
11 Aug 2025

Object detection (OD) has become vital for numerous computer vision applications, but deploying it on resource-constrained IoT devices presents a significant challenge. These devices, often powered by energy-efficient microcontrollers, struggle to handle the computational load of deep learning-based OD models. This issue is compounded by the rapid proliferation of IoT devices, predicted to surpass 150 billion by 2030. TinyML offers a compelling solution by enabling OD on ultra-low-power devices, paving the way for efficient and real-time processing at the edge. Although numerous survey papers have been published on this topic, they often overlook the optimization challenges associated with deploying OD models in TinyML environments. To address this gap, this survey paper provides a detailed analysis of key optimization techniques for deploying OD models on resource-constrained devices. These techniques include quantization, pruning, knowledge distillation, and neural architecture search. Furthermore, we explore both theoretical approaches and practical implementations, bridging the gap between academic research and real-world edge artificial intelligence deployment. Finally, we compare the key performance indicators (KPIs) of existing OD implementations on microcontroller devices, highlighting the achieved maturity level of these solutions in terms of both prediction accuracy and efficiency. We also provide a public repository to continually track developments in this fast-evolving field: this https URL.
13 Apr 2025
This paper introduces a novel framework for designing efficient neural
network architectures specifically tailored to tiny machine learning (TinyML)
platforms. By leveraging large language models (LLMs) for neural architecture
search (NAS), a vision transformer (ViT)-based knowledge distillation (KD)
strategy, and an explainability module, the approach strikes an optimal balance
between accuracy, computational efficiency, and memory usage. The LLM-guided
search explores a hierarchical search space, refining candidate architectures
through Pareto optimization based on accuracy, multiply-accumulate operations
(MACs), and memory metrics. The best-performing architectures are further
fine-tuned using logits-based KD with a pre-trained ViT-B/16 model, which
enhances generalization without increasing model size. Evaluated on the
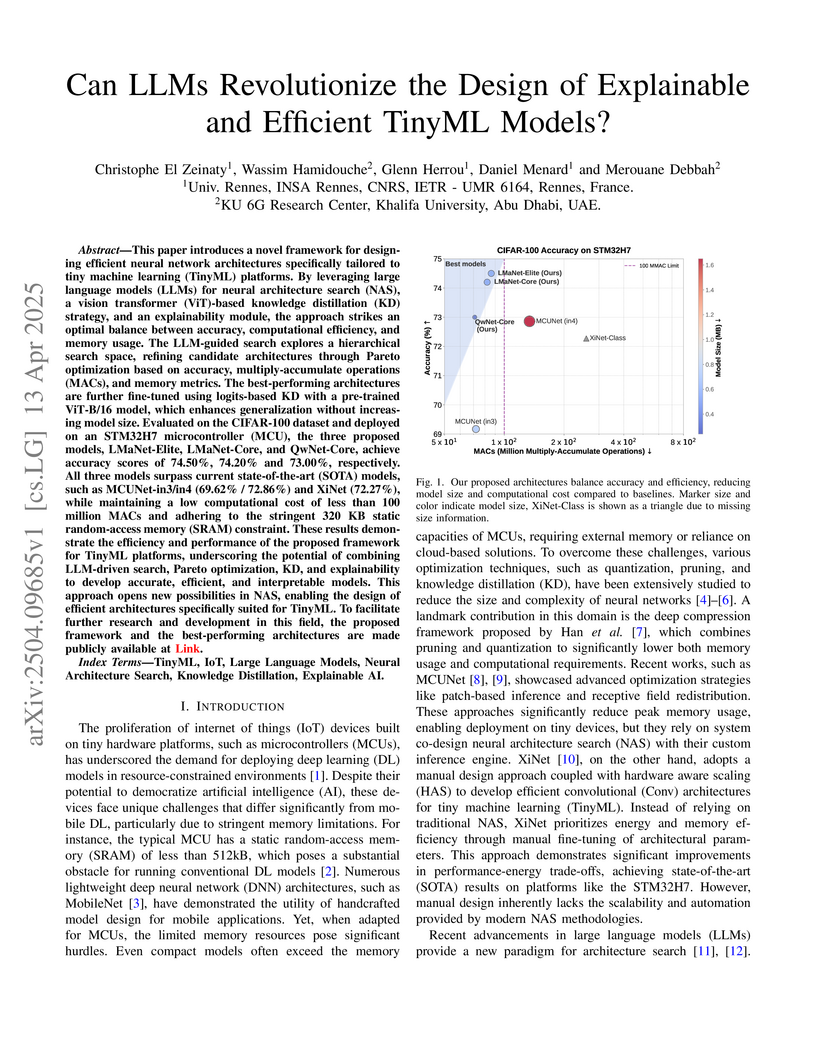
CIFAR-100 dataset and deployed on an STM32H7 microcontroller (MCU), the three
proposed models, LMaNet-Elite, LMaNet-Core, and QwNet-Core, achieve accuracy
scores of 74.50%, 74.20% and 73.00%, respectively. All three models surpass
current state-of-the-art (SOTA) models, such as MCUNet-in3/in4 (69.62% /
72.86%) and XiNet (72.27%), while maintaining a low computational cost of less
than 100 million MACs and adhering to the stringent 320 KB static random-access
memory (SRAM) constraint. These results demonstrate the efficiency and
performance of the proposed framework for TinyML platforms, underscoring the
potential of combining LLM-driven search, Pareto optimization, KD, and
explainability to develop accurate, efficient, and interpretable models. This
approach opens new possibilities in NAS, enabling the design of efficient
architectures specifically suited for TinyML.

02 Jul 2025


Multimodal fingerprinting is a crucial technique to sub-meter 6G integrated sensing and communications (ISAC) localization, but two hurdles block deployment: (i) the contribution each modality makes to the target position varies with the operating conditions such as carrier frequency, and (ii) spatial and fingerprint ambiguities markedly undermine localization accuracy, especially in non-line-of-sight (NLOS) scenarios. To solve these problems, we introduce SCADF-MoE, a spatial-context aware dynamic fusion network built on a soft mixture-of-experts backbone. SCADF-MoE first clusters neighboring points into short trajectories to inject explicit spatial context. Then, it adaptively fuses channel state information, angle of arrival profile, distance, and gain through its learnable MoE router, so that the most reliable cues dominate at each carrier band. The fused representation is fed to a modality-task MoE that simultaneously regresses the coordinates of every vertex in the trajectory and its centroid, thereby exploiting inter-point correlations. Finally, an auxiliary maximum-mean-discrepancy loss enforces expert diversity and mitigates gradient interference, stabilizing multi-task training. On three real urban layouts and three carrier bands (2.6, 6, 28 GHz), the model delivers consistent sub-meter MSE and halves unseen-NLOS error versus the best prior work. To our knowledge, this is the first work that leverages large-scale multimodal MoE for frequency-robust ISAC localization.
There are no more papers matching your filters at the moment.
