
09 Dec 2025




Wan-Move presents a framework for motion-controllable video generation that utilizes latent trajectory guidance to directly edit image condition features within a pre-trained image-to-video model. This method yields superior visual quality and precise motion adherence compared to state-of-the-art academic approaches and rivals commercial solutions, while also establishing MoveBench, a new comprehensive evaluation benchmark.

09 Dec 2025



Researchers from Google DeepMind, University College London, and the University of Oxford developed D4RT, a unified feedforward model for reconstructing dynamic 4D scenes, encompassing depth, spatio-temporal correspondence, and camera parameters, from video using a single, flexible querying interface. The model achieved state-of-the-art accuracy across various 4D reconstruction and tracking benchmarks, with 3D tracking throughput 18-300 times faster and pose estimation over 100 times faster than prior methods.

10 Dec 2025


The growing adoption of XR devices has fueled strong demand for high-quality stereo video, yet its production remains costly and artifact-prone. To address this challenge, we present StereoWorld, an end-to-end framework that repurposes a pretrained video generator for high-fidelity monocular-to-stereo video generation. Our framework jointly conditions the model on the monocular video input while explicitly supervising the generation with a geometry-aware regularization to ensure 3D structural fidelity. A spatio-temporal tiling scheme is further integrated to enable efficient, high-resolution synthesis. To enable large-scale training and evaluation, we curate a high-definition stereo video dataset containing over 11M frames aligned to natural human interpupillary distance (IPD). Extensive experiments demonstrate that StereoWorld substantially outperforms prior methods, generating stereo videos with superior visual fidelity and geometric consistency. The project webpage is available at this https URL.

07 Dec 2025



MeshSplatting generates connected, opaque, and colored triangle meshes from images using differentiable rendering, enabling direct integration of neurally reconstructed scenes into traditional 3D graphics pipelines. The method achieves a +0.69 dB PSNR improvement over MiLo on the Mip-NeRF360 dataset and trains 2x faster while requiring 2.5x less memory.

08 Dec 2025
The paper introduces Group Representational Position Encoding (GRAPE), a unified group-theoretic framework that re-conceptualizes and unifies existing positional encoding mechanisms like RoPE and ALiBi. It provides a principled design space for new encodings, demonstrating improved training stability and superior zero-shot performance in large language models.

08 Dec 2025

WorldReel develops a unified, feed-forward 4D generator that integrates geometry, motion, and appearance directly into a latent diffusion model, yielding videos with explicit 4D scene representations. The model achieves state-of-the-art photorealism and significantly improves geometric consistency and dynamic range, particularly for complex scenes with moving cameras.

09 Dec 2025



Researchers from Cornell University, Google, and UC Berkeley developed Selfi, a framework that refines pre-trained 3D Vision Foundation Model features through self-supervised geometric alignment. It achieves state-of-the-art pose-free novel view synthesis quality and robust camera pose estimation, often rivaling methods requiring ground-truth camera parameters.
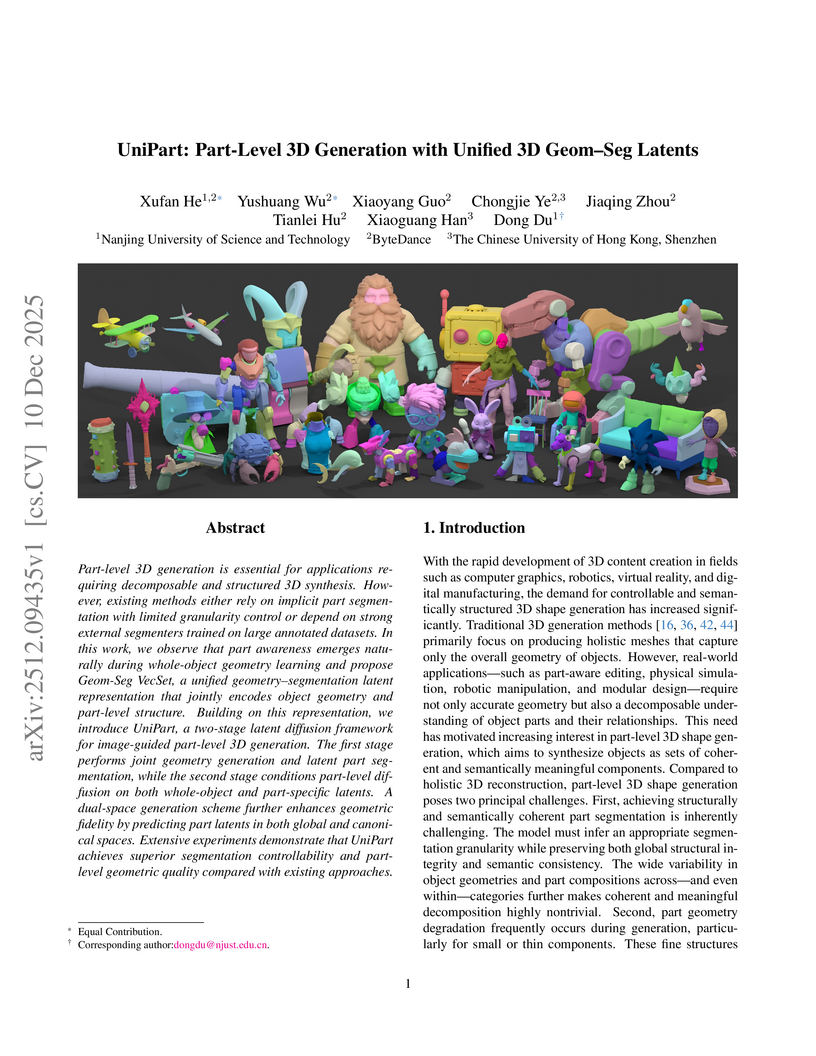
10 Dec 2025

Part-level 3D generation is essential for applications requiring decomposable and structured 3D synthesis. However, existing methods either rely on implicit part segmentation with limited granularity control or depend on strong external segmenters trained on large annotated datasets. In this work, we observe that part awareness emerges naturally during whole-object geometry learning and propose Geom-Seg VecSet, a unified geometry-segmentation latent representation that jointly encodes object geometry and part-level structure. Building on this representation, we introduce UniPart, a two-stage latent diffusion framework for image-guided part-level 3D generation. The first stage performs joint geometry generation and latent part segmentation, while the second stage conditions part-level diffusion on both whole-object and part-specific latents. A dual-space generation scheme further enhances geometric fidelity by predicting part latents in both global and canonical spaces. Extensive experiments demonstrate that UniPart achieves superior segmentation controllability and part-level geometric quality compared with existing approaches.

08 Dec 2025
Researchers developed a formalism to construct conformally invariant defects within Neural Network Field Theories (NN-FTs), enabling the realization of complex extended physical structures and offering new perspectives on probing data manifolds in machine learning. This framework specifies network architectures and parameter distributions to achieve symmetry breaking consistent with defect conformal field theories.
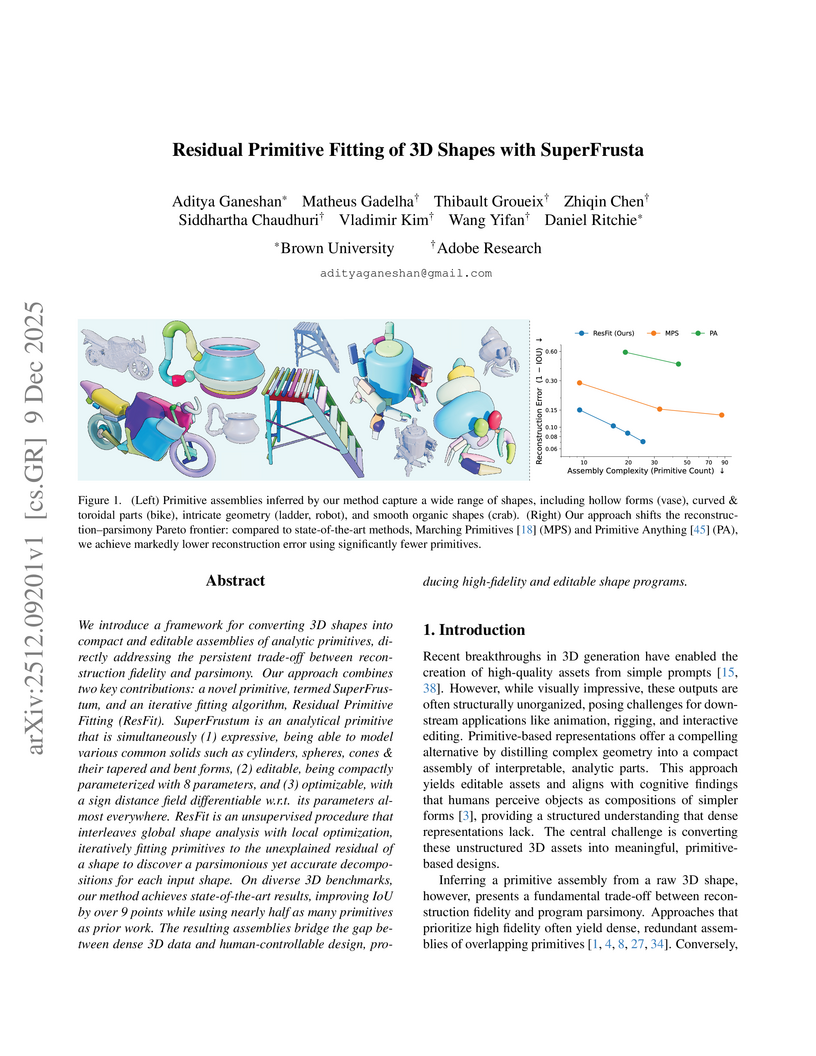
09 Dec 2025

We introduce a framework for converting 3D shapes into compact and editable assemblies of analytic primitives, directly addressing the persistent trade-off between reconstruction fidelity and parsimony. Our approach combines two key contributions: a novel primitive, termed SuperFrustum, and an iterative fiting algorithm, Residual Primitive Fitting (ResFit). SuperFrustum is an analytical primitive that is simultaneously (1) expressive, being able to model various common solids such as cylinders, spheres, cones & their tapered and bent forms, (2) editable, being compactly parameterized with 8 parameters, and (3) optimizable, with a sign distance field differentiable w.r.t. its parameters almost everywhere. ResFit is an unsupervised procedure that interleaves global shape analysis with local optimization, iteratively fitting primitives to the unexplained residual of a shape to discover a parsimonious yet accurate decompositions for each input shape. On diverse 3D benchmarks, our method achieves state-of-the-art results, improving IoU by over 9 points while using nearly half as many primitives as prior work. The resulting assemblies bridge the gap between dense 3D data and human-controllable design, producing high-fidelity and editable shape programs.

09 Dec 2025
Recent progress in text-to-video generation has achieved remarkable realism, yet fine-grained control over camera motion and orientation remains elusive. Existing approaches typically encode camera trajectories through relative or ambiguous representations, limiting explicit geometric control. We introduce GimbalDiffusion, a framework that enables camera control grounded in physical-world coordinates, using gravity as a global reference. Instead of describing motion relative to previous frames, our method defines camera trajectories in an absolute coordinate system, allowing precise and interpretable control over camera parameters without requiring an initial reference frame. We leverage panoramic 360-degree videos to construct a wide variety of camera trajectories, well beyond the predominantly straight, forward-facing trajectories seen in conventional video data. To further enhance camera guidance, we introduce null-pitch conditioning, an annotation strategy that reduces the model's reliance on text content when conflicting with camera specifications (e.g., generating grass while the camera points towards the sky). Finally, we establish a benchmark for camera-aware video generation by rebalancing SpatialVID-HQ for comprehensive evaluation under wide camera pitch variation. Together, these contributions advance the controllability and robustness of text-to-video models, enabling precise, gravity-aligned camera manipulation within generative frameworks.

09 Dec 2025
We present a central-peripheral vision-inspired framework (CVP), a simple yet effective multimodal model for spatial reasoning that draws inspiration from the two types of human visual fields -- central vision and peripheral vision. Existing approaches primarily rely on unstructured representations, such as point clouds, voxels, or patch features, and inject scene context implicitly via coordinate embeddings. However, this often results in limited spatial reasoning capabilities due to the lack of explicit, high-level structural understanding. To address this limitation, we introduce two complementary components into a Large Multimodal Model-based architecture: target-affinity token, analogous to central vision, that guides the model's attention toward query-relevant objects; and allocentric grid, akin to peripheral vision, that captures global scene context and spatial arrangements. These components work in tandem to enable structured, context-aware understanding of complex 3D environments. Experiments show that CVP achieves state-of-the-art performance across a range of 3D scene understanding benchmarks.

08 Dec 2025
This research introduces "Concept Cones" as a geometric framework to unify supervised Concept Bottleneck Models (CBMs) and unsupervised Sparse Autoencoders (SAEs). The framework enables quantitative evaluation of how well SAE-discovered concepts align with human-interpretable CBM concepts, offering actionable insights for designing interpretable AI models.

09 Dec 2025


Recent research in Vision-Language Models (VLMs) has significantly advanced our capabilities in cross-modal reasoning. However, existing methods suffer from performance degradation with domain changes or require substantial computational resources for fine-tuning in new domains. To address this issue, we develop a new adaptation method for large vision-language models, called \textit{Training-free Dual Hyperbolic Adapters} (T-DHA). We characterize the vision-language relationship between semantic concepts, which typically has a hierarchical tree structure, in the hyperbolic space instead of the traditional Euclidean space. Hyperbolic spaces exhibit exponential volume growth with radius, unlike the polynomial growth in Euclidean space. We find that this unique property is particularly effective for embedding hierarchical data structures using the Poincaré ball model, achieving significantly improved representation and discrimination power. Coupled with negative learning, it provides more accurate and robust classifications with fewer feature dimensions. Our extensive experimental results on various datasets demonstrate that the T-DHA method significantly outperforms existing state-of-the-art methods in few-shot image recognition and domain generalization tasks.
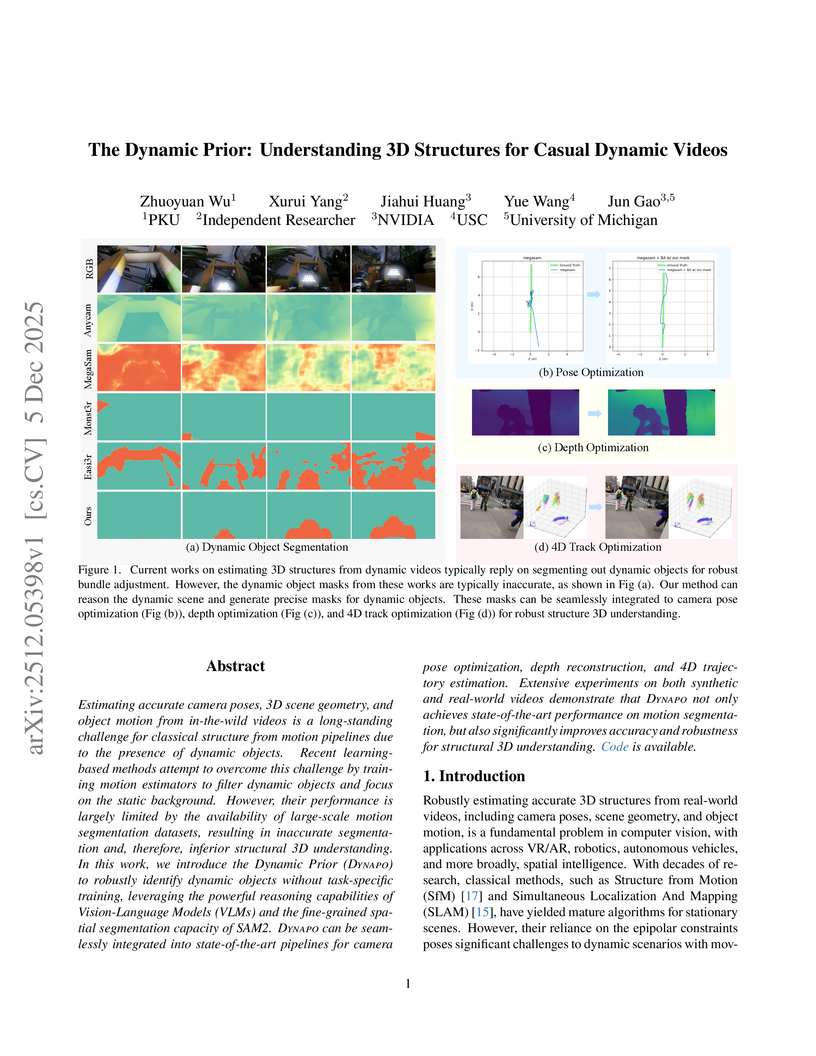
05 Dec 2025




Researchers at Peking University, NVIDIA, USC, and the University of Michigan developed Dynapo, a training-free framework that leverages large vision-language models and advanced segmentation models to robustly identify dynamic objects in casual videos. This approach significantly enhances the accuracy of camera pose estimation, depth reconstruction, and 4D trajectory optimization in dynamic scenes.

08 Dec 2025

Lang3D-XL introduces a method for embedding language features into 3D Gaussian Splatting models of large-scale "in-the-wild" scenes. It enables interactive, text-based semantic understanding, achieving comparable semantic segmentation performance to HaLo-NeRF while accelerating inference speed by orders of magnitude (under 0.1 seconds per query vs. two hours) and outperforming other feature-based methods with an mAP of 0.59 on the HolyScenes dataset.

07 Dec 2025
OXTAL introduces an all-atom diffusion transformer model that generates organic crystal structures directly from a 2D molecular graph, learning both molecular conformations and periodic packing from over 600,000 experimental structures. The method demonstrates competitive accuracy against traditional DFT-based approaches in CCDC blind tests while offering significantly reduced computational inference costs.

08 Dec 2025
Background: The deployment of personalized Large Language Models (LLMs) is currently constrained by the stability-plasticity dilemma. Prevailing alignment methods, such as Supervised Fine-Tuning (SFT), rely on stochastic weight updates that often incur an "alignment tax" -- degrading general reasoning capabilities.
Methods: We propose the Soul Engine, a framework based on the Linear Representation Hypothesis, which posits that personality traits exist as orthogonal linear subspaces. We introduce SoulBench, a dataset constructed via dynamic contextual sampling. Using a dual-head architecture on a frozen Qwen-2.5 base, we extract disentangled personality vectors without modifying the backbone weights.
Results: Our experiments demonstrate three breakthroughs. First, High-Precision Profiling: The model achieves a Mean Squared Error (MSE) of 0.011 against psychological ground truth. Second, Geometric Orthogonality: T-SNE visualization confirms that personality manifolds are distinct and continuous, allowing for "Zero-Shot Personality Injection" that maintains original model intelligence. Third, Deterministic Steering: We achieve robust control over behavior via vector arithmetic, validated through extensive ablation studies.
Conclusion: This work challenges the necessity of fine-tuning for personalization. By transitioning from probabilistic prompting to deterministic latent intervention, we provide a mathematically rigorous foundation for safe, controllable AI personalization.

10 Dec 2025

Modeling relightable and animatable human avatars from monocular video is a long-standing and challenging task. Recently, Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) methods have been employed to reconstruct the avatars. However, they often produce unsatisfactory photo-realistic results because of insufficient geometrical details related to body motion, such as clothing wrinkles. In this paper, we propose a 3DGS-based human avatar modeling framework, termed as Relightable and Dynamic Gaussian Avatar (RnD-Avatar), that presents accurate pose-variant deformation for high-fidelity geometrical details. To achieve this, we introduce dynamic skinning weights that define the human avatar's articulation based on pose while also learning additional deformations induced by body motion. We also introduce a novel regularization to capture fine geometric details under sparse visual cues. Furthermore, we present a new multi-view dataset with varied lighting conditions to evaluate relight. Our framework enables realistic rendering of novel poses and views while supporting photo-realistic lighting effects under arbitrary lighting conditions. Our method achieves state-of-the-art performance in novel view synthesis, novel pose rendering, and relighting.

04 Dec 2025



LIGHT-X, developed by researchers from NTU, BAAI, and other institutions, introduces a generative framework for 4D videos that enables simultaneous control of camera trajectory and illumination from monocular inputs. The system achieves superior relighting quality and temporal consistency, outperforming combined baseline methods with a FID of 101.06 for joint control and 83.65 for video relighting.
There are no more papers matching your filters at the moment.
