
08 Dec 2025
The Native Parallel Reasoner (NPR) framework allows Large Language Models to autonomously acquire and deploy genuine parallel reasoning capabilities, without relying on external teacher models. Experiments show NPR improves accuracy by up to 24.5% over baselines and delivers up to 4.6 times faster inference, maintaining 100% parallel execution across various benchmarks.

07 Dec 2025




MeshSplatting generates connected, opaque, and colored triangle meshes from images using differentiable rendering, enabling direct integration of neurally reconstructed scenes into traditional 3D graphics pipelines. The method achieves a +0.69 dB PSNR improvement over MiLo on the Mip-NeRF360 dataset and trains 2x faster while requiring 2.5x less memory.

08 Dec 2025


A new framework, Distribution Matching Variational AutoEncoder (DMVAE), explicitly aligns a VAE's aggregate latent distribution with a pre-defined reference distribution using score-based matching. The approach achieves a state-of-the-art gFID of 1.82 on ImageNet 256x256, demonstrating superior training efficiency for downstream generative models, particularly when utilizing Self-Supervised Learning features as the reference.
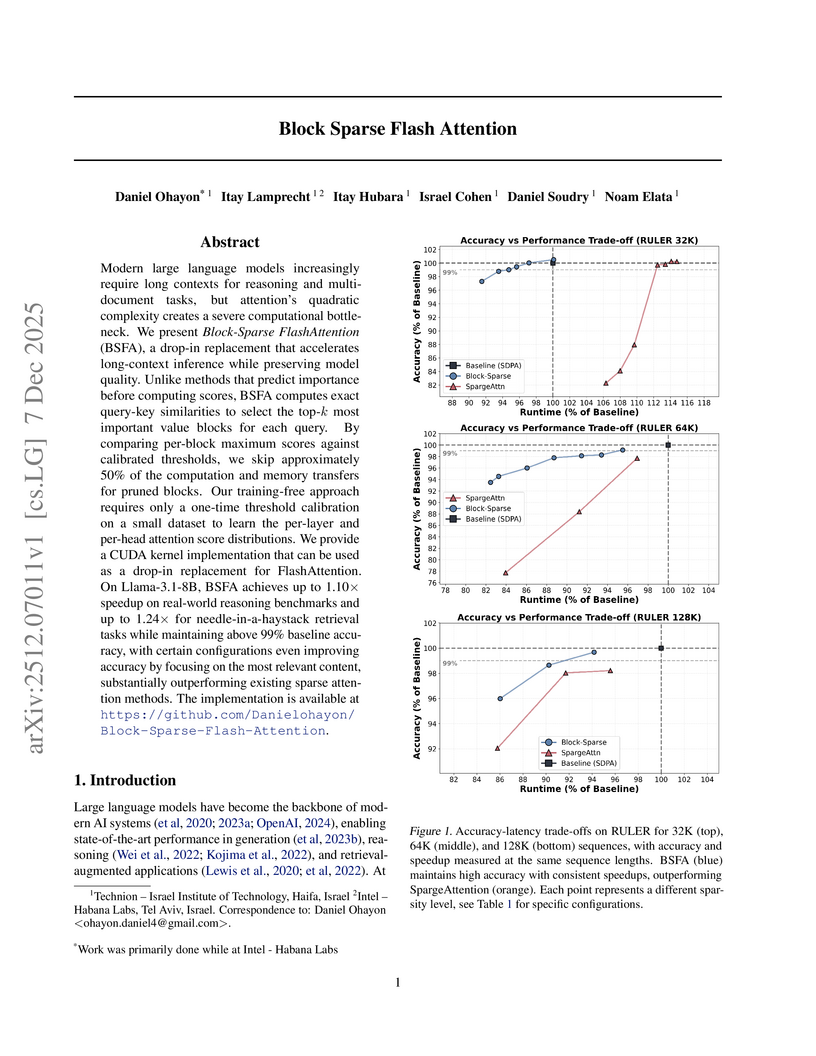
07 Dec 2025
Block Sparse Flash Attention (BSFA) accelerates large language model inference for long input sequences by intelligently skipping computations for negligible value blocks based on exact attention scores. This training-free method maintains high accuracy while achieving speedups up to 1.24x on retrieval tasks and 1.10x for general reasoning.

08 Dec 2025

DeepCode presents a multi-stage agentic framework for autonomously generating executable code repositories from scientific papers, achieving a 73.5% replication score on the PaperBench Code-Dev benchmark and exceeding PhD-level human expert performance.

09 Dec 2025
TreeGRPO introduces a reinforcement learning framework that reinterprets diffusion model denoising as a sparse search tree, enabling both sample efficiency and precise credit assignment for post-training. This method achieves 2.4 times faster training convergence and enhances alignment quality with human preferences compared to prior approaches.

09 Dec 2025



Researchers at HKUST developed TrackingWorld, a framework for dense, world-centric 3D tracking of nearly all pixels in monocular videos, effectively disentangling camera and object motion. This method integrates foundation models with a novel optimization pipeline to track objects, including newly emerging ones, demonstrating superior camera pose estimation and 3D depth consistency, achieving, for example, an Abs Rel depth error of 0.218 on Sintel compared to 0.636 from baselines.

07 Dec 2025
Researchers at ShanghaiTech University and Ant Group developed FlashMHF, an efficient multi-head Feed-Forward Network (FFN) for Transformer architectures that integrates a multi-head design with an I/O-aware fused kernel. This approach consistently improves language modeling perplexity and downstream task accuracy while reducing peak memory usage by 3-5x and accelerating inference up to 1.08x compared to standard FFNs.

10 Dec 2025



Researchers from Columbia University and NYU introduced Online World Modeling (OWM) and Adversarial World Modeling (AWM) to mitigate the train-test gap in world models for gradient-based planning (GBP). These methods enabled GBP to achieve performance comparable to or better than search-based planning algorithms like CEM, while simultaneously reducing computation time by an order of magnitude across various robotic tasks.

09 Dec 2025

Researchers from Peking University, Nanchang University, and Tsinghua University developed the first on-the-fly 3D reconstruction framework for multi-camera rigs, enabling calibration-free, large-scale, and high-fidelity scene reconstruction. The system generates drift-free trajectories and photorealistic novel views, reconstructing 100 meters of road or 100,000 m² of aerial scenes in two minutes.

08 Dec 2025
This document introduces foundational concepts and algorithms in Deep Reinforcement Learning (DRL) and Deep Imitation Learning (DIL) for embodied agents, providing a self-contained pedagogical resource from ISCTE – University Institute of Lisbon. It offers clear, in-depth explanations of core methods, including necessary mathematical prerequisites, to build a strong understanding for learners.

05 Dec 2025
Researchers at Anthropic introduced Selective GradienT Masking (SGTM), a pre-training method designed to localize and remove specific capabilities from large language models to address dual-use risks. This technique achieves an improved trade-off between retaining general knowledge and forgetting targeted information, resists adversarial fine-tuning up to 7 times better than prior unlearning methods, and demonstrates reduced information leakage in larger models.

07 Dec 2025
Researchers at the University of Bonn and TU Delft developed a monocular visual SLAM system that accurately estimates camera poses and provides scale-consistent dense 3D reconstruction in dynamic settings. The method integrates a deep learning model for moving object segmentation and depth estimation with a geometric bundle adjustment framework, achieving superior tracking and depth accuracy on challenging datasets.

07 Dec 2025
This survey paper elucidates how diverse machine learning tasks, including generative modeling and network optimization, can be framed as the evolution of probability distributions over time. It provides a unified mathematical framework by connecting optimal transport and diffusion processes, clarifying their applications and distinct properties within advanced machine learning paradigms.

09 Dec 2025


Worst-case generation plays a critical role in evaluating robustness and stress-testing systems under distribution shifts, in applications ranging from machine learning models to power grids and medical prediction systems. We develop a generative modeling framework for worst-case generation for a pre-specified risk, based on min-max optimization over continuous probability distributions, namely the Wasserstein space. Unlike traditional discrete distributionally robust optimization approaches, which often suffer from scalability issues, limited generalization, and costly worst-case inference, our framework exploits the Brenier theorem to characterize the least favorable (worst-case) distribution as the pushforward of a transport map from a continuous reference measure, enabling a continuous and expressive notion of risk-induced generation beyond classical discrete DRO formulations. Based on the min-max formulation, we propose a Gradient Descent Ascent (GDA)-type scheme that updates the decision model and the transport map in a single loop, establishing global convergence guarantees under mild regularity assumptions and possibly without convexity-concavity. We also propose to parameterize the transport map using a neural network that can be trained simultaneously with the GDA iterations by matching the transported training samples, thereby achieving a simulation-free approach. The efficiency of the proposed method as a risk-induced worst-case generator is validated by numerical experiments on synthetic and image data.

09 Dec 2025

This research provides theoretical and empirical evidence that generative models are essential for achieving data-efficient compositional generalization in visual perception, demonstrating that enforcing necessary inductive biases is feasible for decoders but largely infeasible for encoders without knowledge of out-of-domain data. Generative methods, through techniques like replay and gradient-based search, significantly improve out-of-domain accuracy compared to non-generative counterparts.

08 Dec 2025
The OMEGA framework introduces a training-free method to enhance diffusion models for multi-agent driving scene generation, significantly boosting scenario realism, structural consistency, and controllability. It achieves a 72.27% valid scene rate on nuPlan, a 39.92 percentage point increase over baselines, and generates 5 times more near-collision frames for adversarial testing while maintaining plausibility.

08 Dec 2025

This paper introduces Provable Diffusion Posterior Sampling (PDPS), a method for Bayesian inverse problems that integrates pre-trained diffusion models as data-driven priors. The approach offers the first non-asymptotic error bounds for diffusion-based posterior score estimation and demonstrates superior performance with reliable uncertainty quantification across various imaging tasks.

09 Dec 2025

Embodied Tree of Thoughts (EToT) integrates Vision-Language Models with a physics-based embodied world model and a tree-structured search to enable deliberative robot manipulation planning. The framework achieves an 88.8% average success rate on complex manipulation tasks by enabling pre-execution failure diagnosis and physically motivated plan revisions within a simulator.

09 Dec 2025


Large language model (LLM) agents often rely on external demonstrations or retrieval-augmented planning, leading to brittleness, poor generalization, and high computational overhead. Inspired by human problem-solving, we propose DuSAR (Dual-Strategy Agent with Reflecting) - a demonstration-free framework that enables a single frozen LLM to perform co-adaptive reasoning via two complementary strategies: a high-level holistic plan and a context-grounded local policy. These strategies interact through a lightweight reflection mechanism, where the agent continuously assesses progress via a Strategy Fitness Score and dynamically revises its global plan when stuck or refines it upon meaningful advancement, mimicking human metacognitive behavior. On ALFWorld and Mind2Web, DuSAR achieves state-of-the-art performance with open-source LLMs (7B-70B), reaching 37.1% success on ALFWorld (Llama3.1-70B) - more than doubling the best prior result (13.0%) - and 4.02% on Mind2Web, also more than doubling the strongest baseline. Remarkably, it reduces per-step token consumption by 3-9X while maintaining strong performance. Ablation studies confirm the necessity of dual-strategy coordination. Moreover, optional integration of expert demonstrations further boosts results, highlighting DuSAR's flexibility and compatibility with external knowledge.
There are no more papers matching your filters at the moment.
