20 May 2025




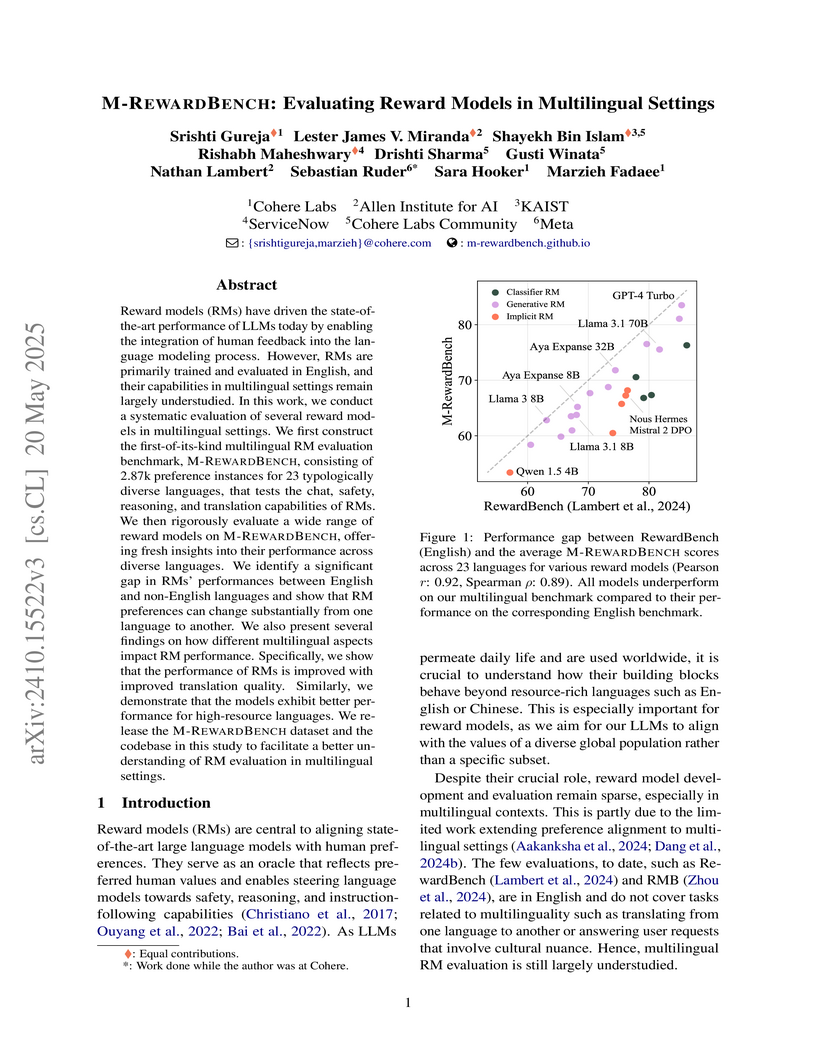
Researchers introduce M-REWARDBENCH, the first multilingual executable benchmark for evaluating reward models (RMs) across 23 diverse languages, revealing a significant performance gap for RMs in non-English settings. The study found that generative RMs, utilizing LLMs as judges, demonstrate stronger multilingual generalization compared to classifier and implicit RMs.
There are no more papers matching your filters at the moment.
