06 Dec 2025
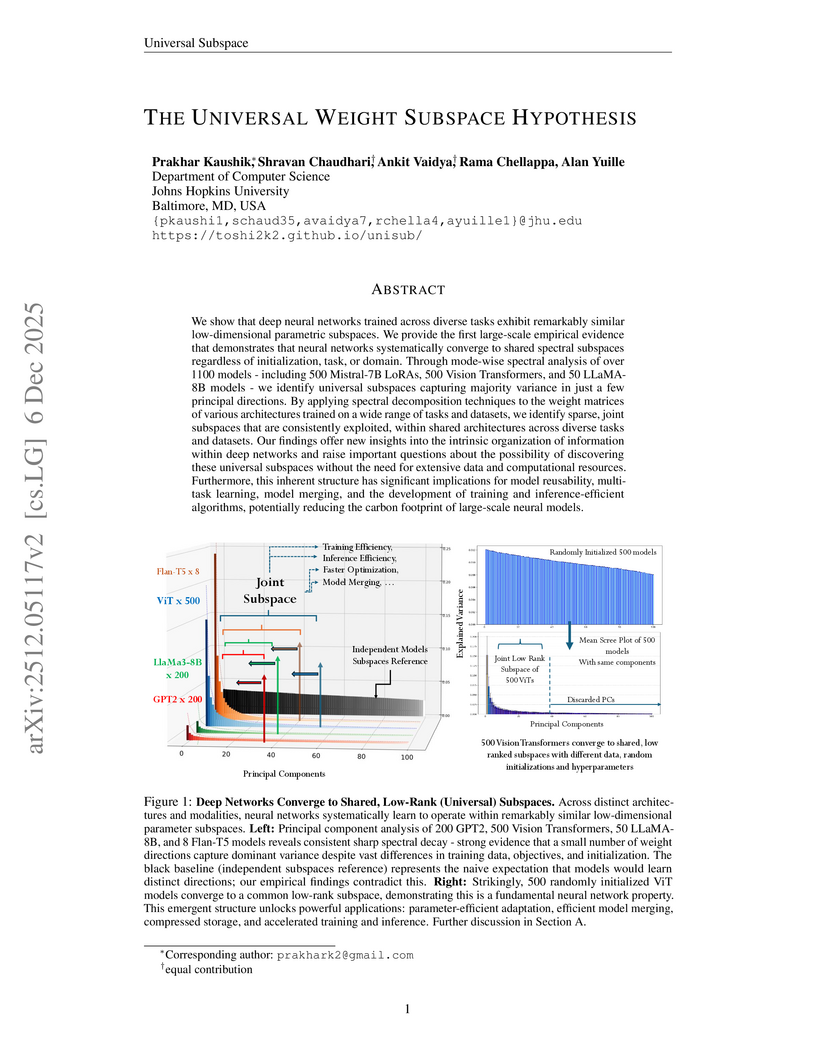
This paper presents the Universal Weight Subspace Hypothesis, demonstrating empirically that deep neural networks trained across diverse tasks and modalities converge to shared low-dimensional parametric subspaces. This convergence enables significant memory savings, such as up to 100x for Vision Transformers and LLaMA models, and 19x for LoRA adapters, while preserving model performance and enhancing efficiency in model merging and adaptation.

09 Dec 2025




Wan-Move presents a framework for motion-controllable video generation that utilizes latent trajectory guidance to directly edit image condition features within a pre-trained image-to-video model. This method yields superior visual quality and precise motion adherence compared to state-of-the-art academic approaches and rivals commercial solutions, while also establishing MoveBench, a new comprehensive evaluation benchmark.

08 Dec 2025
Researchers from University of Wisconsin-Madison, UCLA, and Adobe Research introduce a computational framework for "relational visual similarity," which identifies image commonalities based on abstract logic rather than surface features. Their `relsim` model, trained on a novel dataset of images paired with anonymous group-derived captions, aligns significantly with human perception of relational similarity and outperforms existing attribute-based metrics in retrieval tasks.

09 Dec 2025
Recent advances in diffusion transformers have empowered video generation models to generate high-quality video clips from texts or images. However, world models with the ability to predict long-horizon futures from past observations and actions remain underexplored, especially for general-purpose scenarios and various forms of actions. To bridge this gap, we introduce Astra, an interactive general world model that generates real-world futures for diverse scenarios (e.g., autonomous driving, robot grasping) with precise action interactions (e.g., camera motion, robot action). We propose an autoregressive denoising architecture and use temporal causal attention to aggregate past observations and support streaming outputs. We use a noise-augmented history memory to avoid over-reliance on past frames to balance responsiveness with temporal coherence. For precise action control, we introduce an action-aware adapter that directly injects action signals into the denoising process. We further develop a mixture of action experts that dynamically route heterogeneous action modalities, enhancing versatility across diverse real-world tasks such as exploration, manipulation, and camera control. Astra achieves interactive, consistent, and general long-term video prediction and supports various forms of interactions. Experiments across multiple datasets demonstrate the improvements of Astra in fidelity, long-range prediction, and action alignment over existing state-of-the-art world models.

08 Dec 2025

Apple researchers introduced FAE (Feature Auto-Encoder), a minimalist framework using a single attention layer and a double-decoder architecture to adapt high-dimensional self-supervised visual features into compact, generation-friendly latent spaces. FAE achieves competitive FID scores on ImageNet (1.29) and MS-COCO (6.90) for image generation while preserving semantic understanding capabilities of the original pre-trained encoders.

08 Dec 2025
Meituan's LongCat-Image introduces an open-source, bilingual foundation model for image generation and editing, achieving state-of-the-art performance with a compact 6B parameter architecture. The model establishes new industry standards for Chinese character rendering, reaching 90.7% accuracy on a custom benchmark, and demonstrates robust image editing capabilities, often outperforming larger models.

07 Dec 2025
Researchers from Microsoft Research Asia, Xi'an Jiaotong University, and Fudan University developed VideoVLA, a robot manipulator that repurposes large pre-trained video generation models. This system jointly predicts future video states and corresponding actions, achieving enhanced generalization capabilities for novel objects and skills in both simulated and real-world environments.

08 Dec 2025


A new framework, Distribution Matching Variational AutoEncoder (DMVAE), explicitly aligns a VAE's aggregate latent distribution with a pre-defined reference distribution using score-based matching. The approach achieves a state-of-the-art gFID of 1.82 on ImageNet 256x256, demonstrating superior training efficiency for downstream generative models, particularly when utilizing Self-Supervised Learning features as the reference.

05 Dec 2025

The EditThinker framework enhances instruction-following in any image editor by introducing an iterative reasoning process. It leverages a Multimodal Large Language Model to critique, reflect, and refine editing instructions, leading to consistent performance gains across diverse benchmarks and excelling in complex reasoning tasks.

07 Dec 2025




MeshSplatting generates connected, opaque, and colored triangle meshes from images using differentiable rendering, enabling direct integration of neurally reconstructed scenes into traditional 3D graphics pipelines. The method achieves a +0.69 dB PSNR improvement over MiLo on the Mip-NeRF360 dataset and trains 2x faster while requiring 2.5x less memory.
09 Dec 2025

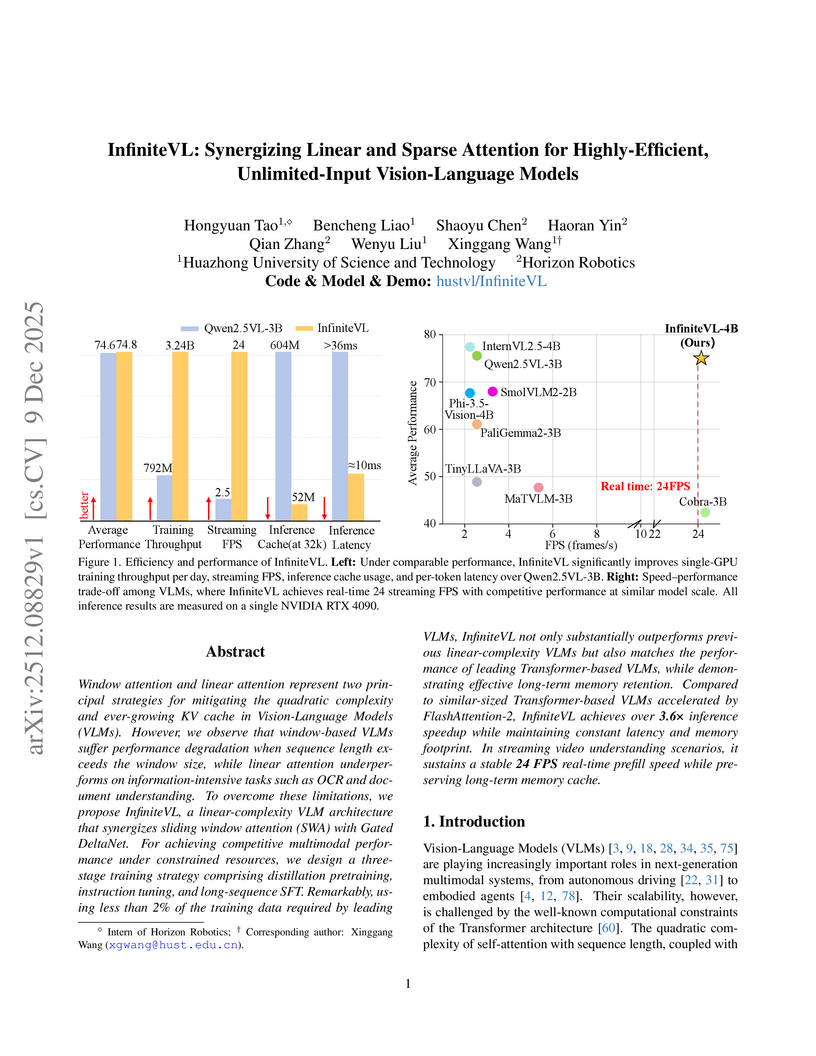
Window attention and linear attention represent two principal strategies for mitigating the quadratic complexity and ever-growing KV cache in Vision-Language Models (VLMs). However, we observe that window-based VLMs suffer performance degradation when sequence length exceeds the window size, while linear attention underperforms on information-intensive tasks such as OCR and document understanding. To overcome these limitations, we propose InfiniteVL, a linear-complexity VLM architecture that synergizes sliding window attention (SWA) with Gated DeltaNet. For achieving competitive multimodal performance under constrained resources, we design a three-stage training strategy comprising distillation pretraining, instruction tuning, and long-sequence SFT. Remarkably, using less than 2\% of the training data required by leading VLMs, InfiniteVL not only substantially outperforms previous linear-complexity VLMs but also matches the performance of leading Transformer-based VLMs, while demonstrating effective long-term memory retention. Compared to similar-sized Transformer-based VLMs accelerated by FlashAttention-2, InfiniteVL achieves over 3.6\times inference speedup while maintaining constant latency and memory footprint. In streaming video understanding scenarios, it sustains a stable 24 FPS real-time prefill speed while preserving long-term memory cache. Code and models are available at this https URL.

08 Dec 2025


WorldReel develops a unified, feed-forward 4D generator that integrates geometry, motion, and appearance directly into a latent diffusion model, yielding videos with explicit 4D scene representations. The model achieves state-of-the-art photorealism and significantly improves geometric consistency and dynamic range, particularly for complex scenes with moving cameras.

09 Dec 2025
Reinforcement learning (RL) post-training is crucial for aligning generative models with human preferences, but its prohibitive computational cost remains a major barrier to widespread adoption. We introduce \textbf{TreeGRPO}, a novel RL framework that dramatically improves training efficiency by recasting the denoising process as a search tree. From shared initial noise samples, TreeGRPO strategically branches to generate multiple candidate trajectories while efficiently reusing their common prefixes. This tree-structured approach delivers three key advantages: (1) \emph{High sample efficiency}, achieving better performance under same training samples (2) \emph{Fine-grained credit assignment} via reward backpropagation that computes step-specific advantages, overcoming the uniform credit assignment limitation of trajectory-based methods, and (3) \emph{Amortized computation} where multi-child branching enables multiple policy updates per forward pass. Extensive experiments on both diffusion and flow-based models demonstrate that TreeGRPO achieves \textbf{2.4 faster training} while establishing a superior Pareto frontier in the efficiency-reward trade-off space. Our method consistently outperforms GRPO baselines across multiple benchmarks and reward models, providing a scalable and effective pathway for RL-based visual generative model alignment. The project website is available at this http URL.

08 Dec 2025
DiffusionDriveV2 integrates reinforcement learning with an anchor-based truncated diffusion model to produce a diverse range of consistently high-quality trajectories for end-to-end autonomous driving. This approach achieves state-of-the-art performance on NAVSIM v1 and v2 benchmarks, with a PDMS of 91.2 on v1 and an EPDMS of 85.5 on v2.

09 Dec 2025



Novel View Synthesis (NVS) has traditionally relied on models with explicit 3D inductive biases combined with known camera parameters from Structure-from-Motion (SfM) beforehand. Recent vision foundation models like VGGT take an orthogonal approach -- 3D knowledge is gained implicitly through training data and loss objectives, enabling feed-forward prediction of both camera parameters and 3D representations directly from a set of uncalibrated images. While flexible, VGGT features lack explicit multi-view geometric consistency, and we find that improving such 3D feature consistency benefits both NVS and pose estimation tasks. We introduce Selfi, a self-improving 3D reconstruction pipeline via feature alignment, transforming a VGGT backbone into a high-fidelity 3D reconstruction engine by leveraging its own outputs as pseudo-ground-truth. Specifically, we train a lightweight feature adapter using a reprojection-based consistency loss, which distills VGGT outputs into a new geometrically-aligned feature space that captures spatial proximity in 3D. This enables state-of-the-art performance in both NVS and camera pose estimation, demonstrating that feature alignment is a highly beneficial step for downstream 3D reasoning.

08 Dec 2025

Researchers from the University of Technology Sydney and Zhejiang University developed VideoCoF, a unified video editing framework that introduces a "Chain of Frames" approach for explicit visual reasoning. This method achieves mask-free, fine-grained edits, demonstrating a 15.14% improvement in instruction following and an 18.6% higher success ratio on their VideoCoF-Bench, while also providing robust length extrapolation.

08 Dec 2025
Researchers at National Yang Ming Chiao Tung University developed Voxify3D, a differentiable framework that converts 3D meshes into high-quality, stylized voxel art. The method integrates orthographic pixel art supervision and palette-constrained differentiable quantization to preserve semantics under extreme abstraction, achieving superior qualitative results and high user preference for abstract detail and visual appeal.

08 Dec 2025

UnityVideo establishes a unified multi-modal and multi-task learning framework for video generation, enhancing a model's understanding of the physical world by jointly training on diverse visual sub-modalities like depth, optical flow, and segmentation. The framework achieves superior quantitative and qualitative performance across text-to-video generation, controllable generation, and modality estimation tasks.

09 Dec 2025


Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks. We refer to the project webpage for animated results: this https URL.

09 Dec 2025
Human Mesh Recovery (HMR) aims to reconstruct 3D human pose and shape from 2D observations and is fundamental to human-centric understanding in real-world scenarios. While recent image-based HMR methods such as SAM 3D Body achieve strong robustness on in-the-wild images, they rely on per-frame inference when applied to videos, leading to temporal inconsistency and degraded performance under occlusions. We address these issues without extra training by leveraging the inherent human continuity in videos. We propose SAM-Body4D, a training-free framework for temporally consistent and occlusion-robust HMR from videos. We first generate identity-consistent masklets using a promptable video segmentation model, then refine them with an Occlusion-Aware module to recover missing regions. The refined masklets guide SAM 3D Body to produce consistent full-body mesh trajectories, while a padding-based parallel strategy enables efficient multi-human inference. Experimental results demonstrate that SAM-Body4D achieves improved temporal stability and robustness in challenging in-the-wild videos, without any retraining. Our code and demo are available at: this https URL.
There are no more papers matching your filters at the moment.
