
28 Oct 2023

4K4D introduces a method for real-time 4D view synthesis, generating high-fidelity views of dynamic 3D scenes at 4K resolution. The approach achieves over 80 FPS at 4K and 400 FPS at 1080p on commodity hardware, significantly outperforming previous real-time dynamic neural rendering techniques.

29 Mar 2024

We propose FlashAvatar, a novel and lightweight 3D animatable avatar representation that could reconstruct a digital avatar from a short monocular video sequence in minutes and render high-fidelity photo-realistic images at 300FPS on a consumer-grade GPU. To achieve this, we maintain a uniform 3D Gaussian field embedded in the surface of a parametric face model and learn extra spatial offset to model non-surface regions and subtle facial details. While full use of geometric priors can capture high-frequency facial details and preserve exaggerated expressions, proper initialization can help reduce the number of Gaussians, thus enabling super-fast rendering speed. Extensive experimental results demonstrate that FlashAvatar outperforms existing works regarding visual quality and personalized details and is almost an order of magnitude faster in rendering speed. Project page: this https URL

11 Oct 2025
Existing for audio- and pose-driven human animation methods often struggle with stiff head movements and blurry hands, primarily due to the weak correlation between audio and head movements and the structural complexity of hands. To address these issues, we propose VividAnimator, an end-to-end framework for generating high-quality, half-body human animations driven by audio and sparse hand pose conditions. Our framework introduces three key innovations. First, to overcome the instability and high cost of online codebook training, we pre-train a Hand Clarity Codebook (HCC) that encodes rich, high-fidelity hand texture priors, significantly mitigating hand degradation. Second, we design a Dual-Stream Audio-Aware Module (DSAA) to model lip synchronization and natural head pose dynamics separately while enabling interaction. Third, we introduce a Pose Calibration Trick (PCT) that refines and aligns pose conditions by relaxing rigid constraints, ensuring smooth and natural gesture transitions. Extensive experiments demonstrate that Vivid Animator achieves state-of-the-art performance, producing videos with superior hand detail, gesture realism, and identity consistency, validated by both quantitative metrics and qualitative evaluations.

17 Aug 2023
This paper tackles the challenge of creating relightable and animatable neural avatars from sparse-view (or even monocular) videos of dynamic humans under unknown illumination. Compared to studio environments, this setting is more practical and accessible but poses an extremely challenging ill-posed problem. Previous neural human reconstruction methods are able to reconstruct animatable avatars from sparse views using deformed Signed Distance Fields (SDF) but cannot recover material parameters for relighting. While differentiable inverse rendering-based methods have succeeded in material recovery of static objects, it is not straightforward to extend them to dynamic humans as it is computationally intensive to compute pixel-surface intersection and light visibility on deformed SDFs for inverse rendering. To solve this challenge, we propose a Hierarchical Distance Query (HDQ) algorithm to approximate the world space distances under arbitrary human poses. Specifically, we estimate coarse distances based on a parametric human model and compute fine distances by exploiting the local deformation invariance of SDF. Based on the HDQ algorithm, we leverage sphere tracing to efficiently estimate the surface intersection and light visibility. This allows us to develop the first system to recover animatable and relightable neural avatars from sparse view (or monocular) inputs. Experiments demonstrate that our approach is able to produce superior results compared to state-of-the-art methods. Our code will be released for reproducibility.

18 Jan 2023
We propose a new method for object pose estimation without CAD models. The previous feature-matching-based method OnePose has shown promising results under a one-shot setting which eliminates the need for CAD models or object-specific training. However, OnePose relies on detecting repeatable image keypoints and is thus prone to failure on low-textured objects. We propose a keypoint-free pose estimation pipeline to remove the need for repeatable keypoint detection. Built upon the detector-free feature matching method LoFTR, we devise a new keypoint-free SfM method to reconstruct a semi-dense point-cloud model for the object. Given a query image for object pose estimation, a 2D-3D matching network directly establishes 2D-3D correspondences between the query image and the reconstructed point-cloud model without first detecting keypoints in the image. Experiments show that the proposed pipeline outperforms existing one-shot CAD-model-free methods by a large margin and is comparable to CAD-model-based methods on LINEMOD even for low-textured objects. We also collect a new dataset composed of 80 sequences of 40 low-textured objects to facilitate future research on one-shot object pose estimation. The supplementary material, code and dataset are available on the project page: this https URL.

12 Oct 2022
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consist of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair, wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model with only ten to twenty minutes, and can render a photo-realistic human head image in tens of miliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed. Demo videos and released code are provided in our project page: this https URL

25 May 2022

We are witnessing an explosion of neural implicit representations in computer
vision and graphics. Their applicability has recently expanded beyond tasks
such as shape generation and image-based rendering to the fundamental problem
of image-based 3D reconstruction. However, existing methods typically assume
constrained 3D environments with constant illumination captured by a small set
of roughly uniformly distributed cameras. We introduce a new method that
enables efficient and accurate surface reconstruction from Internet photo
collections in the presence of varying illumination. To achieve this, we
propose a hybrid voxel- and surface-guided sampling technique that allows for
more efficient ray sampling around surfaces and leads to significant
improvements in reconstruction quality. Further, we present a new benchmark and
protocol for evaluating reconstruction performance on such in-the-wild scenes.
We perform extensive experiments, demonstrating that our approach surpasses
both classical and neural reconstruction methods on a wide variety of metrics.

05 Apr 2022
We propose SelfRecon, a clothed human body reconstruction method that combines implicit and explicit representations to recover space-time coherent geometries from a monocular self-rotating human video. Explicit methods require a predefined template mesh for a given sequence, while the template is hard to acquire for a specific subject. Meanwhile, the fixed topology limits the reconstruction accuracy and clothing types. Implicit representation supports arbitrary topology and can represent high-fidelity geometry shapes due to its continuous nature. However, it is difficult to integrate multi-frame information to produce a consistent registration sequence for downstream applications. We propose to combine the advantages of both representations. We utilize differential mask loss of the explicit mesh to obtain the coherent overall shape, while the details on the implicit surface are refined with the differentiable neural rendering. Meanwhile, the explicit mesh is updated periodically to adjust its topology changes, and a consistency loss is designed to match both representations. Compared with existing methods, SelfRecon can produce high-fidelity surfaces for arbitrary clothed humans with self-supervised optimization. Extensive experimental results demonstrate its effectiveness on real captured monocular videos. The source code is available at this https URL.

04 May 2023

This paper addresses the challenge of reconstructing an animatable human
model from a multi-view video. Some recent works have proposed to decompose a
non-rigidly deforming scene into a canonical neural radiance field and a set of
deformation fields that map observation-space points to the canonical space,
thereby enabling them to learn the dynamic scene from images. However, they
represent the deformation field as translational vector field or SE(3) field,
which makes the optimization highly under-constrained. Moreover, these
representations cannot be explicitly controlled by input motions. Instead, we
introduce a pose-driven deformation field based on the linear blend skinning
algorithm, which combines the blend weight field and the 3D human skeleton to
produce observation-to-canonical correspondences. Since 3D human skeletons are
more observable, they can regularize the learning of the deformation field.
Moreover, the pose-driven deformation field can be controlled by input skeletal
motions to generate new deformation fields to animate the canonical human
model. Experiments show that our approach significantly outperforms recent
human modeling methods. The code is available at
this https URL
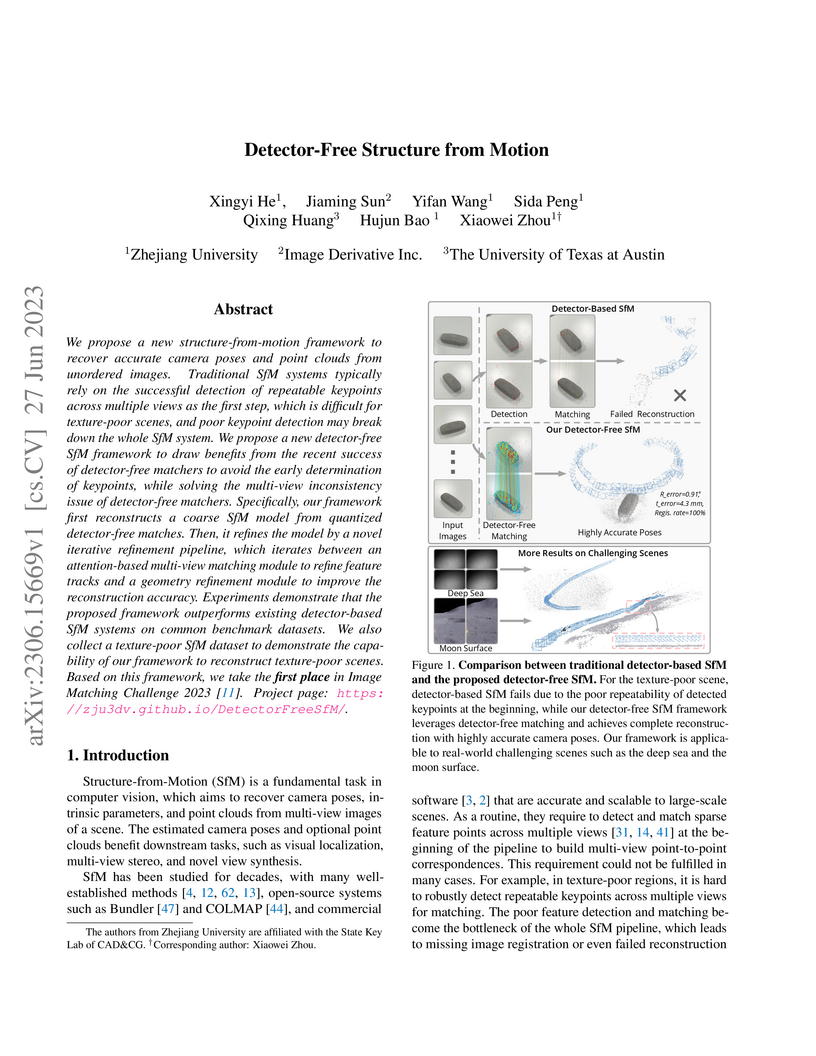
27 Jun 2023

A detector-free Structure from Motion framework enables robust and accurate 3D reconstruction of texture-poor environments. The method addresses multi-view inconsistency through a coarse reconstruction with grid quantization and an iterative refinement pipeline, which includes a multi-view feature transformer for enhanced feature localization, leading to first place in the Image Matching Challenge 2023.

03 Apr 2023
Collecting and labeling training data is one important step for learning-based methods because the process is time-consuming and biased. For face analysis tasks, although some generative models can be used to generate face data, they can only achieve a subset of generation diversity, reconstruction accuracy, 3D consistency, high-fidelity visual quality, and easy editability. One recent related work is the graphics-based generative method, but it can only render low realism head with high computation cost. In this paper, we propose MetaHead, a unified and full-featured controllable digital head engine, which consists of a controllable head radiance field(MetaHead-F) to super-realistically generate or reconstruct view-consistent 3D controllable digital heads and a generic top-down image generation framework LabelHead to generate digital heads consistent with the given customizable feature labels. Experiments validate that our controllable digital head engine achieves the state-of-the-art generation visual quality and reconstruction accuracy. Moreover, the generated labeled data can assist real training data and significantly surpass the labeled data generated by graphics-based methods in terms of training effect.
There are no more papers matching your filters at the moment.
