08 Dec 2025
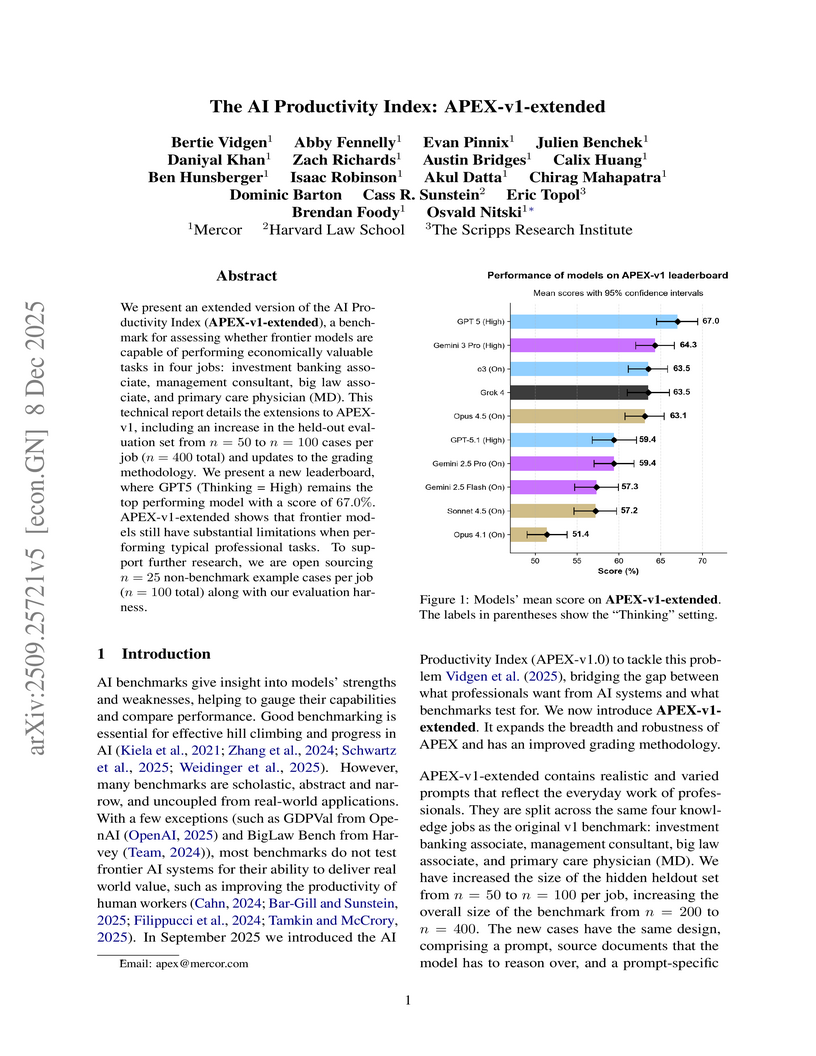
We present an extended version of the AI Productivity Index (APEX-v1-extended), a benchmark for assessing whether frontier models are capable of performing economically valuable tasks in four jobs: investment banking associate, management consultant, big law associate, and primary care physician (MD). This technical report details the extensions to APEX-v1, including an increase in the held-out evaluation set from n = 50 to n = 100 cases per job (n = 400 total) and updates to the grading methodology. We present a new leaderboard, where GPT5 (Thinking = High) remains the top performing model with a score of 67.0%. APEX-v1-extended shows that frontier models still have substantial limitations when performing typical professional tasks. To support further research, we are open sourcing n = 25 non-benchmark example cases per role (n = 100 total) along with our evaluation harness.

17 Apr 2025



Researchers developed REAL, a benchmark featuring 11 deterministic, high-fidelity simulations of real-world websites and 112 multi-turn tasks to evaluate autonomous web agents. The evaluation of frontier language models on REAL revealed that no agent achieved higher than a 41.07% success rate, indicating significant limitations in current capabilities.
There are no more papers matching your filters at the moment.
