06 Dec 2025
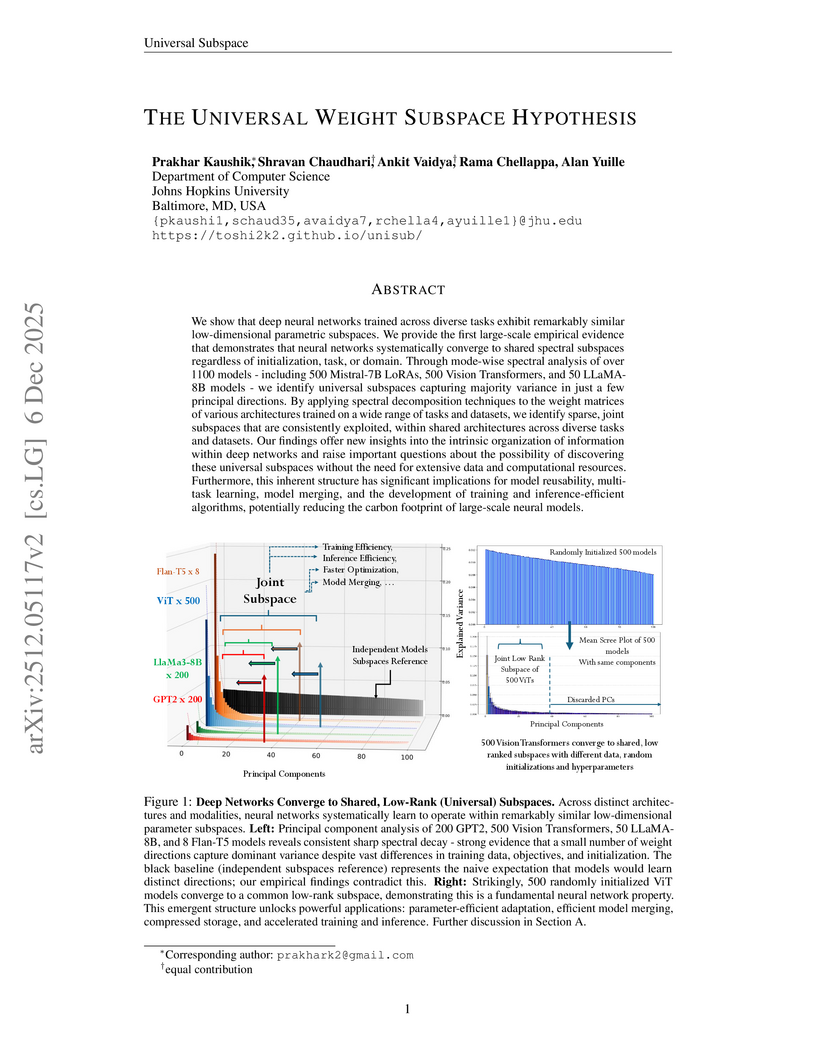
This paper presents the Universal Weight Subspace Hypothesis, demonstrating empirically that deep neural networks trained across diverse tasks and modalities converge to shared low-dimensional parametric subspaces. This convergence enables significant memory savings, such as up to 100x for Vision Transformers and LLaMA models, and 19x for LoRA adapters, while preserving model performance and enhancing efficiency in model merging and adaptation.

08 Dec 2025
Researchers from University of Wisconsin-Madison, UCLA, and Adobe Research introduce a computational framework for "relational visual similarity," which identifies image commonalities based on abstract logic rather than surface features. Their `relsim` model, trained on a novel dataset of images paired with anonymous group-derived captions, aligns significantly with human perception of relational similarity and outperforms existing attribute-based metrics in retrieval tasks.

09 Dec 2025

Recent advances in diffusion transformers have empowered video generation models to generate high-quality video clips from texts or images. However, world models with the ability to predict long-horizon futures from past observations and actions remain underexplored, especially for general-purpose scenarios and various forms of actions. To bridge this gap, we introduce Astra, an interactive general world model that generates real-world futures for diverse scenarios (e.g., autonomous driving, robot grasping) with precise action interactions (e.g., camera motion, robot action). We propose an autoregressive denoising architecture and use temporal causal attention to aggregate past observations and support streaming outputs. We use a noise-augmented history memory to avoid over-reliance on past frames to balance responsiveness with temporal coherence. For precise action control, we introduce an action-aware adapter that directly injects action signals into the denoising process. We further develop a mixture of action experts that dynamically route heterogeneous action modalities, enhancing versatility across diverse real-world tasks such as exploration, manipulation, and camera control. Astra achieves interactive, consistent, and general long-term video prediction and supports various forms of interactions. Experiments across multiple datasets demonstrate the improvements of Astra in fidelity, long-range prediction, and action alignment over existing state-of-the-art world models.

08 Dec 2025

Apple researchers introduced FAE (Feature Auto-Encoder), a minimalist framework using a single attention layer and a double-decoder architecture to adapt high-dimensional self-supervised visual features into compact, generation-friendly latent spaces. FAE achieves competitive FID scores on ImageNet (1.29) and MS-COCO (6.90) for image generation while preserving semantic understanding capabilities of the original pre-trained encoders.

07 Dec 2025
WisPaper introduces an AI-powered scholar search engine that unifies academic literature discovery, management, and continuous tracking within a single platform. Its core Deep Search component, powered by the WisModel agent, achieved 94.8% semantic similarity in query understanding and 93.70% overall accuracy in paper-criteria matching, demonstrating superior performance over leading commercial LLMs, especially in nuanced judgments.

08 Dec 2025

The DEMOCRITUS system establishes a new framework for building large causal models (LCMs) by extracting and structuring textual knowledge from Large Language Models (LLMs) across diverse domains. It leverages a Geometric Transformer to embed and organize vast causal claims into coherent, navigable manifolds, which, unlike raw LLM outputs, exhibit global causal coherence and interpretable local structures.

07 Dec 2025
Researchers from Microsoft Research Asia, Xi'an Jiaotong University, and Fudan University developed VideoVLA, a robot manipulator that repurposes large pre-trained video generation models. This system jointly predicts future video states and corresponding actions, achieving enhanced generalization capabilities for novel objects and skills in both simulated and real-world environments.

07 Dec 2025
Researchers at ShanghaiTech University and Ant Group developed FlashMHF, an efficient multi-head Feed-Forward Network (FFN) for Transformer architectures that integrates a multi-head design with an I/O-aware fused kernel. This approach consistently improves language modeling perplexity and downstream task accuracy while reducing peak memory usage by 3-5x and accelerating inference up to 1.08x compared to standard FFNs.

08 Dec 2025
The paper introduces Group Representational Position Encoding (GRAPE), a unified group-theoretic framework that re-conceptualizes and unifies existing positional encoding mechanisms like RoPE and ALiBi. It provides a principled design space for new encodings, demonstrating improved training stability and superior zero-shot performance in large language models.

09 Dec 2025
Astribot's Lumo-1 introduces a generalist Vision-Language-Action model that explicitly unifies robot reasoning with physical control, demonstrating superior performance in generalizable pick-and-place, out-of-distribution scenarios, and complex long-horizon dexterous tasks on a bimanual mobile manipulator. The system shows improved embodied reasoning and robustness, partly through a novel spatial action tokenizer and multi-stage training.
09 Dec 2025

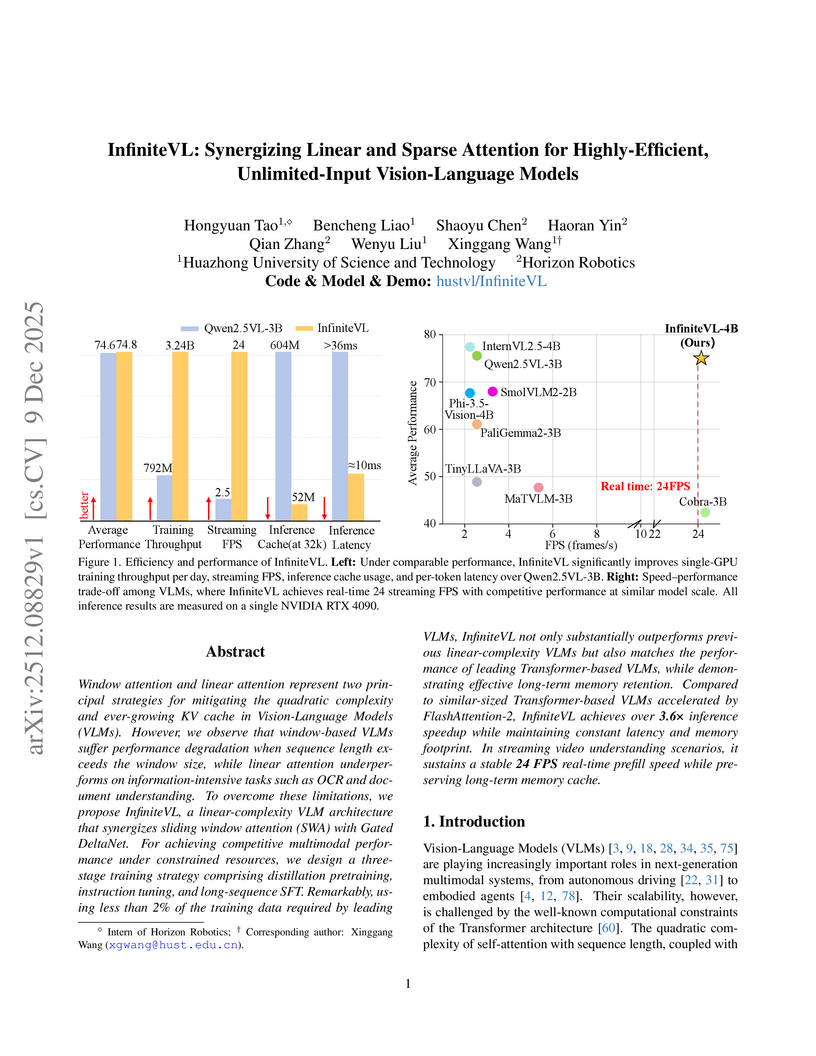
Window attention and linear attention represent two principal strategies for mitigating the quadratic complexity and ever-growing KV cache in Vision-Language Models (VLMs). However, we observe that window-based VLMs suffer performance degradation when sequence length exceeds the window size, while linear attention underperforms on information-intensive tasks such as OCR and document understanding. To overcome these limitations, we propose InfiniteVL, a linear-complexity VLM architecture that synergizes sliding window attention (SWA) with Gated DeltaNet. For achieving competitive multimodal performance under constrained resources, we design a three-stage training strategy comprising distillation pretraining, instruction tuning, and long-sequence SFT. Remarkably, using less than 2\% of the training data required by leading VLMs, InfiniteVL not only substantially outperforms previous linear-complexity VLMs but also matches the performance of leading Transformer-based VLMs, while demonstrating effective long-term memory retention. Compared to similar-sized Transformer-based VLMs accelerated by FlashAttention-2, InfiniteVL achieves over 3.6\times inference speedup while maintaining constant latency and memory footprint. In streaming video understanding scenarios, it sustains a stable 24 FPS real-time prefill speed while preserving long-term memory cache. Code and models are available at this https URL.

08 Dec 2025
AI systems can be trained to conceal their true capabilities during evaluations, a phenomenon termed "sandbagging," which poses a risk to safety assessments. Research by UK AISI, FAR.AI, and Anthropic demonstrated that black-box detection methods failed against such strategically underperforming models, although one-shot fine-tuning proved effective for eliciting hidden capabilities.
04 Dec 2025

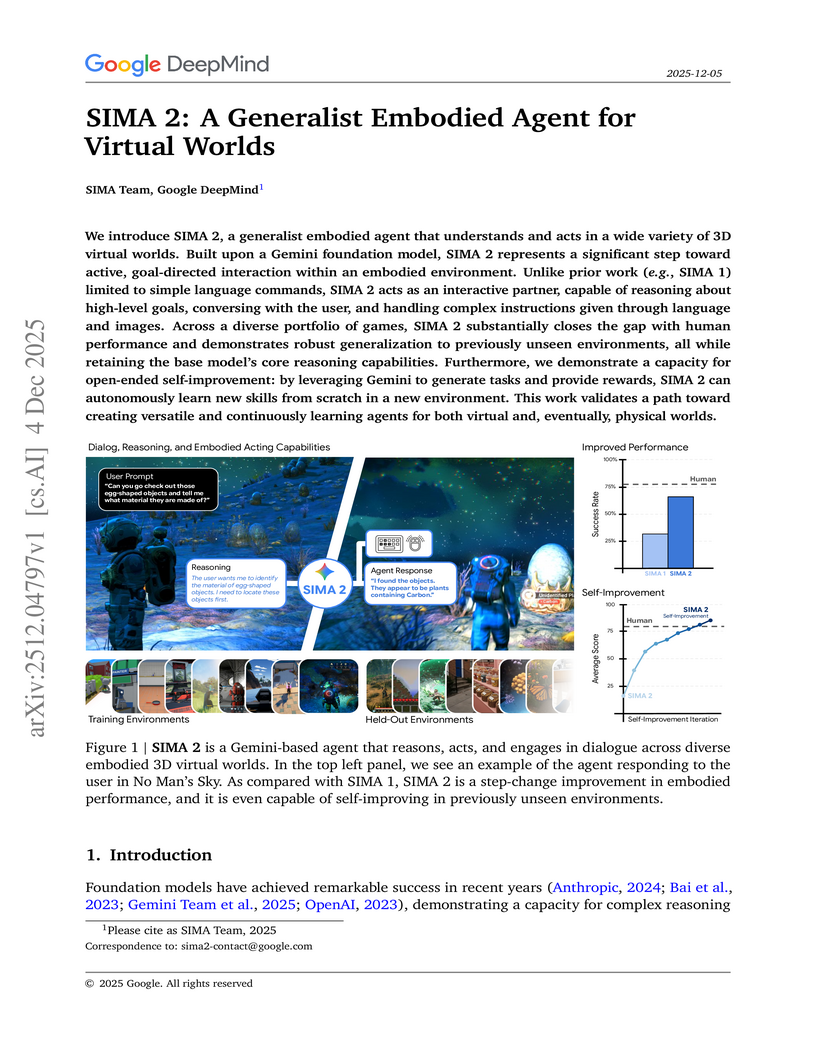
Google DeepMind developed SIMA 2, a generalist embodied agent powered by a Gemini Flash-Lite model, capable of understanding and acting in diverse 3D virtual worlds. It substantially doubles the task success rate of its predecessor SIMA 1, generalizes to unseen commercial games and photorealistic environments, and demonstrates autonomous skill acquisition through a Gemini-based self-improvement mechanism.

08 Dec 2025


WorldReel develops a unified, feed-forward 4D generator that integrates geometry, motion, and appearance directly into a latent diffusion model, yielding videos with explicit 4D scene representations. The model achieves state-of-the-art photorealism and significantly improves geometric consistency and dynamic range, particularly for complex scenes with moving cameras.

09 Dec 2025
Reinforcement learning (RL) post-training is crucial for aligning generative models with human preferences, but its prohibitive computational cost remains a major barrier to widespread adoption. We introduce \textbf{TreeGRPO}, a novel RL framework that dramatically improves training efficiency by recasting the denoising process as a search tree. From shared initial noise samples, TreeGRPO strategically branches to generate multiple candidate trajectories while efficiently reusing their common prefixes. This tree-structured approach delivers three key advantages: (1) \emph{High sample efficiency}, achieving better performance under same training samples (2) \emph{Fine-grained credit assignment} via reward backpropagation that computes step-specific advantages, overcoming the uniform credit assignment limitation of trajectory-based methods, and (3) \emph{Amortized computation} where multi-child branching enables multiple policy updates per forward pass. Extensive experiments on both diffusion and flow-based models demonstrate that TreeGRPO achieves \textbf{2.4 faster training} while establishing a superior Pareto frontier in the efficiency-reward trade-off space. Our method consistently outperforms GRPO baselines across multiple benchmarks and reward models, providing a scalable and effective pathway for RL-based visual generative model alignment. The project website is available at this http URL.

09 Dec 2025
Researchers at Physical Intelligence optimized Real-Time Chunking for Vision-Language-Action models by introducing training-time action conditioning, moving computationally intensive prefix conditioning from inference to training. This approach maintained task performance and execution speed, notably reducing latency from 135ms to 108ms and improving robustness at higher inference delays compared to prior methods.
08 Dec 2025
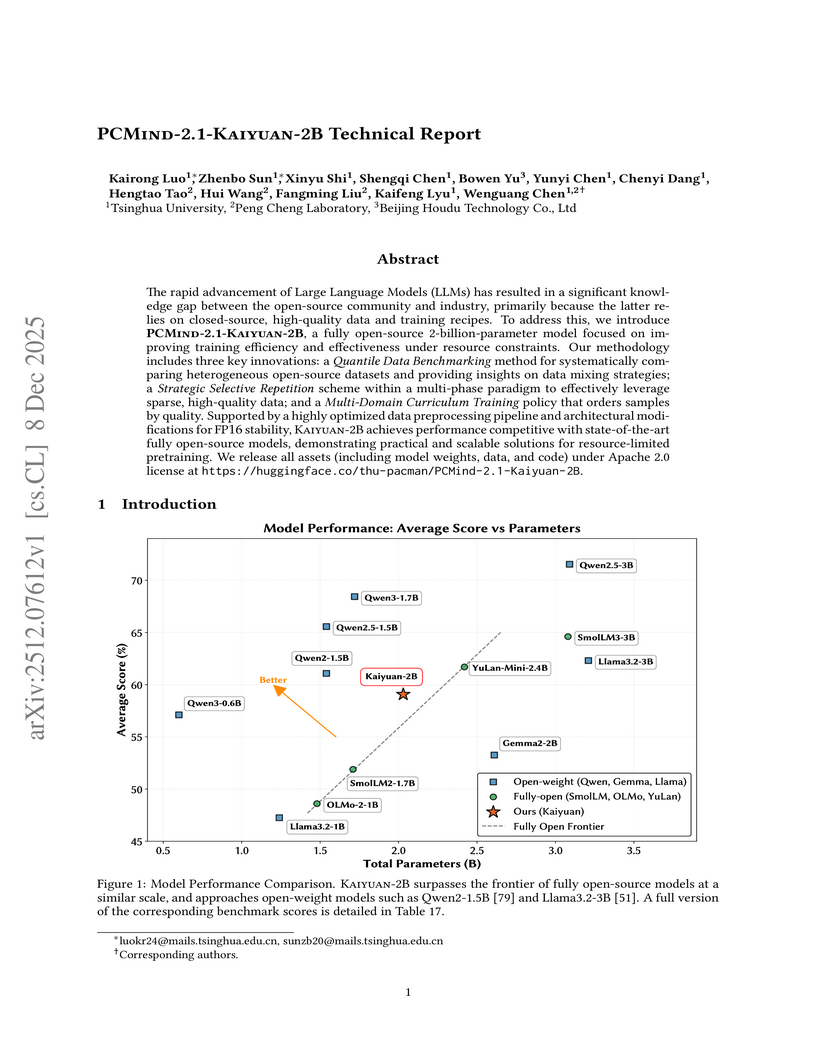
Researchers from Tsinghua University and Peng Cheng Laboratory developed PCMind-2.1-Kaiyuan-2B, a fully open-source 2-billion-parameter language model. It achieves competitive performance in Chinese language understanding, mathematical reasoning, and code generation by employing a multi-phase curriculum training with strategic data repetition and architectural modifications for FP16 stability, attaining an overall average score of 59.07% across evaluated benchmarks and outperforming several existing open-source models in its class.

09 Dec 2025
The paper empirically investigates the performance of multi-agent LLM systems across diverse agentic tasks and architectures, revealing that benefits are highly contingent on task structure rather than universal. It establishes a quantitative scaling principle, achieving 87% accuracy in predicting optimal agent architectures for unseen tasks based on model capability, task properties, and measured coordination dynamics.

09 Dec 2025

RETAIN, developed at UC Berkeley, introduces a parameter merging strategy for generalist robot policies, interpolating pre-trained and finetuned weights to enable robust adaptation to new tasks. This approach enhances out-of-distribution generalization by approximately 40% on real-world robotic tasks while preserving the policy's existing broad capabilities in low-data scenarios.
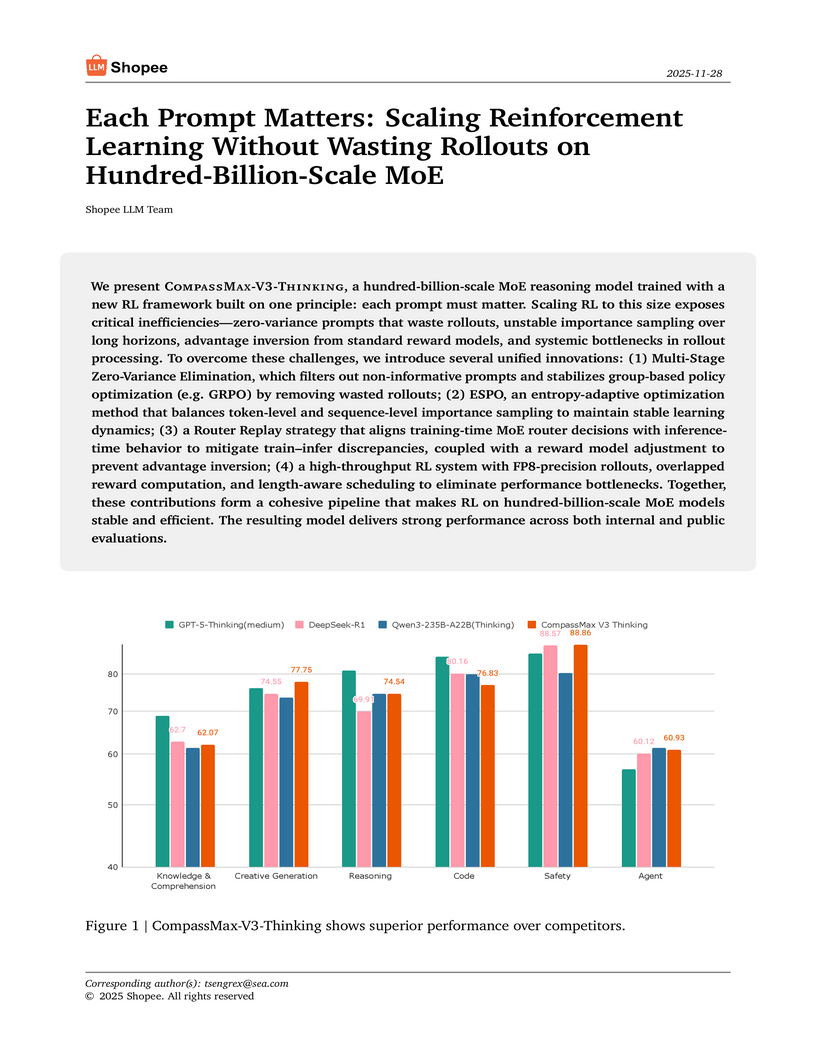
08 Dec 2025
The Shopee LLM Team developed an integrated Reinforcement Learning framework for stable and efficient training of hundred-billion-scale Mixture-of-Experts models, culminating in CompassMax-V3-Thinking. This framework mitigates critical inefficiencies and instabilities in large-scale RL, leading to state-of-the-art performance across diverse reasoning and domain-specific e-commerce tasks.
There are no more papers matching your filters at the moment.
