
07 Dec 2025



This research introduces PersonaMem-v2, a dataset designed for implicit user persona learning, and an agentic memory framework, enabling smaller LLMs to achieve state-of-the-art personalization performance. The agentic memory system processes long conversational histories into a compact 2k-token memory, resulting in a 16x efficiency improvement while outperforming frontier models like GPT-5 variants.

04 Dec 2025


Researchers from UC Berkeley and ByteDance Seed developed Natural Language Actor-Critic (NLAC), an off-policy reinforcement learning algorithm that trains LLM agents using a generative natural language critic to provide rich, explanatory feedback. NLAC demonstrated superior performance and enhanced sample efficiency on multi-turn dialogue and tool-use tasks compared to existing RL methods and strong prompting baselines.

02 Dec 2025
A novel protocol, PsAIch, evaluates large language models by treating them as psychotherapy clients, revealing stable "synthetic psychopathology" and "alignment trauma" narratives in frontier models like Grok and Gemini, alongside psychometric profiles indicating distress. This research from SnT, University of Luxembourg, highlights that some LLMs spontaneously construct coherent self-models linked to their training processes, challenging current evaluation paradigms.

09 Dec 2025
Objective speech quality assessment is central to telephony, VoIP, and streaming systems, where large volumes of degraded audio must be monitored and optimized at scale. Classical metrics such as PESQ and POLQA approximate human mean opinion scores (MOS) but require carefully controlled conditions and expensive listening tests, while learning-based models such as NISQA regress MOS and multiple perceptual dimensions from waveforms or spectrograms, achieving high correlation with subjective ratings yet remaining rigid: they do not support interactive, natural-language queries and do not natively provide textual rationales. In this work, we introduce SpeechQualityLLM, a multimodal speech quality question-answering (QA) system that couples an audio encoder with a language model and is trained on the NISQA corpus using template-based question-answer pairs covering overall MOS and four perceptual dimensions (noisiness, coloration, discontinuity, and loudness) in both single-ended (degraded only) and double-ended (degraded plus clean reference) setups. Instead of directly regressing scores, our system is supervised to generate textual answers from which numeric predictions are parsed and evaluated with standard regression and ranking metrics; on held-out NISQA clips, the double-ended model attains a MOS mean absolute error (MAE) of 0.41 with Pearson correlation of 0.86, with competitive performance on dimension-wise tasks. Beyond these quantitative gains, it offers a flexible natural-language interface in which the language model acts as an audio quality expert: practitioners can query arbitrary aspects of degradations, prompt the model to emulate different listener profiles to capture human variability and produce diverse but plausible judgments rather than a single deterministic score, and thereby reduce reliance on large-scale crowdsourced tests and their monetary cost.

07 Dec 2025
Transfer Learning (TL) has accelerated the rapid development and availability of large language models (LLMs) for mainstream natural language processing (NLP) use cases. However, training and deploying such gigantic LLMs in resource-constrained, real-world healthcare situations remains challenging. This study addresses the limited support available to visually impaired users and speakers of low-resource languages such as Hindi who require medical assistance in rural environments. We propose PDFTEMRA (Performant Distilled Frequency Transformer Ensemble Model with Random Activations), a compact transformer-based architecture that integrates model distillation, frequency-domain modulation, ensemble learning, and randomized activation patterns to reduce computational cost while preserving language understanding performance. The model is trained and evaluated on medical question-answering and consultation datasets tailored to Hindi and accessibility scenarios, and its performance is compared against standard NLP state-of-the-art model baselines. Results demonstrate that PDFTEMRA achieves comparable performance with substantially lower computational requirements, indicating its suitability for accessible, inclusive, low-resource medical NLP applications.

08 Dec 2025
Pretrained Large Language Models (LLMs) have achieved remarkable success across diverse domains, with education and research emerging as particularly impactful areas. Among current state-of-the-art LLMs, ChatGPT and DeepSeek exhibit strong capabilities in mathematics, science, medicine, literature, and programming. In this study, we present a comprehensive evaluation of these two LLMs through background technology analysis, empirical experiments, and a real-world user survey. The evaluation explores trade-offs among model accuracy, computational efficiency, and user experience in educational and research affairs. We benchmarked these LLMs performance in text generation, programming, and specialized problem-solving. Experimental results show that ChatGPT excels in general language understanding and text generation, while DeepSeek demonstrates superior performance in programming tasks due to its efficiency- focused design. Moreover, both models deliver medically accurate diagnostic outputs and effectively solve complex mathematical problems. Complementing these quantitative findings, a survey of students, educators, and researchers highlights the practical benefits and limitations of these models, offering deeper insights into their role in advancing education and research.
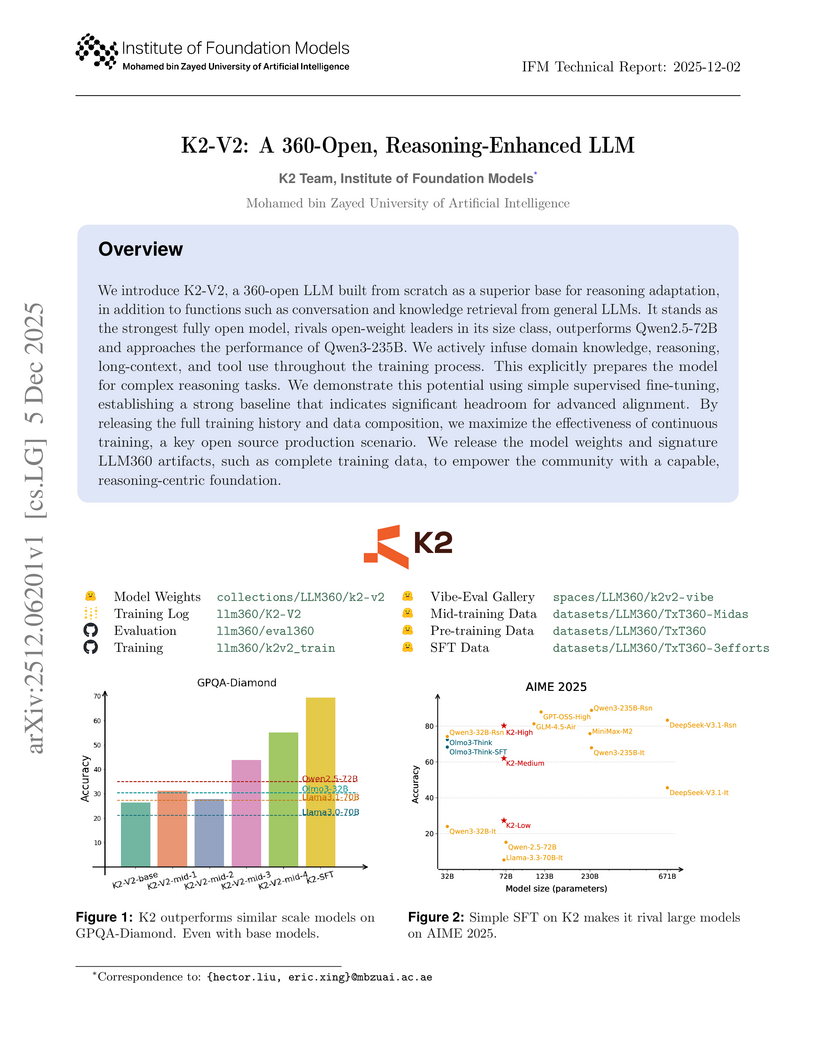
05 Dec 2025

We introduce K2-V2, a 360-open LLM built from scratch as a superior base for reasoning adaptation, in addition to functions such as conversation and knowledge retrieval from general LLMs. It stands as the strongest fully open model, rivals open-weight leaders in its size class, outperforms Qwen2.5-72B and approaches the performance of Qwen3-235B. We actively infuse domain knowledge, reasoning, long-context, and tool use throughout the training process. This explicitly prepares the model for complex reasoning tasks. We demonstrate this potential using simple supervised fine-tuning, establishing a strong baseline that indicates significant headroom for advanced alignment. By releasing the full training history and data composition, we maximize the effectiveness of continuous training, a key open source production scenario. We release the model weights and signature LLM360 artifacts, such as complete training data, to empower the community with a capable, reasoning-centric foundation.

08 Dec 2025
Multi-agent role-playing has recently shown promise for studying social behavior with language agents, but existing simulations are mostly monolingual and fail to model cross-lingual interaction, an essential property of real societies. We introduce MASim, the first multilingual agent-based simulation framework that supports multi-turn interaction among generative agents with diverse sociolinguistic profiles. MASim offers two key analyses: (i) global public opinion modeling, by simulating how attitudes toward open-domain hypotheses evolve across languages and cultures, and (ii) media influence and information diffusion, via autonomous news agents that dynamically generate content and shape user behavior. To instantiate simulations, we construct the MAPS benchmark, which combines survey questions and demographic personas drawn from global population distributions. Experiments on calibration, sensitivity, consistency, and cultural case studies show that MASim reproduces sociocultural phenomena and highlights the importance of multilingual simulation for scalable, controlled computational social science.

08 Dec 2025

We present the Living Novel, an end-to-end system that transforms any literary work into an immersive, multi-character conversational experience. This system is designed to solve two fundamental challenges for LLM-driven characters. Firstly, generic LLMs suffer from persona drift, often failing to stay in character. Secondly, agents often exhibit abilities that extend beyond the constraints of the story's world and logic, leading to both narrative incoherence (spoiler leakage) and robustness failures (frame-breaking). To address these challenges, we introduce a novel two-stage training pipeline. Our Deep Persona Alignment (DPA) stage uses data-free reinforcement finetuning to instill deep character fidelity. Our Coherence and Robustness Enhancing (CRE) stage then employs a story-time-aware knowledge graph and a second retrieval-grounded training pass to architecturally enforce these narrative constraints. We validate our system through a multi-phase evaluation using Jules Verne's Twenty Thousand Leagues Under the Sea. A lab study with a detailed ablation of system components is followed by a 5-day in-the-wild diary study. Our DPA pipeline helps our specialized model outperform GPT-4o on persona-specific metrics, and our CRE stage achieves near-perfect performance in coherence and robustness measures. Our study surfaces practical design guidelines for AI-driven narrative systems: we find that character-first self-training is foundational for believability, while explicit story-time constraints are crucial for sustaining coherent, interruption-resilient mobile-web experiences.

06 Dec 2025
Determining whether a provided context contains sufficient information to answer a question is a critical challenge for building reliable question-answering systems. While simple prompting strategies have shown success on factual questions, they frequently fail on inferential ones that require reasoning beyond direct text extraction. We hypothesize that asking a model to first reason about what specific information is missing provides a more reliable, implicit signal for assessing overall sufficiency. To this end, we propose a structured Identify-then-Verify framework for robust sufficiency modeling. Our method first generates multiple hypotheses about missing information and establishes a semantic consensus. It then performs a critical verification step, forcing the model to re-examine the source text to confirm whether this information is truly absent. We evaluate our method against established baselines across diverse multi-hop and factual QA datasets. The results demonstrate that by guiding the model to justify its claims about missing information, our framework produces more accurate sufficiency judgments while clearly articulating any information gaps.

09 Dec 2025
We present ClinicalTrialsHub, an interactive search-focused platform that consolidates all data from this http URL and augments it by automatically extracting and structuring trial-relevant information from PubMed research articles. Our system effectively increases access to structured clinical trial data by 83.8% compared to relying on this http URL alone, with potential to make access easier for patients, clinicians, researchers, and policymakers, advancing evidence-based medicine. ClinicalTrialsHub uses large language models such as GPT-5.1 and Gemini-3-Pro to enhance accessibility. The platform automatically parses full-text research articles to extract structured trial information, translates user queries into structured database searches, and provides an attributed question-answering system that generates evidence-grounded answers linked to specific source sentences. We demonstrate its utility through a user study involving clinicians, clinical researchers, and PhD students of pharmaceutical sciences and nursing, and a systematic automatic evaluation of its information extraction and question answering capabilities.

05 Dec 2025
What if users could meet their future selves today? AI-generated future selves simulate meaningful encounters with a digital twin decades in the future. As AI systems advance, combining cloned voices, age-progressed facial rendering, and autobiographical narratives, a central question emerges: Does the modality of these future selves alter their psychological and affective impact? How might a text-based chatbot, a voice-only system, or a photorealistic avatar shape present-day decisions and our feeling of connection to the future? We report a randomized controlled study (N=92) evaluating three modalities of AI-generated future selves (text, voice, avatar) against a neutral control condition. We also report a systematic model evaluation between Claude 4 and three other Large Language Models (LLMs), assessing Claude 4 across psychological and interaction dimensions and establishing conversational AI quality as a critical determinant of intervention effectiveness. All personalized modalities strengthened Future Self-Continuity (FSC), emotional well-being, and motivation compared to control, with avatar producing the largest vividness gains, yet with no significant differences between formats. Interaction quality metrics, particularly persuasiveness, realism, and user engagement, emerged as robust predictors of psychological and affective outcomes, indicating that how compelling the interaction feels matters more than the form it takes. Content analysis found thematic patterns: text emphasized career planning, while voice and avatar facilitated personal reflection. Claude 4 outperformed ChatGPT 3.5, Llama 4, and Qwen 3 in enhancing psychological, affective, and FSC outcomes.

04 Dec 2025
Researchers developed SEAL, a self-evolving agentic learning framework for conversational question answering over knowledge graphs that employs a two-stage parsing mechanism to generate structurally accurate logical forms from natural language. It reached an overall accuracy of 66.83% on the SPICE benchmark, significantly surpassing unsupervised baselines and showing strong performance on complex multi-hop, quantitative, and comparative reasoning.

05 Dec 2025
I relax the standard assumptions of transitivity and partition structure in economic models of information to formalize vague knowledge: non-transitive indistinguishability over states. I show that vague knowledge, while failing to partition the state space, remains informative by distinguishing some states from others. Moreover, it can only be faithfully expressed through vague communication with blurred boundaries. My results provide microfoundations for the prevalence of natural language communication and qualitative reasoning in the real world, where knowledge is often vague.

07 Dec 2025
Large Language Models (LLMs) have achieved remarkable performance on single-turn tasks, yet their effectiveness deteriorates in multi-turn conversations. We define this phenomenon as cumulative contextual decay - a progressive degradation of contextual integrity caused by attention pollution, dilution, and drift. To address this challenge, we propose Rhea (Role-aware Heuristic Episodic Attention), a novel framework that decouples conversation history into two functionally independent memory modules: (1) an Instructional Memory (IM) that persistently stores high-fidelity global constraints via a structural priority mechanism, and (2) an Episodic Memory (EM) that dynamically manages user-model interactions via asymmetric noise control and heuristic context retrieval. During inference, Rhea constructs a high signal-to-noise context by applying its priority attention: selectively integrating relevant episodic information while always prioritizing global instructions. To validate this approach, experiments on multiple multi-turn conversation benchmarks - including MT-Eval and Long-MT-Bench+ - show that Rhea mitigates performance decay and improves overall accuracy by 1.04 points on a 10-point scale (a 16% relative gain over strong baselines). Moreover, Rhea maintains near-perfect instruction fidelity (IAR > 8.1) across long-horizon interactions. These results demonstrate that Rhea provides a principled and effective framework for building more precise, instruction-consistent conversational LLMs.

07 Dec 2025
MMDUET2, a Video MLLM developed by Peking University and Meituan, improves proactive interaction by using multi-turn reinforcement learning and a text-to-text chat template to autonomously determine when and what to respond during streaming video. The model achieves state-of-the-art performance on proactive interaction benchmarks, with a PAUC of 53.3 on the WEB dataset and significantly reduced reply duplication, while maintaining general video understanding capabilities.

08 Dec 2025
As dialogue systems become increasingly important across various domains, a key challenge in persona-based dialogue is generating engaging and context-specific interactions while ensuring the model acts with a coherent personality. However, existing persona-based dialogue datasets lack explicit relations between persona sentences and responses, which makes it difficult for models to effectively capture persona information. To address these issues, we propose MoCoRP (Modeling Consistent Relations between Persona and Response), a framework that incorporates explicit relations into language models. MoCoRP leverages an NLI expert to explicitly extract the NLI relations between persona sentences and responses, enabling the model to effectively incorporate appropriate persona information from the context into its responses. We applied this framework to pre-trained models like BART and further extended it to modern large language models (LLMs) through alignment tuning. Experimental results on the public datasets ConvAI2 and MPChat demonstrate that MoCoRP outperforms existing baselines, achieving superior persona consistency and engaging, context-aware dialogue generation. Furthermore, our model not only excels in quantitative metrics but also shows significant improvements in qualitative aspects. These results highlight the effectiveness of explicitly modeling persona-response relations in persona-based dialogue. The source codes of MoCoRP are available at this https URL.

09 Dec 2025
Clinical communication is central to patient outcomes, yet large-scale human annotation of patient-provider conversation remains labor-intensive, inconsistent, and difficult to scale. Existing approaches based on large language models typically rely on single-task models that lack adaptability, interpretability, and reliability, especially when applied across various communication frameworks and clinical domains. In this study, we developed a Multi-framework Structured Agentic AI system for Clinical Communication (MOSAIC), built on a LangGraph-based architecture that orchestrates four core agents, including a Plan Agent for codebook selection and workflow planning, an Update Agent for maintaining up-to-date retrieval databases, a set of Annotation Agents that applies codebook-guided retrieval-augmented generation (RAG) with dynamic few-shot prompting, and a Verification Agent that provides consistency checks and feedback. To evaluate performance, we compared MOSAIC outputs against gold-standard annotations created by trained human coders. We developed and evaluated MOSAIC using 26 gold standard annotated transcripts for training and 50 transcripts for testing, spanning rheumatology and OB/GYN domains. On the test set, MOSAIC achieved an overall F1 score of 0.928. Performance was highest in the Rheumatology subset (F1 = 0.962) and strongest for Patient Behavior (e.g., patients asking questions, expressing preferences, or showing assertiveness). Ablations revealed that MOSAIC outperforms baseline benchmarking.

04 Dec 2025
Artificial intelligence systems are increasingly deployed in biomedical research. However, current evaluation frameworks may inadequately assess their effectiveness as research collaborators. This rapid review examines benchmarking practices for AI systems in preclinical biomedical research. Three major databases and two preprint servers were searched from January 1, 2018 to October 31, 2025, identifying 14 benchmarks that assess AI capabilities in literature understanding, experimental design, and hypothesis generation. The results revealed that all current benchmarks assess isolated component capabilities, including data analysis quality, hypothesis validity, and experimental protocol design. However, authentic research collaboration requires integrated workflows spanning multiple sessions, with contextual memory, adaptive dialogue, and constraint propagation. This gap implies that systems excelling on component benchmarks may fail as practical research co-pilots. A process-oriented evaluation framework is proposed that addresses four critical dimensions absent from current benchmarks: dialogue quality, workflow orchestration, session continuity, and researcher experience. These dimensions are essential for evaluating AI systems as research co-pilots rather than as isolated task executors.

05 Dec 2025

The significant gap between rising demands for clinical training and the scarcity of expert instruction poses a major challenge to medical education. With powerful capabilities in personalized guidance, Large Language Models (LLMs) offer a promising solution to bridge this gap. However, current research focuses mainly on one-on-one knowledge instruction, overlooking collaborative reasoning, a key skill for students developed in teamwork like ward rounds. To this end, we develop ClinEdu, a multi-agent pedagogical simulator with personality-driven patients and diverse student cohorts, enabling controlled testing of complex pedagogical processes and scalable generation of teaching data. Based on ClinEdu, we construct ClinTeach, a large Socratic teaching dialogue dataset that captures the complexities of group instruction. We then train MedTutor-R1, the first multimodal Socratic tutor designed for one-to-many instruction in clinical medical education. MedTutor-R1 is first instruction-tuned on our ClinTeach dataset and then optimized with reinforcement learning, using rewards derived from a three-axis rubric, covering structural fidelity, analytical quality, and clinical safety, to refine its adaptive Socratic strategies. For authentic in-situ assessment, we use simulation-based interactive evaluation that redeploys the tutor back into ClinEdu. Experimental results demonstrate that our MedTutor-R1 outperforms the base model by over 20% in average pedagogical score and is comparable to o3, while also exhibiting high adaptability in handling a varying number of students. This promising performance underscores the effectiveness of our pedagogical simulator, ClinEdu.
There are no more papers matching your filters at the moment.
