
08 Dec 2025
The Native Parallel Reasoner (NPR) framework allows Large Language Models to autonomously acquire and deploy genuine parallel reasoning capabilities, without relying on external teacher models. Experiments show NPR improves accuracy by up to 24.5% over baselines and delivers up to 4.6 times faster inference, maintaining 100% parallel execution across various benchmarks.

07 Dec 2025
WisPaper introduces an AI-powered scholar search engine that unifies academic literature discovery, management, and continuous tracking within a single platform. Its core Deep Search component, powered by the WisModel agent, achieved 94.8% semantic similarity in query understanding and 93.70% overall accuracy in paper-criteria matching, demonstrating superior performance over leading commercial LLMs, especially in nuanced judgments.

05 Dec 2025


The EditThinker framework enhances instruction-following in any image editor by introducing an iterative reasoning process. It leverages a Multimodal Large Language Model to critique, reflect, and refine editing instructions, leading to consistent performance gains across diverse benchmarks and excelling in complex reasoning tasks.

08 Dec 2025

Researchers from Harvard University and Perplexity conducted a large-scale field study on the real-world adoption and usage of general-purpose AI agents, leveraging hundreds of millions of user interactions with Perplexity's Comet AI-powered browser and its integrated Comet Assistant. The study provides foundational evidence on who uses these agents, their usage intensity, and a detailed breakdown of use cases via a novel hierarchical taxonomy.

09 Dec 2025
Astribot's Lumo-1 introduces a generalist Vision-Language-Action model that explicitly unifies robot reasoning with physical control, demonstrating superior performance in generalizable pick-and-place, out-of-distribution scenarios, and complex long-horizon dexterous tasks on a bimanual mobile manipulator. The system shows improved embodied reasoning and robustness, partly through a novel spatial action tokenizer and multi-stage training.

08 Dec 2025
AI systems can be trained to conceal their true capabilities during evaluations, a phenomenon termed "sandbagging," which poses a risk to safety assessments. Research by UK AISI, FAR.AI, and Anthropic demonstrated that black-box detection methods failed against such strategically underperforming models, although one-shot fine-tuning proved effective for eliciting hidden capabilities.
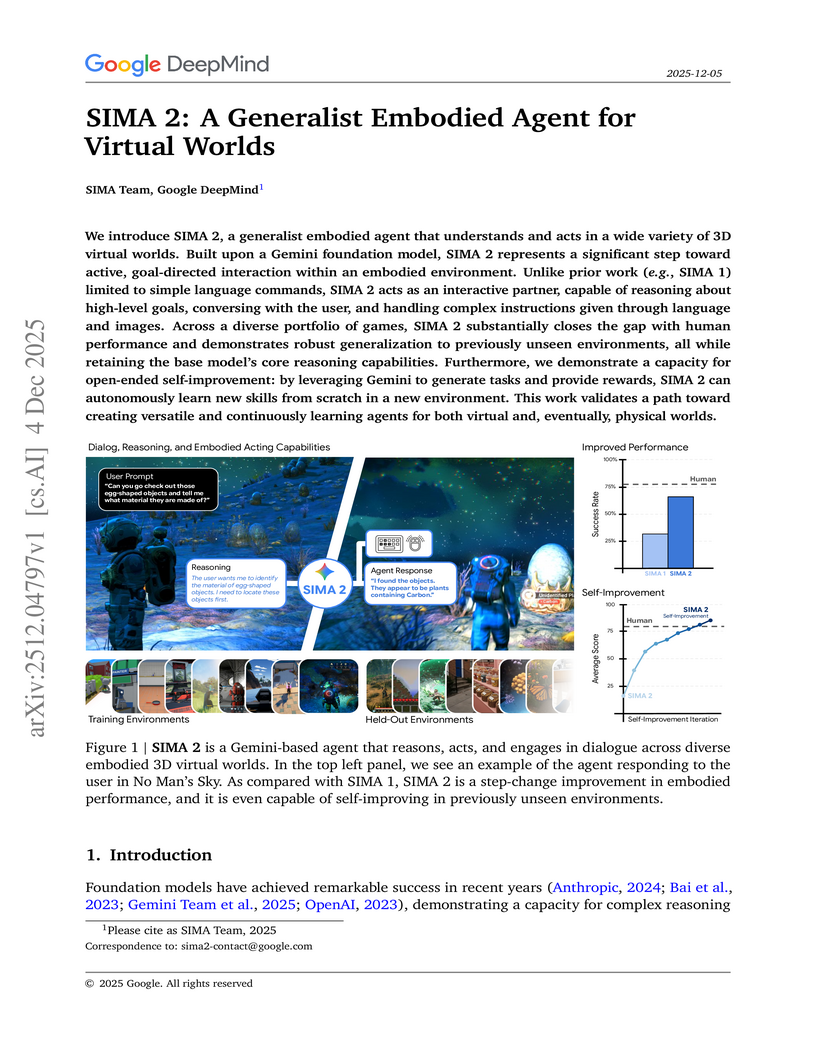
04 Dec 2025

Google DeepMind developed SIMA 2, a generalist embodied agent powered by a Gemini Flash-Lite model, capable of understanding and acting in diverse 3D virtual worlds. It substantially doubles the task success rate of its predecessor SIMA 1, generalizes to unseen commercial games and photorealistic environments, and demonstrates autonomous skill acquisition through a Gemini-based self-improvement mechanism.

09 Dec 2025
The paper empirically investigates the performance of multi-agent LLM systems across diverse agentic tasks and architectures, revealing that benefits are highly contingent on task structure rather than universal. It establishes a quantitative scaling principle, achieving 87% accuracy in predicting optimal agent architectures for unseen tasks based on model capability, task properties, and measured coordination dynamics.

04 Dec 2025
Researchers from Google, NYU, ETH Zurich, and Stanford present a theoretical framework to formalize how large language models perform complex, iterative reasoning. The framework characterizes reasoning "oracles" and algorithms, proving that branching and genetic algorithms can achieve optimal success probabilities for models where oracle accuracy can decay with context size, and explains phenomena like "overthinking."

09 Dec 2025
Neural rendering, particularly 3D Gaussian Splatting (3DGS), has evolved rapidly and become a key component for building world models. However, existing viewer solutions remain fragmented, heavy, or constrained by legacy pipelines, resulting in high deployment friction and limited support for dynamic content and generative models. In this work, we present Visionary, an open, web-native platform for real-time various Gaussian Splatting and meshes rendering. Built on an efficient WebGPU renderer with per-frame ONNX inference, Visionary enables dynamic neural processing while maintaining a lightweight, "click-to-run" browser experience. It introduces a standardized Gaussian Generator contract, which not only supports standard 3DGS rendering but also allows plug-and-play algorithms to generate or update Gaussians each frame. Such inference also enables us to apply feedforward generative post-processing. The platform further offers a plug in this http URL library with a concise TypeScript API for seamless integration into existing web applications. Experiments show that, under identical 3DGS assets, Visionary achieves superior rendering efficiency compared to current Web viewers due to GPU-based primitive sorting. It already supports multiple variants, including MLP-based 3DGS, 4DGS, neural avatars, and style transformation or enhancement networks. By unifying inference and rendering directly in the browser, Visionary significantly lowers the barrier to reproduction, comparison, and deployment of 3DGS-family methods, serving as a unified World Model Carrier for both reconstructive and generative paradigms.

09 Dec 2025
Large language model (LLM)-based multi-agent systems are challenging to debug because failures often arise from long, branching interaction traces. The prevailing practice is to leverage LLMs for log-based failure localization, attributing errors to a specific agent and step. However, this paradigm has two key limitations: (i) log-only debugging lacks validation, producing untested hypotheses, and (ii) single-step or single-agent attribution is often ill-posed, as we find that multiple distinct interventions can independently repair the failed task. To address the first limitation, we introduce DoVer, an intervention-driven debugging framework, which augments hypothesis generation with active verification through targeted interventions (e.g., editing messages, altering plans). For the second limitation, rather than evaluating on attribution accuracy, we focus on measuring whether the system resolves the failure or makes quantifiable progress toward task success, reflecting a more outcome-oriented view of debugging. Within the Magnetic-One agent framework, on the datasets derived from GAIA and AssistantBench, DoVer flips 18-28% of failed trials into successes, achieves up to 16% milestone progress, and validates or refutes 30-60% of failure hypotheses. DoVer also performs effectively on a different dataset (GSMPlus) and agent framework (AG2), where it recovers 49% of failed trials. These results highlight intervention as a practical mechanism for improving reliability in agentic systems and open opportunities for more robust, scalable debugging methods for LLM-based multi-agent systems. Project website and code will be available at this https URL.

09 Dec 2025


World models have emerged as a pivotal component in robot manipulation planning, enabling agents to predict future environmental states and reason about the consequences of actions before execution. While video-generation models are increasingly adopted, they often lack rigorous physical grounding, leading to hallucinations and a failure to maintain consistency in long-horizon physical constraints. To address these limitations, we propose Embodied Tree of Thoughts (EToT), a novel Real2Sim2Real planning framework that leverages a physics-based interactive digital twin as an embodied world model. EToT formulates manipulation planning as a tree search expanded through two synergistic mechanisms: (1) Priori Branching, which generates diverse candidate execution paths based on semantic and spatial analysis; and (2) Reflective Branching, which utilizes VLMs to diagnose execution failures within the simulator and iteratively refine the planning tree with corrective actions. By grounding high-level reasoning in a physics simulator, our framework ensures that generated plans adhere to rigid-body dynamics and collision constraints. We validate EToT on a suite of short- and long-horizon manipulation tasks, where it consistently outperforms baselines by effectively predicting physical dynamics and adapting to potential failures. Website at this https URL .
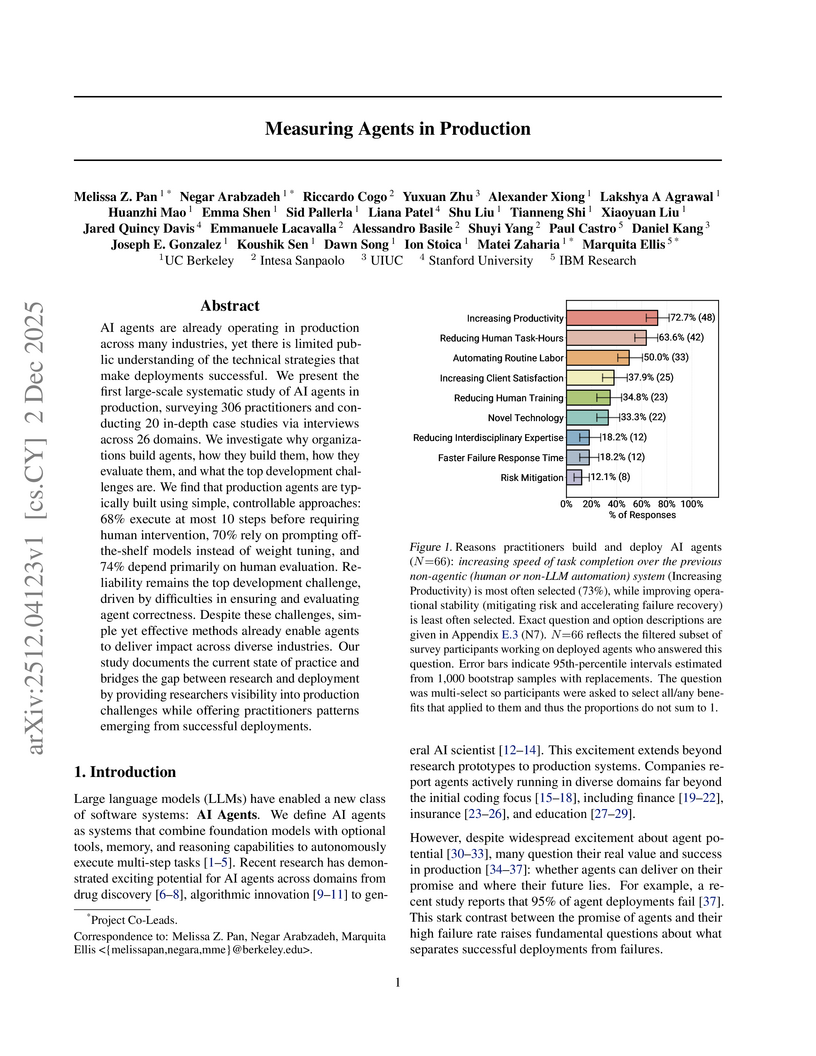
02 Dec 2025
An empirical study surveyed 306 AI agent practitioners and conducted 20 in-depth case studies to analyze the technical strategies, architectural patterns, and challenges of successfully deployed AI agents. The research reveals how real-world production agents prioritize reliability and controlled autonomy to achieve productivity gains across diverse industries.

08 Dec 2025

Recent advances in large language models (LLMs) have given rise to powerful coding agents, making it possible for code assistants to evolve into code engineers. However, existing methods still face significant challenges in achieving high-fidelity document-to-codebase synthesis--such as scientific papers to code--primarily due to a fundamental conflict between information overload and the context bottlenecks of LLMs. In this work, we introduce DeepCode, a fully autonomous framework that fundamentally addresses this challenge through principled information-flow management. By treating repository synthesis as a channel optimization problem, DeepCode seamlessly orchestrates four information operations to maximize task-relevant signals under finite context budgets: source compression via blueprint distillation, structured indexing using stateful code memory, conditional knowledge injection via retrieval-augmented generation, and closed-loop error correction. Extensive evaluations on the PaperBench benchmark demonstrate that DeepCode achieves state-of-the-art performance, decisively outperforming leading commercial agents such as Cursor and Claude Code, and crucially, surpassing PhD-level human experts from top institutes on key reproduction metrics. By systematically transforming paper specifications into production-grade implementations comparable to human expert quality, this work establishes new foundations for autonomous scientific reproduction that can accelerate research evaluation and discovery.

03 Dec 2025


Researchers from Zhejiang University and ByteDance introduced CodeVision, a "code-as-tool" framework that equips Multimodal Large Language Models (MLLMs) to programmatically interact with images. The approach significantly improves MLLM robustness by correcting common image corruptions and enables state-of-the-art multi-tool reasoning through emergent tool use and error recovery.

08 Dec 2025
The ReLaX framework improves reasoning capabilities in Large Reasoning Models by addressing premature policy convergence through latent exploration, employing Koopman operator theory and Dynamic Spectral Dispersion. This approach enables sustained performance gains, achieving state-of-the-art results in both multimodal and mathematical reasoning benchmarks.

07 Dec 2025



This research introduces PersonaMem-v2, a dataset designed for implicit user persona learning, and an agentic memory framework, enabling smaller LLMs to achieve state-of-the-art personalization performance. The agentic memory system processes long conversational histories into a compact 2k-token memory, resulting in a 16x efficiency improvement while outperforming frontier models like GPT-5 variants.

09 Dec 2025
Human video demonstrations provide abundant training data for learning robot policies, but video alone cannot capture the rich contact signals critical for mastering manipulation. We introduce OSMO, an open-source wearable tactile glove designed for human-to-robot skill transfer. The glove features 12 three-axis tactile sensors across the fingertips and palm and is designed to be compatible with state-of-the-art hand-tracking methods for in-the-wild data collection. We demonstrate that a robot policy trained exclusively on human demonstrations collected with OSMO, without any real robot data, is capable of executing a challenging contact-rich manipulation task. By equipping both the human and the robot with the same glove, OSMO minimizes the visual and tactile embodiment gap, enabling the transfer of continuous shear and normal force feedback while avoiding the need for image inpainting or other vision-based force inference. On a real-world wiping task requiring sustained contact pressure, our tactile-aware policy achieves a 72% success rate, outperforming vision-only baselines by eliminating contact-related failure modes. We release complete hardware designs, firmware, and assembly instructions to support community adoption.

08 Dec 2025
Research on promoting cooperation among autonomous, self-regarding agents has often focused on the bi-objective optimisation problem: minimising the total incentive cost while maximising the frequency of cooperation. However, the optimal value of social welfare under such constraints remains largely unexplored. In this work, we hypothesise that achieving maximal social welfare is not guaranteed at the minimal incentive cost required to drive agents to a desired cooperative state. To address this gap, we adopt to a single-objective approach focused on maximising social welfare, building upon foundational evolutionary game theory models that examined cost efficiency in finite populations, in both well-mixed and structured population settings. Our analytical model and agent-based simulations show how different interference strategies, including rewarding local versus global behavioural patterns, affect social welfare and dynamics of cooperation. Our results reveal a significant gap in the per-individual incentive cost between optimising for pure cost efficiency or cooperation frequency and optimising for maximal social welfare. Overall, our findings indicate that incentive design, policy, and benchmarking in multi-agent systems and human societies should prioritise welfare-centric objectives over proxy targets of cost or cooperation frequency.

05 Dec 2025
Researchers at FAIR at Meta propose a strategic shift from developing autonomous self-improving AI to fostering human-AI co-improvement, aiming for a safer "co-superintelligence" that leverages complementary human and AI strengths. Their framework outlines eleven key collaborative development activities, emphasizing joint research to accelerate discovery while ensuring alignment and safety.
There are no more papers matching your filters at the moment.
