04 Aug 2025

The Hierarchical Reasoning Model (HRM), developed by researchers from Sapient Intelligence and Tsinghua University, introduces a recurrent architecture designed for deep algorithmic reasoning. The model, trained on minimal data, achieves near-perfect accuracy on complex tasks like Sudoku-Extreme and Maze-Hard, where leading large language models fail, and outperforms them on the ARC-AGI challenge, while also demonstrating emergent brain-like hierarchical processing.

10 Jun 2025

We consider a high-probability non-asymptotic confidence estimation in the
-regularized non-linear least-squares setting with fixed design. In
particular, we study confidence estimation for local minimizers of the
regularized training loss. We show a pointwise confidence bound, meaning that
it holds for the prediction on any given fixed test input . Importantly, the
proposed confidence bound scales with similarity of the test input to the
training data in the implicit feature space of the predictor (for instance,
becoming very large when the test input lies far outside of the training data).
This desirable last feature is captured by the weighted norm involving the
inverse-Hessian matrix of the objective function, which is a generalized
version of its counterpart in the linear setting, .
Our generalized result can be regarded as a non-asymptotic counterpart of the
classical confidence interval based on asymptotic normality of the MLE
estimator. We propose an efficient method for computing the weighted norm,
which only mildly exceeds the cost of a gradient computation of the loss
function. Finally, we complement our analysis with empirical evidence showing
that the proposed confidence bound provides better coverage/width trade-off
compared to a confidence estimation by bootstrapping, which is a gold-standard
method in many applications involving non-linear predictors such as neural
networks.

25 May 2025


Electrophysiological brain signals, such as electroencephalography (EEG),
exhibit both periodic and aperiodic components, with the latter often modeled
as 1/f noise and considered critical to cognitive and neurological processes.
Although various theoretical frameworks have been proposed to account for
aperiodic activity, its scale-invariant and long-range temporal dependency
remain insufficiently explained. Drawing on neural fluctuation theory, we
propose a novel framework that parameterizes intrinsic stochastic neural
fluctuations to account for aperiodic dynamics. Within this framework, we
introduce two key parameters-self-similarity and scale factor-to characterize
these fluctuations. Our findings reveal that EEG fluctuations exhibit
self-similar and non-stable statistical properties, challenging the assumptions
of conventional stochastic models in neural dynamical modeling. Furthermore,
the proposed parameters enable the reconstruction of EEG-like signals that
faithfully replicate the aperiodic spectrum, including the characteristic 1/f
spectral profile, and long range dependency. By linking structured neural
fluctuations to empirically observed aperiodic EEG activity, this work offers
deeper mechanistic insights into brain dynamics, resulting in a more robust
biomarker candidate than the traditional 1/f slope, and provides a
computational methodology for generating biologically plausible
neurophysiological signals.
04 Aug 2025
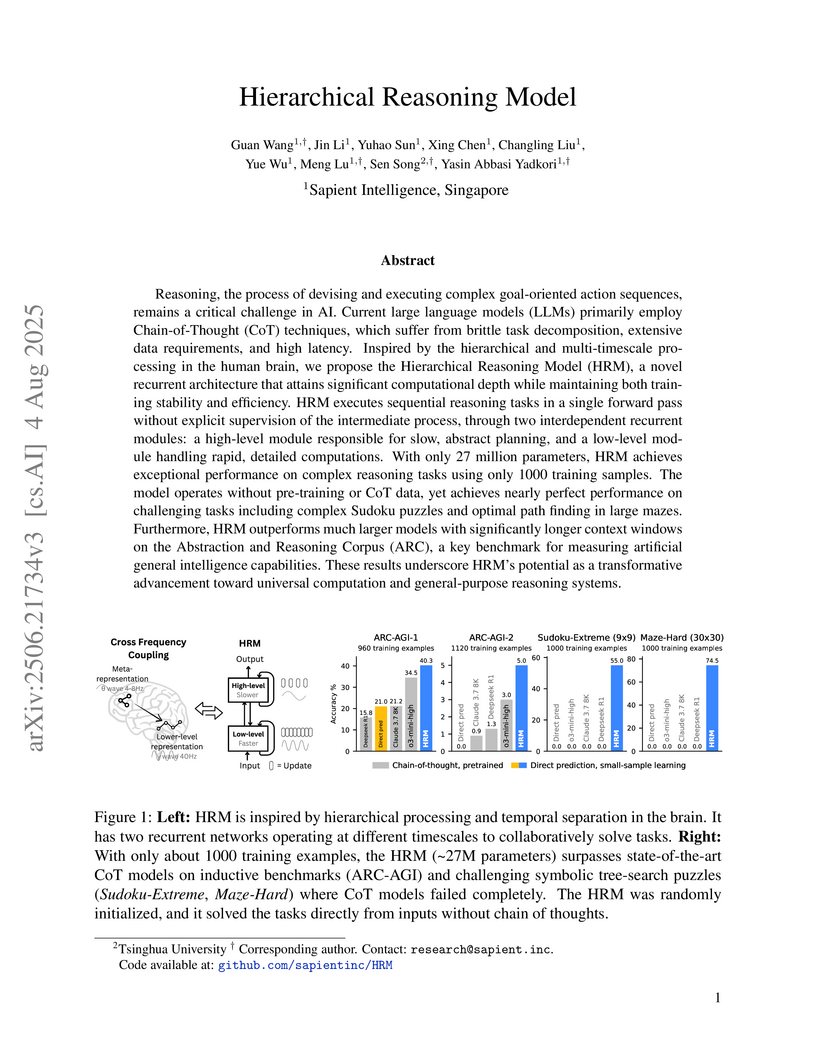
Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI. Current large language models (LLMs) primarily employ Chain-of-Thought (CoT) techniques, which suffer from brittle task decomposition, extensive data requirements, and high latency. Inspired by the hierarchical and multi-timescale processing in the human brain, we propose the Hierarchical Reasoning Model (HRM), a novel recurrent architecture that attains significant computational depth while maintaining both training stability and efficiency. HRM executes sequential reasoning tasks in a single forward pass without explicit supervision of the intermediate process, through two interdependent recurrent modules: a high-level module responsible for slow, abstract planning, and a low-level module handling rapid, detailed computations. With only 27 million parameters, HRM achieves exceptional performance on complex reasoning tasks using only 1000 training samples. The model operates without pre-training or CoT data, yet achieves nearly perfect performance on challenging tasks including complex Sudoku puzzles and optimal path finding in large mazes. Furthermore, HRM outperforms much larger models with significantly longer context windows on the Abstraction and Reasoning Corpus (ARC), a key benchmark for measuring artificial general intelligence capabilities. These results underscore HRM's potential as a transformative advancement toward universal computation and general-purpose reasoning systems.
There are no more papers matching your filters at the moment.
