
19 Mar 2025
The Language Model Council (LMC) introduces a democratic framework for benchmarking Foundation Models on highly subjective tasks, using all council members to create tests, generate responses, and collectively judge. This approach achieved a 0.92 Spearman correlation with human evaluations for emotional intelligence, demonstrating superior alignment with human preferences and robustly mitigating individual LLM biases.
29 Apr 2024
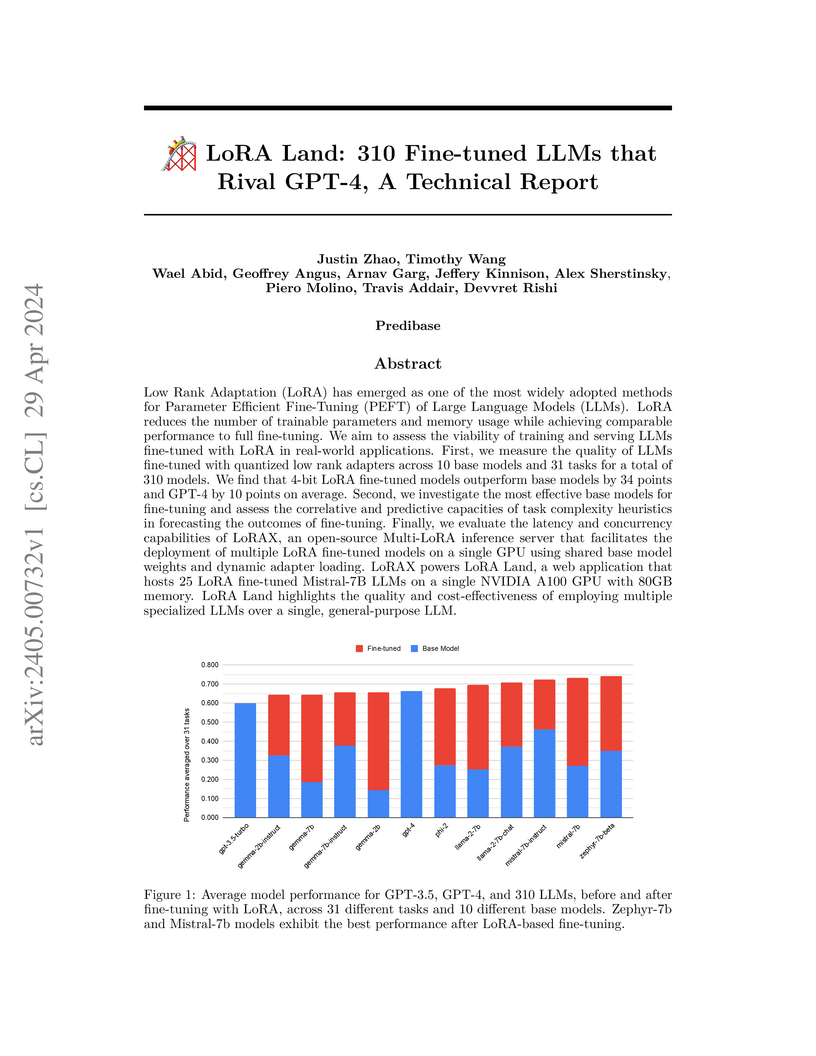
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
There are no more papers matching your filters at the moment.
