Ask or search anything...
 Shanghai Jiao Tong University
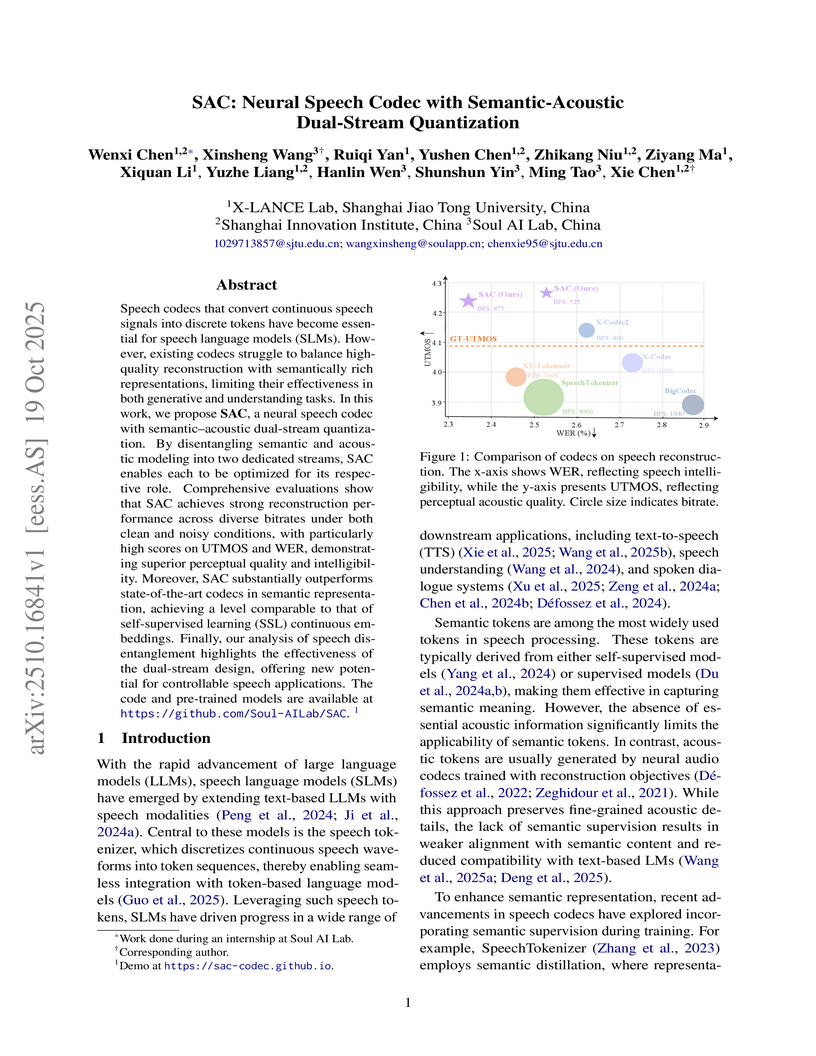
Shanghai Jiao Tong UniversitySAC is a neural speech codec that introduces a semantic-acoustic dual-stream quantization design, explicitly disentangling linguistic content from acoustic details. This architecture achieves high-fidelity speech reconstruction and robust semantic representation simultaneously, surpassing existing methods in both domains.
View blog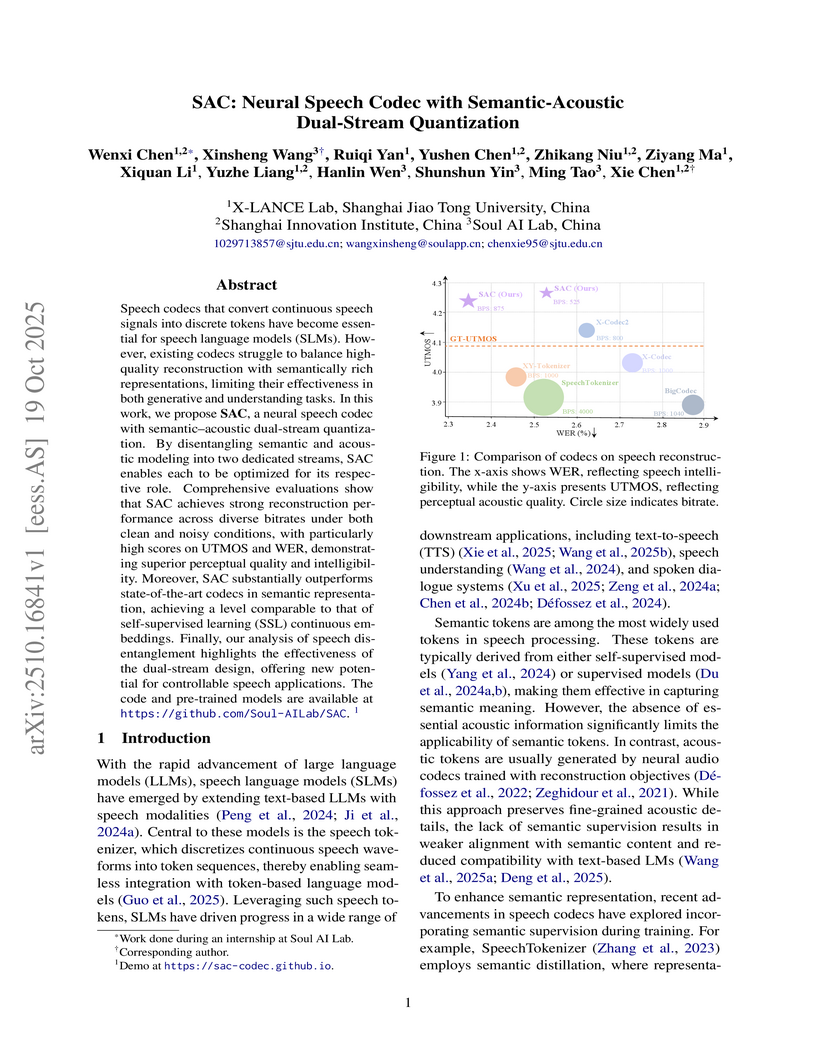
SoulX-Podcast introduces an LLM-driven generative framework for creating realistic, long-form, multi-speaker podcasts, incorporating diverse Chinese dialects and controllable paralinguistic cues. The system achieves state-of-the-art performance in multi-turn dialogue synthesis, exhibiting the lowest Character Error Rate (2.20) and highest cross-speaker consistency (0.599) on the Chinese ZipVoice-Dia benchmark, alongside strong zero-shot monologue capabilities.
View blog
 HKUST
HKUSTResearchers at HKUST and Soul AI Lab developed UniSS, a unified single-stage framework that leverages an off-the-shelf LLM with cross-modal Chain-of-Thought prompting for expressive speech-to-speech translation. This system achieves state-of-the-art performance across translation fidelity, speech quality, and the preservation of speaker identity and emotion, supported by the introduction of the large-scale UniST dataset.
View blog