Ask or search anything...
Beyond Paired Data: Self-Supervised UAV Geo-Localization from Reference Imagery Alone
02 Dec 2025
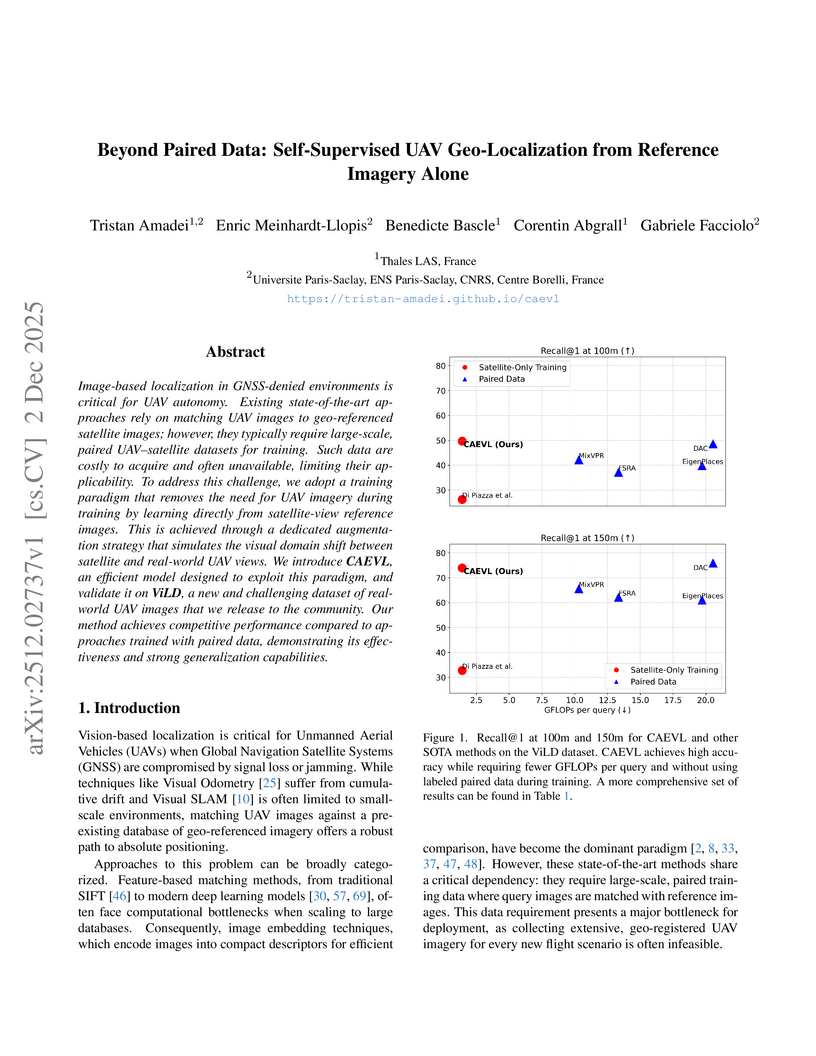
Image-based localization in GNSS-denied environments is critical for UAV autonomy. Existing state-of-the-art approaches rely on matching UAV images to geo-referenced satellite images; however, they typically require large-scale, paired UAV-satellite datasets for training. Such data are costly to acquire and often unavailable, limiting their applicability. To address this challenge, we adopt a training paradigm that removes the need for UAV imagery during training by learning directly from satellite-view reference images. This is achieved through a dedicated augmentation strategy that simulates the visual domain shift between satellite and real-world UAV views. We introduce CAEVL, an efficient model designed to exploit this paradigm, and validate it on ViLD, a new and challenging dataset of real-world UAV images that we release to the community. Our method achieves competitive performance compared to approaches trained with paired data, demonstrating its effectiveness and strong generalization capabilities.
Leveraging edge detection and neural networks for better UAV localization
01 Jun 2024
 CNRS
CNRSWe propose a novel method for geolocalizing Unmanned Aerial Vehicles (UAVs) in environments lacking Global Navigation Satellite Systems (GNSS). Current state-of-the-art techniques employ an offline-trained encoder to generate a vector representation (embedding) of the UAV's current view, which is then compared with pre-computed embeddings of geo-referenced images to determine the UAV's position. Here, we demonstrate that the performance of these methods can be significantly enhanced by preprocessing the images to extract their edges, which exhibit robustness to seasonal and illumination variations. Furthermore, we establish that utilizing edges enhances resilience to orientation and altitude inaccuracies. Additionally, we introduce a confidence criterion for localization. Our findings are substantiated through synthetic experiments.

Adapting MIMO video restoration networks to low latency constraints
22 Aug 2024
 City University of Hong Kong
City University of Hong KongMIMO (multiple input, multiple output) approaches are a recent trend in
neural network architectures for video restoration problems, where each network
evaluation produces multiple output frames. The video is split into
non-overlapping stacks of frames that are processed independently, resulting in
a very appealing trade-off between output quality and computational cost. In
this work we focus on the low-latency setting by limiting the number of
available future frames. We find that MIMO architectures suffer from problems
that have received little attention so far, namely (1) the performance drops
significantly due to the reduced temporal receptive field, particularly for
frames at the borders of the stack, (2) there are strong temporal
discontinuities at stack transitions which induce a step-wise motion artifact.
We propose two simple solutions to alleviate these problems: recurrence across
MIMO stacks to boost the output quality by implicitly increasing the temporal
receptive field, and overlapping of the output stacks to smooth the temporal
discontinuity at stack transitions. These modifications can be applied to any
MIMO architecture. We test them on three state-of-the-art video denoising
networks with different computational cost. The proposed contributions result
in a new state-of-the-art for low-latency networks, both in terms of
reconstruction error and temporal consistency. As an additional contribution,
we introduce a new benchmark consisting of drone footage that highlights
temporal consistency issues that are not apparent in the standard benchmarks.

There are no more papers matching your filters at the moment.