics of programs. While prior studies have explored graphaugmented prompting and structure-aware pretraining, they either suffer from prompt length constraints or require task-specific architectural changes that are incompatible with large-scale instructionfollowing LLMs. To address these limitations, this paper proposes CGBridge, a novel plug-and-play method that enhances LLMs with Code Graph information through an external, trainable Bridge module. CGBridge first pre-trains a code graph encoder via selfsupervised learning on a large-scale dataset of 270K code graphs to learn structural code semantics. It then trains an external module to bridge the modality gap among code, graph, and text by aligning their semantics through cross-modal attention mechanisms. Finally, the bridge module generates structure-informed prompts, which are injected into a frozen LLM, and is fine-tuned for downstream code intelligence tasks. Experiments show that CGBridge achieves notable improvements over both the original model and the graphaugmented prompting method. Specifically, it yields a 16.19% and 9.12% relative gain in LLM-as-a-Judge on code summarization, and a 9.84% and 38.87% relative gain in Execution Accuracy on code translation. Moreover, CGBridge achieves over 4x faster inference than LoRA-tuned models, demonstrating both effectiveness and efficiency in structure-aware code understanding.

09 Dec 2025

Drag-based image editing aims to modify visual content followed by user-specified drag operations. Despite existing methods having made notable progress, they still fail to fully exploit the contextual information in the reference image, including fine-grained texture details, leading to edits with limited coherence and fidelity. To address this challenge, we introduce ContextDrag, a new paradigm for drag-based editing that leverages the strong contextual modeling capability of editing models, such as FLUX-Kontext. By incorporating VAE-encoded features from the reference image, ContextDrag can leverage rich contextual cues and preserve fine-grained details, without the need for finetuning or inversion. Specifically, ContextDrag introduced a novel Context-preserving Token Injection (CTI) that injects noise-free reference features into their correct destination locations via a Latent-space Reverse Mapping (LRM) algorithm. This strategy enables precise drag control while preserving consistency in both semantics and texture details. Second, ContextDrag adopts a novel Position-Consistent Attention (PCA), which positional re-encodes the reference tokens and applies overlap-aware masking to eliminate interference from irrelevant reference features. Extensive experiments on DragBench-SR and DragBench-DR demonstrate that our approach surpasses all existing SOTA methods. Code will be publicly available.

05 Dec 2025
Researchers at MPI-IS, University of Oxford, and ETH Zürich developed a post-training method that makes Transformer attention layers sparse by retaining only 0.2-0.3% of active attention edges. This approach maintains the original model's performance while drastically simplifying its internal computational graphs for enhanced mechanistic interpretability.

08 Dec 2025
Vision-language models (VLMs) frequently generate hallucinated content plausible but incorrect claims about image content. We propose a training-free self-correction framework enabling VLMs to iteratively refine responses through uncertainty-guided visual re-attention. Our method combines multidimensional uncertainty quantification (token entropy, attention dispersion, semantic consistency, claim confidence) with attention-guided cropping of under-explored regions. Operating entirely with frozen, pretrained VLMs, our framework requires no gradient updates. We validate our approach on the POPE and MMHAL BENCH benchmarks using the Qwen2.5-VL-7B [23] architecture. Experimental results demonstrate that our method reduces hallucination rates by 9.8 percentage points compared to the baseline, while improving object existence accuracy by 4.7 points on adversarial splits. Furthermore, qualitative analysis confirms that uncertainty-guided re-attention successfully grounds corrections in visual evidence where standard decoding fails. We validate our approach on Qwen2.5-VL-7B [23], with plans to extend validation across diverse architectures in future versions. We release our code and methodology to facilitate future research in trustworthy multimodal systems.
There are no more papers matching your filters at the moment.
