
10 Dec 2025

Recent advances in video generation have been remarkable, enabling models to produce visually compelling videos with synchronized audio. While existing video generation benchmarks provide comprehensive metrics for visual quality, they lack convincing evaluations for audio-video generation, especially for models aiming to generate synchronized audio-video outputs. To address this gap, we introduce VABench, a comprehensive and multi-dimensional benchmark framework designed to systematically evaluate the capabilities of synchronous audio-video generation. VABench encompasses three primary task types: text-to-audio-video (T2AV), image-to-audio-video (I2AV), and stereo audio-video generation. It further establishes two major evaluation modules covering 15 dimensions. These dimensions specifically assess pairwise similarities (text-video, text-audio, video-audio), audio-video synchronization, lip-speech consistency, and carefully curated audio and video question-answering (QA) pairs, among others. Furthermore, VABench covers seven major content categories: animals, human sounds, music, environmental sounds, synchronous physical sounds, complex scenes, and virtual worlds. We provide a systematic analysis and visualization of the evaluation results, aiming to establish a new standard for assessing video generation models with synchronous audio capabilities and to promote the comprehensive advancement of the field.

08 Dec 2025
Lightweight, real-time text-to-speech systems are crucial for accessibility. However, the most efficient TTS models often rely on lightweight phonemizers that struggle with context-dependent challenges. In contrast, more advanced phonemizers with a deeper linguistic understanding typically incur high computational costs, which prevents real-time performance.
This paper examines the trade-off between phonemization quality and inference speed in G2P-aided TTS systems, introducing a practical framework to bridge this gap. We propose lightweight strategies for context-aware phonemization and a service-oriented TTS architecture that executes these modules as independent services. This design decouples heavy context-aware components from the core TTS engine, effectively breaking the latency barrier and enabling real-time use of high-quality phonemization models. Experimental results confirm that the proposed system improves pronunciation soundness and linguistic accuracy while maintaining real-time responsiveness, making it well-suited for offline and end-device TTS applications.

08 Dec 2025
A two-stage self-supervised framework integrates the Joint-Embedding Predictive Architecture (JEPA) with Density Adaptive Attention Mechanisms (DAAM) to learn robust speech representations. This approach generates efficient, reversible discrete speech tokens at an ultra-low rate of 47.5 tokens/sec, designed for seamless integration with large language models.

08 Dec 2025
An unsupervised framework for single-channel audio separation, developed at the Institute of Science Tokyo, employs diffusion models as source priors for disentangling sound sources from a single-microphone recording. The method incorporates a novel hybrid guidance schedule and noise-augmented mixture initialization, achieving separation quality comparable to the supervised Conv-TasNet model and outperforming previous unsupervised methods without requiring paired training data.

10 Dec 2025

Generating lifelike conversational avatars requires modeling not just isolated speakers, but the dynamic, reciprocal interaction of speaking and listening. However, modeling the listener is exceptionally challenging: direct audio-driven training fails, producing stiff, static listening motions. This failure stems from a fundamental imbalance: the speaker's motion is strongly driven by speech audio, while the listener's motion primarily follows an internal motion prior and is only loosely guided by external speech. This challenge has led most methods to focus on speak-only generation. The only prior attempt at joint generation relies on extra speaker's motion to produce the listener. This design is not end-to-end, thereby hindering the real-time applicability. To address this limitation, we present UniLS, the first end-to-end framework for generating unified speak-listen expressions, driven by only dual-track audio. Our method introduces a novel two-stage training paradigm. Stage 1 first learns the internal motion prior by training an audio-free autoregressive generator, capturing the spontaneous dynamics of natural facial motion. Stage 2 then introduces the dual-track audio, fine-tuning the generator to modulate the learned motion prior based on external speech cues. Extensive evaluations show UniLS achieves state-of-the-art speaking accuracy. More importantly, it delivers up to 44.1\% improvement in listening metrics, generating significantly more diverse and natural listening expressions. This effectively mitigates the stiffness problem and provides a practical, high-fidelity audio-driven solution for interactive digital humans.

08 Dec 2025
The increasing use of synthetic media, particularly deepfakes, is an emerging challenge for digital content verification. Although recent studies use both audio and visual information, most integrate these cues within a single model, which remains vulnerable to modality mismatches, noise, and manipulation. To address this gap, we propose DeepAgent, an advanced multi-agent collaboration framework that simultaneously incorporates both visual and audio modalities for the effective detection of deepfakes. DeepAgent consists of two complementary agents. Agent-1 examines each video with a streamlined AlexNet-based CNN to identify the symbols of deepfake manipulation, while Agent-2 detects audio-visual inconsistencies by combining acoustic features, audio transcriptions from Whisper, and frame-reading sequences of images through EasyOCR. Their decisions are fused through a Random Forest meta-classifier that improves final performance by taking advantage of the different decision boundaries learned by each agent. This study evaluates the proposed framework using three benchmark datasets to demonstrate both component-level and fused performance. Agent-1 achieves a test accuracy of 94.35% on the combined Celeb-DF and FakeAVCeleb datasets. On the FakeAVCeleb dataset, Agent-2 and the final meta-classifier attain accuracies of 93.69% and 81.56%, respectively. In addition, cross-dataset validation on DeepFakeTIMIT confirms the robustness of the meta-classifier, which achieves a final accuracy of 97.49%, and indicates a strong capability across diverse datasets. These findings confirm that hierarchy-based fusion enhances robustness by mitigating the weaknesses of individual modalities and demonstrate the effectiveness of a multi-agent approach in addressing diverse types of manipulations in deepfakes.

09 Dec 2025
Audio deepfake detection has recently garnered public concern due to its implications for security and reliability. Traditional deep learning methods have been widely applied to this task but often lack generalisability when confronted with newly emerging spoofing techniques and more tasks such as spoof attribution recognition rather than simple binary classification. In principle, Large Language Models (LLMs) are considered to possess the needed generalisation capabilities. However, previous research on Audio LLMs (ALLMs) indicates a generalization bottleneck in audio deepfake detection performance, even when sufficient data is available. Consequently, this study investigates the model architecture and examines the effects of the primary components of ALLMs, namely the audio encoder and the text-based LLM. Our experiments demonstrate that the careful selection and combination of audio encoders and text-based LLMs are crucial for unlocking the deepfake detection potential of ALLMs. We further propose an ALLM structure capable of generalizing deepfake detection abilities to out-of-domain spoofing tests and other deepfake tasks, such as spoof positioning and spoof attribution recognition. Our proposed model architecture achieves state-of-the-art (SOTA) performance across multiple datasets, including ASVSpoof2019, InTheWild, and Demopage, with accuracy reaching up to 95.76% on average, and exhibits competitive capabilities in other deepfake detection tasks such as attribution, and localisation compared to SOTA audio understanding models. Data and codes are provided in supplementary materials.

10 Dec 2025
Always-on sensors are increasingly expected to embark a variety of tiny neural networks and to continuously perform inference on time-series of the data they sense. In order to fit lifetime and energy consumption requirements when operating on battery, such hardware uses microcontrollers (MCUs) with tiny memory budget e.g., 128kB of RAM. In this context, optimizing data flows across neural network layers becomes crucial. In this paper, we introduce TinyDéjàVu, a new framework and novel algorithms we designed to drastically reduce the RAM footprint required by inference using various tiny ML models for sensor data time-series on typical microcontroller hardware. We publish the implementation of TinyDéjàVu as open source, and we perform reproducible benchmarks on hardware. We show that TinyDéjàVu can save more than 60% of RAM usage and eliminate up to 90% of redundant compute on overlapping sliding window inputs.

09 Dec 2025
Objective speech quality assessment is central to telephony, VoIP, and streaming systems, where large volumes of degraded audio must be monitored and optimized at scale. Classical metrics such as PESQ and POLQA approximate human mean opinion scores (MOS) but require carefully controlled conditions and expensive listening tests, while learning-based models such as NISQA regress MOS and multiple perceptual dimensions from waveforms or spectrograms, achieving high correlation with subjective ratings yet remaining rigid: they do not support interactive, natural-language queries and do not natively provide textual rationales. In this work, we introduce SpeechQualityLLM, a multimodal speech quality question-answering (QA) system that couples an audio encoder with a language model and is trained on the NISQA corpus using template-based question-answer pairs covering overall MOS and four perceptual dimensions (noisiness, coloration, discontinuity, and loudness) in both single-ended (degraded only) and double-ended (degraded plus clean reference) setups. Instead of directly regressing scores, our system is supervised to generate textual answers from which numeric predictions are parsed and evaluated with standard regression and ranking metrics; on held-out NISQA clips, the double-ended model attains a MOS mean absolute error (MAE) of 0.41 with Pearson correlation of 0.86, with competitive performance on dimension-wise tasks. Beyond these quantitative gains, it offers a flexible natural-language interface in which the language model acts as an audio quality expert: practitioners can query arbitrary aspects of degradations, prompt the model to emulate different listener profiles to capture human variability and produce diverse but plausible judgments rather than a single deterministic score, and thereby reduce reliance on large-scale crowdsourced tests and their monetary cost.

10 Dec 2025

Controllable text-to-speech (TTS) systems face significant challenges in achieving independent manipulation of speaker timbre and speaking style, often suffering from entanglement between these attributes. We present DMP-TTS, a latent Diffusion Transformer (DiT) framework with explicit disentanglement and multi-modal prompting. A CLAP-based style encoder (Style-CLAP) aligns cues from reference audio and descriptive text in a shared space and is trained with contrastive learning plus multi-task supervision on style attributes. For fine-grained control during inference, we introduce chained classifier-free guidance (cCFG) trained with hierarchical condition dropout, enabling independent adjustment of content, timbre, and style guidance strengths. Additionally, we employ Representation Alignment (REPA) to distill acoustic-semantic features from a pretrained Whisper model into intermediate DiT representations, stabilizing training and accelerating convergence. Experiments show that DMP-TTS delivers stronger style controllability than open-source baselines while maintaining competitive intelligibility and naturalness. Code and demos will be available at this https URL.

04 Dec 2025
M3-TTS, developed by researchers from Beijing Institute of Technology, Kuaishou Technology, and CASIA, introduces a Multi-Modal Diffusion Transformer (MM-DiT) for dynamic text-speech alignment and a Mel-VAE latent acoustic target, achieving state-of-the-art non-autoregressive (NAR) TTS performance with a 3x training speedup. The system records the lowest Word Error Rates (WER) among NAR models while maintaining high naturalness and enabling high-fidelity zero-shot speech synthesis.

08 Dec 2025
We introduce a novel pipeline for joint audio-visual editing that enhances the coherence between edited video and its accompanying audio. Our approach first applies state-of-the-art video editing techniques to produce the target video, then performs audio editing to align with the visual changes. To achieve this, we present a new video-to-audio generation model that conditions on the source audio, target video, and a text prompt. We extend the model architecture to incorporate conditional audio input and propose a data augmentation strategy that improves training efficiency. Furthermore, our model dynamically adjusts the influence of the source audio based on the complexity of the edits, preserving the original audio structure where possible. Experimental results demonstrate that our method outperforms existing approaches in maintaining audio-visual alignment and content integrity.

09 Dec 2025
Real-time speech communication over wireless networks remains challenging, as conventional channel protection mechanisms cannot effectively counter packet loss under stringent bandwidth and latency constraints. Semantic communication has emerged as a promising paradigm for enhancing the robustness of speech transmission by means of joint source-channel coding (JSCC). However, its cross-layer design hinders practical deployment due to the incompatibility with existing digital communication systems. In this case, the robustness of speech communication is consequently evaluated primarily by the error-resilience to packet loss over wireless networks. To address these challenges, we propose \emph{Glaris}, a generative latent-prior-based resilient speech semantic communication framework that performs resilient speech coding in the generative latent space. Generative latent priors enable high-quality packet loss concealment (PLC) at the receiver side, well-balancing semantic consistency and reconstruction fidelity. Additionally, an integrated error resilience mechanism is designed to mitigate the error propagation and improve the effectiveness of PLC. Compared with traditional packet-level forward error correction (FEC) strategies, our new method achieves enhanced robustness over dynamic wireless networks while reducing redundancy overhead significantly. Experimental results on the LibriSpeech dataset demonstrate that \emph{Glaris} consistently outperforms existing error-resilient codecs, achieving JSCC-level robustness while maintaining seamless compatibility with existing systems, and it also strikes a favorable balance between transmission efficiency and speech reconstruction quality.
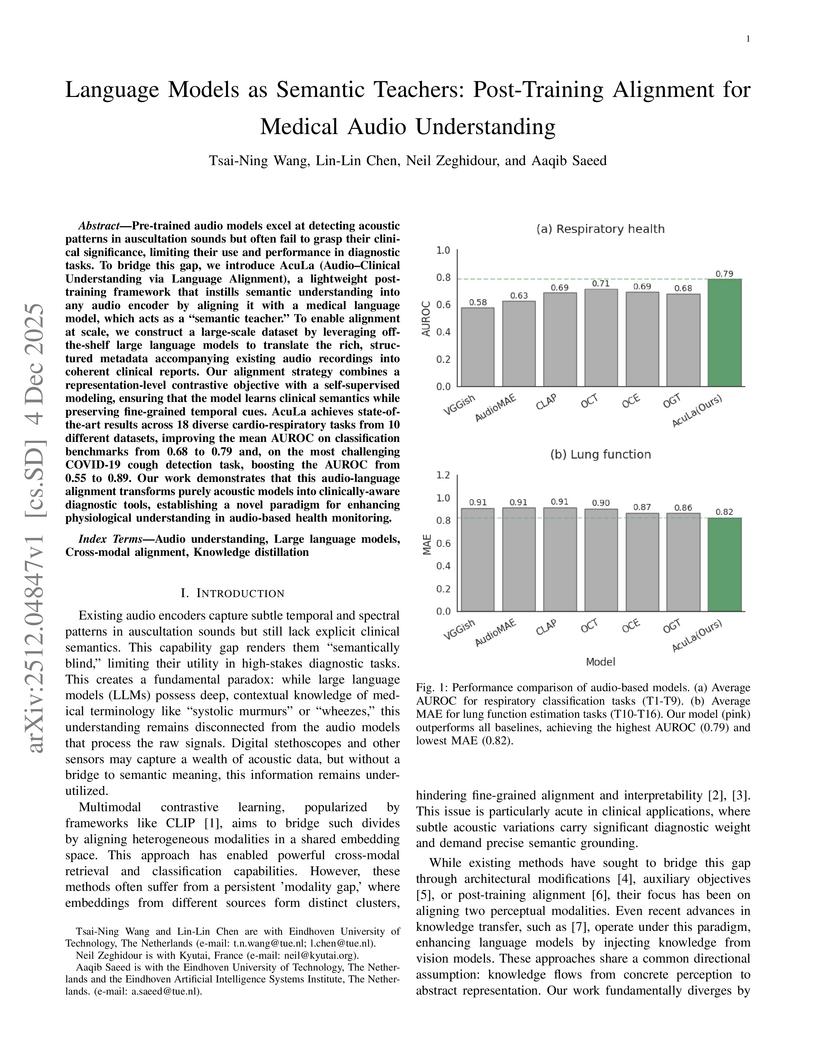
04 Dec 2025
Pre-trained audio models excel at detecting acoustic patterns in auscultation sounds but often fail to grasp their clinical significance, limiting their use and performance in diagnostic tasks. To bridge this gap, we introduce AcuLa (Audio-Clinical Understanding via Language Alignment), a lightweight post-training framework that instills semantic understanding into any audio encoder by aligning it with a medical language model, which acts as a "semantic teacher." To enable alignment at scale, we construct a large-scale dataset by leveraging off-the-shelf large language models to translate the rich, structured metadata accompanying existing audio recordings into coherent clinical reports. Our alignment strategy combines a representation-level contrastive objective with a self-supervised modeling, ensuring that the model learns clinical semantics while preserving fine-grained temporal cues. AcuLa achieves state-of-the-art results across 18 diverse cardio-respiratory tasks from 10 different datasets, improving the mean AUROC on classification benchmarks from 0.68 to 0.79 and, on the most challenging COVID-19 cough detection task, boosting the AUROC from 0.55 to 0.89. Our work demonstrates that this audio-language alignment transforms purely acoustic models into clinically-aware diagnostic tools, establishing a novel paradigm for enhancing physiological understanding in audio-based health monitoring.

04 Dec 2025
Voice authentication systems deployed at the network edge face dual threats: a) sophisticated deepfake synthesis attacks and b) control-plane poisoning in distributed federated learning protocols. We present a framework coupling physics-guided deepfake detection with uncertainty-aware in edge learning. The framework fuses interpretable physics features modeling vocal tract dynamics with representations coming from a self-supervised learning module. The representations are then processed via a Multi-Modal Ensemble Architecture, followed by a Bayesian ensemble providing uncertainty estimates. Incorporating physics-based characteristics evaluations and uncertainty estimates of audio samples allows our proposed framework to remain robust to both advanced deepfake attacks and sophisticated control-plane poisoning, addressing the complete threat model for networked voice authentication.

04 Dec 2025
The Omni-AutoThink framework enables large multimodal models to adaptively choose their reasoning depth based on task difficulty across text-only, text-audio, text-visual, and text-audio-visual inputs. It achieves improved accuracy over base models and larger models in many multimodal tasks, demonstrating higher reasoning rates for complex problems and lower rates for simpler ones.

27 Nov 2025
Recent advances in diffusion models have positioned them as powerful generative frameworks for speech synthesis, demonstrating substantial improvements in audio quality and stability. Nevertheless, their effectiveness in vocoders conditioned on mel spectrograms remains constrained, particularly when the conditioning diverges from the training distribution. The recently proposed GLA-Grad model introduced a phase-aware extension to the WaveGrad vocoder that integrated the Griffin-Lim algorithm (GLA) into the reverse process to reduce inconsistencies between generated signals and conditioning mel spectrogram. In this paper, we further improve GLA-Grad through an innovative choice in how to apply the correction. Particularly, we compute the correction term only once, with a single application of GLA, to accelerate the generation process. Experimental results demonstrate that our method consistently outperforms the baseline models, particularly in out-of-domain scenarios.

04 Dec 2025
The FAME 2026 challenge comprises two demanding tasks: training face-voice associations combined with a multilingual setting that includes testing on languages on which the model was not trained. Our approach consists of separate uni-modal processing pipelines with general face and voice feature extraction, complemented by additional age-gender feature extraction to support prediction. The resulting single-modal features are projected into a shared embedding space and trained with an Adaptive Angular Margin (AAM) loss. Our approach achieved first place in the FAME 2026 challenge, with an average Equal-Error Rate (EER) of 23.99%.

04 Dec 2025
Speech emotion recognition (SER) is an important technology in human-computer interaction. However, achieving high performance is challenging due to emotional complexity and scarce annotated data. To tackle these challenges, we propose a multi-loss learning (MLL) framework integrating an energy-adaptive mixup (EAM) method and a frame-level attention module (FLAM). The EAM method leverages SNR-based augmentation to generate diverse speech samples capturing subtle emotional variations. FLAM enhances frame-level feature extraction for multi-frame emotional cues. Our MLL strategy combines Kullback-Leibler divergence, focal, center, and supervised contrastive loss to optimize learning, address class imbalance, and improve feature separability. We evaluate our method on four widely used SER datasets: IEMOCAP, MSP-IMPROV, RAVDESS, and SAVEE. The results demonstrate our method achieves state-of-the-art performance, suggesting its effectiveness and robustness.

02 Dec 2025
This research presents a novel approach to enhancing automatic speech recognition systems by integrating noise detection capabilities directly into the recognition architecture. Building upon the wav2vec2 framework, the proposed method incorporates a dedicated noise identification module that operates concurrently with speech transcription. Experimental validation using publicly available speech and environmental audio datasets demonstrates substantial improvements in transcription quality and noise discrimination. The enhanced system achieves superior performance in word error rate, character error rate, and noise detection accuracy compared to conventional architectures. Results indicate that joint optimization of transcription and noise classification objectives yields more reliable speech recognition in challenging acoustic conditions.
There are no more papers matching your filters at the moment.
