
10 Dec 2025

Recent research has developed several LLM architectures suitable for inference on end-user devices, such as the Mixture of Lookup Experts (MoLE)~\parencite{jie_mixture_2025}. A key feature of MoLE is that each token id is associated with a dedicated group of experts. For a given input, only the experts corresponding to the input token id will be activated. Since the communication overhead of loading this small number of activated experts into RAM during inference is negligible, expert parameters can be offloaded to storage, making MoLE suitable for resource-constrained devices. However, MoLE's context-independent expert selection mechanism, based solely on input ids, may limit model performance. To address this, we propose the \textbf{M}ixture \textbf{o}f \textbf{L}ookup \textbf{K}ey-\textbf{V}alue Experts (\textbf{MoLKV}) model. In MoLKV, each expert is structured as a key-value pair. For a given input, the input-derived query interacts with the cached key-value experts from the current sequence, generating a context-aware expert output. This context-aware mechanism alleviates the limitation of MoLE, and experimental results demonstrate that MoLKV achieves significantly lower validation loss in small-scale evaluations.

09 Dec 2025
Visionary introduces a WebGPU-powered platform for 3D Gaussian Splatting (3DGS) that enables real-time, client-side rendering and inference for dynamic and generative 3DGS models. The platform demonstrates up to 135x speedup compared to WebGL-based viewers, while maintaining or improving visual quality and ensuring robust depth-aware composition.

07 Dec 2025
ProAgent introduces an end-to-end proactive LLM agent system leveraging on-demand multi-modal sensory contexts from AR glasses to anticipate user needs without explicit commands. It achieved a 33.4% higher proactive accuracy and 16.8% higher F1-score for tool calling compared to existing baselines, while operating efficiently on edge devices.

08 Dec 2025
Lightweight, real-time text-to-speech systems are crucial for accessibility. However, the most efficient TTS models often rely on lightweight phonemizers that struggle with context-dependent challenges. In contrast, more advanced phonemizers with a deeper linguistic understanding typically incur high computational costs, which prevents real-time performance.
This paper examines the trade-off between phonemization quality and inference speed in G2P-aided TTS systems, introducing a practical framework to bridge this gap. We propose lightweight strategies for context-aware phonemization and a service-oriented TTS architecture that executes these modules as independent services. This design decouples heavy context-aware components from the core TTS engine, effectively breaking the latency barrier and enabling real-time use of high-quality phonemization models. Experimental results confirm that the proposed system improves pronunciation soundness and linguistic accuracy while maintaining real-time responsiveness, making it well-suited for offline and end-device TTS applications.

10 Dec 2025
Always-on sensors are increasingly expected to embark a variety of tiny neural networks and to continuously perform inference on time-series of the data they sense. In order to fit lifetime and energy consumption requirements when operating on battery, such hardware uses microcontrollers (MCUs) with tiny memory budget e.g., 128kB of RAM. In this context, optimizing data flows across neural network layers becomes crucial. In this paper, we introduce TinyDéjàVu, a new framework and novel algorithms we designed to drastically reduce the RAM footprint required by inference using various tiny ML models for sensor data time-series on typical microcontroller hardware. We publish the implementation of TinyDéjàVu as open source, and we perform reproducible benchmarks on hardware. We show that TinyDéjàVu can save more than 60% of RAM usage and eliminate up to 90% of redundant compute on overlapping sliding window inputs.

08 Dec 2025
Convolutional Neural Networks (CNNs) have proven highly effective for edge and mobile vision tasks due to their computational efficiency. While many recent works seek to enhance CNNs with global contextual understanding via self-attention-based Vision Transformers, these approaches often introduce significant computational overhead. In this work, we demonstrate that it is possible to retain strong global perception without relying on computationally expensive components. We present GlimmerNet, an ultra-lightweight convolutional network built on the principle of separating receptive field diversity from feature recombination. GlimmerNet introduces Grouped Dilated Depthwise Convolutions(GDBlocks), which partition channels into groups with distinct dilation rates, enabling multi-scale feature extraction at no additional parameter cost. To fuse these features efficiently, we design a novel Aggregator module that recombines cross-group representations using grouped pointwise convolution, significantly lowering parameter overhead. With just 31K parameters and 29% fewer FLOPs than the most recent baseline, GlimmerNet achieves a new state-of-the-art weighted F1-score of 0.966 on the UAV-focused AIDERv2 dataset. These results establish a new accuracy-efficiency trade-off frontier for real-time emergency monitoring on resource-constrained UAV platforms. Our implementation is publicly available at this https URL.

10 Dec 2025
Low-power microcontroller (MCU) hardware is currently evolving from single-core architectures to predominantly multi-core architectures. In parallel, new embedded software building blocks are more and more written in Rust, while C/C++ dominance fades in this domain. On the other hand, small artificial neural networks (ANN) of various kinds are increasingly deployed in edge AI use cases, thus deployed and executed directly on low-power MCUs. In this context, both incremental improvements and novel innovative services will have to be continuously retrofitted using ANNs execution in software embedded on sensing/actuating systems already deployed in the field. However, there was so far no Rust embedded software platform automating parallelization for inference computation on multi-core MCUs executing arbitrary TinyML models. This paper thus fills this gap by introducing Ariel-ML, a novel toolkit we designed combining a generic TinyML pipeline and an embedded Rust software platform which can take full advantage of multi-core capabilities of various 32bit microcontroller families (Arm Cortex-M, RISC-V, ESP-32). We published the full open source code of its implementation, which we used to benchmark its capabilities using a zoo of various TinyML models. We show that Ariel-ML outperforms prior art in terms of inference latency as expected, and we show that, compared to pre-existing toolkits using embedded C/C++, Ariel-ML achieves comparable memory footprints. Ariel-ML thus provides a useful basis for TinyML practitioners and resource-constrained embedded Rust developers.

10 Dec 2025
Estimating the 6-degrees-of-freedom (6DoF) pose of a spacecraft from a single image is critical for autonomous operations like in-orbit servicing and space debris removal. Existing state-of-the-art methods often rely on iterative Perspective-n-Point (PnP)-based algorithms, which are computationally intensive and ill-suited for real-time deployment on resource-constrained edge devices. To overcome these limitations, we propose FastPose-ViT, a Vision Transformer (ViT)-based architecture that directly regresses the 6DoF pose. Our approach processes cropped images from object bounding boxes and introduces a novel mathematical formalism to map these localized predictions back to the full-image scale. This formalism is derived from the principles of projective geometry and the concept of "apparent rotation", where the model predicts an apparent rotation matrix that is then corrected to find the true orientation. We demonstrate that our method outperforms other non-PnP strategies and achieves performance competitive with state-of-the-art PnP-based techniques on the SPEED dataset. Furthermore, we validate our model's suitability for real-world space missions by quantizing it and deploying it on power-constrained edge hardware. On the NVIDIA Jetson Orin Nano, our end-to-end pipeline achieves a latency of ~75 ms per frame under sequential execution, and a non-blocking throughput of up to 33 FPS when stages are scheduled concurrently.

10 Dec 2025
Physics-Informed Neural Networks (PINNs) have emerged as a promising paradigm for solving partial differential equations (PDEs) by embedding physical laws into neural network training objectives. However, their deployment on resource-constrained platforms is hindered by substantial computational and memory overhead, primarily stemming from higher-order automatic differentiation, intensive tensor operations, and reliance on full-precision arithmetic. To address these challenges, we present a framework that enables scalable and energy-efficient PINN training on edge devices. This framework integrates fully quantized training, Stein's estimator (SE)-based residual loss computation, and tensor-train (TT) decomposition for weight compression. It contributes three key innovations: (1) a mixed-precision training method that use a square-block MX (SMX) format to eliminate data duplication during backpropagation; (2) a difference-based quantization scheme for the Stein's estimator that mitigates underflow; and (3) a partial-reconstruction scheme (PRS) for TT-Layers that reduces quantization-error accumulation. We further design PINTA, a precision-scalable hardware accelerator, to fully exploit the performance of the framework. Experiments on the 2-D Poisson, 20-D Hamilton-Jacobi-Bellman (HJB), and 100-D Heat equations demonstrate that the proposed framework achieves accuracy comparable to or better than full-precision, uncompressed baselines while delivering 5.5x to 83.5x speedups and 159.6x to 2324.1x energy savings. This work enables real-time PDE solving on edge devices and paves the way for energy-efficient scientific computing at scale.

04 Dec 2025

MemLoRA introduces a framework for deploying memory-augmented conversational AI systems directly on edge devices by distilling specialized expert adapters into small language models. This approach reduces memory and computational costs by 10-20x while achieving performance comparable to cloud-based large models, and MemLoRA-V further enables native visual understanding with high accuracy.
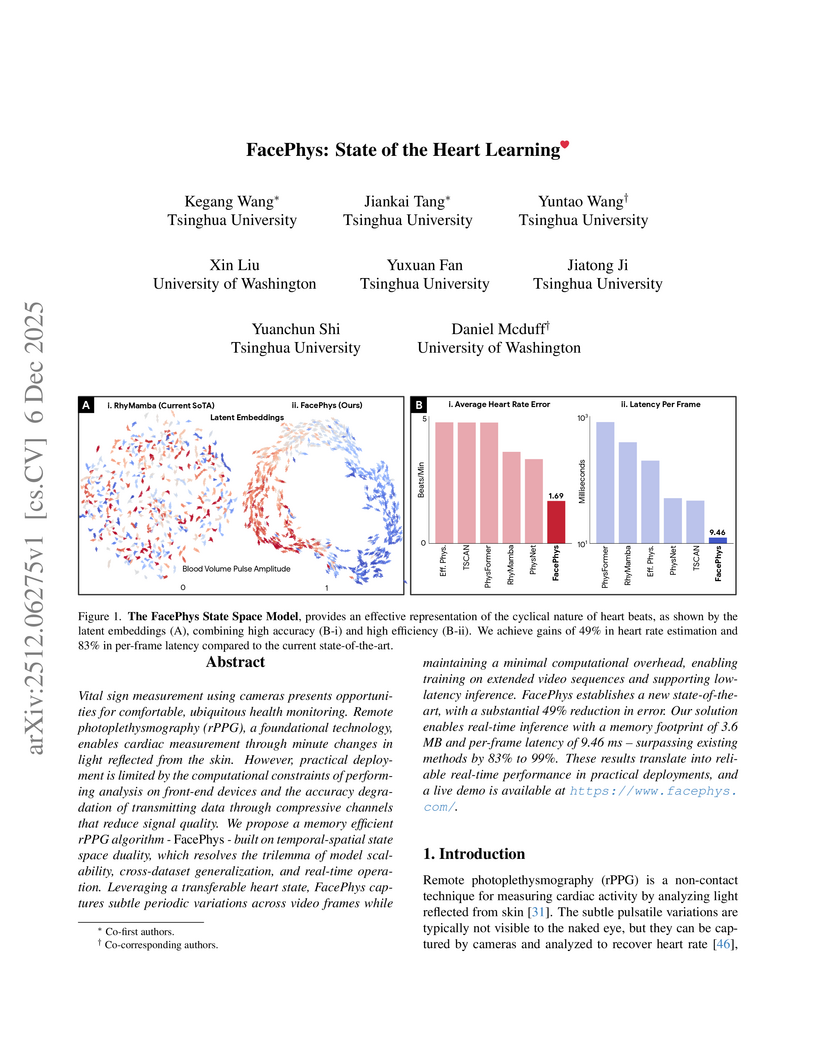
06 Dec 2025
Vital sign measurement using cameras presents opportunities for comfortable, ubiquitous health monitoring. Remote photoplethysmography (rPPG), a foundational technology, enables cardiac measurement through minute changes in light reflected from the skin. However, practical deployment is limited by the computational constraints of performing analysis on front-end devices and the accuracy degradation of transmitting data through compressive channels that reduce signal quality. We propose a memory efficient rPPG algorithm - \emph{FacePhys} - built on temporal-spatial state space duality, which resolves the trilemma of model scalability, cross-dataset generalization, and real-time operation. Leveraging a transferable heart state, FacePhys captures subtle periodic variations across video frames while maintaining a minimal computational overhead, enabling training on extended video sequences and supporting low-latency inference. FacePhys establishes a new state-of-the-art, with a substantial 49\% reduction in error. Our solution enables real-time inference with a memory footprint of 3.6 MB and per-frame latency of 9.46 ms -- surpassing existing methods by 83\% to 99\%. These results translate into reliable real-time performance in practical deployments, and a live demo is available at this https URL.

09 Dec 2025
The rise of space AI is reshaping government and industry through applications such as disaster detection, border surveillance, and climate monitoring, powered by massive data from commercial and governmental low Earth orbit (LEO) satellites. Federated satellite learning (FSL) enables joint model training without sharing raw data, but suffers from slow convergence due to intermittent connectivity and introduces critical trust challenges--where biased or falsified updates can arise across satellite constellations, including those injected through cyberattacks on inter-satellite or satellite-ground communication links. We propose OrbitChain, a blockchain-backed framework that empowers trustworthy multi-vendor collaboration in LEO networks. OrbitChain (i) offloads consensus to high-altitude platforms (HAPs) with greater computational capacity, (ii) ensures transparent, auditable provenance of model updates from different orbits owned by different vendors, and (iii) prevents manipulated or incomplete contributions from affecting global FSL model aggregation. Extensive simulations show that OrbitChain reduces computational and communication overhead while improving privacy, security, and global model accuracy. Its permissioned proof-of-authority ledger finalizes over 1000 blocks with sub-second latency (0.16,s, 0.26,s, 0.35,s for 1-of-5, 3-of-5, and 5-of-5 quorums). Moreover, OrbitChain reduces convergence time by up to 30 hours on real satellite datasets compared to single-vendor, demonstrating its effectiveness for real-time, multi-vendor learning. Our code is available at this https URL

09 Dec 2025
MobileFineTuner introduces a C++ native, end-to-end framework enabling Large Language Model fine-tuning directly on commodity mobile phones. It achieves model quality comparable to server-side training while integrating system-level optimizations that address the memory and energy constraints of mobile devices.

10 Dec 2025
Responsive and accurate facial expression recognition is crucial to human-robot interaction for daily service robots. Nowadays, event cameras are becoming more widely adopted as they surpass RGB cameras in capturing facial expression changes due to their high temporal resolution, low latency, computational efficiency, and robustness in low-light conditions. Despite these advantages, event-based approaches still encounter practical challenges, particularly in adopting mainstream deep learning models. Traditional deep learning methods for facial expression analysis are energy-intensive, making them difficult to deploy on edge computing devices and thereby increasing costs, especially for high-frequency, dynamic, event vision-based approaches. To address this challenging issue, we proposed the CS3D framework by decomposing the Convolutional 3D method to reduce the computational complexity and energy consumption. Additionally, by utilizing soft spiking neurons and a spatial-temporal attention mechanism, the ability to retain information is enhanced, thus improving the accuracy of facial expression detection. Experimental results indicate that our proposed CS3D method attains higher accuracy on multiple datasets compared to architectures such as the RNN, Transformer, and C3D, while the energy consumption of the CS3D method is just 21.97\% of the original C3D required on the same device.

04 Dec 2025
Object detection constitutes the primary task within the domain of computer vision. It is utilized in numerous domains. Nonetheless, object detection continues to encounter the issue of catastrophic forgetting. The model must be retrained whenever new products are introduced, utilizing not only the new products dataset but also the entirety of the previous dataset. The outcome is obvious: increasing model training expenses and significant time consumption. In numerous sectors, particularly retail checkout, the frequent introduction of new products presents a great challenge. This study introduces You Only Train Once (YOTO), a methodology designed to address the issue of catastrophic forgetting by integrating YOLO11n for object localization with DeIT and Proxy Anchor Loss for feature extraction and metric learning. For classification, we utilize cosine similarity between the embedding features of the target product and those in the Qdrant vector database. In a case study conducted in a retail store with 140 products, the experimental results demonstrate that our proposed framework achieves encouraging accuracy, whether for detecting new or existing products. Furthermore, without retraining, the training duration difference is significant. We achieve almost 3 times the training time efficiency compared to classical object detection approaches. This efficiency escalates as additional new products are added to the product database. The average inference time is 580 ms per image containing multiple products, on an edge device, validating the proposed framework's feasibility for practical use.

03 Dec 2025
Binary Neural Networks (BNNs), which constrain both weights and activations to binary values, offer substantial reductions in computational complexity, memory footprint, and energy consumption. These advantages make them particularly well suited for deployment on resource-constrained devices. However, training BNNs via gradient-based optimization remains challenging due to the discrete nature of their variables. The dominant approach, quantization-aware training, circumvents this issue by employing surrogate gradients. Yet, this method requires maintaining latent full-precision parameters and performing the backward pass with floating-point arithmetic, thereby forfeiting the efficiency of binary operations during training. While alternative approaches based on local learning rules exist, they are unsuitable for global credit assignment and for back-propagating errors in multi-layer architectures. This paper introduces Binary Error Propagation (BEP), the first learning algorithm to establish a principled, discrete analog of the backpropagation chain rule. This mechanism enables error signals, represented as binary vectors, to be propagated backward through multiple layers of a neural network. BEP operates entirely on binary variables, with all forward and backward computations performed using only bitwise operations. Crucially, this makes BEP the first solution to enable end-to-end binary training for recurrent neural network architectures. We validate the effectiveness of BEP on both multi-layer perceptrons and recurrent neural networks, demonstrating gains of up to +6.89% and +10.57% in test accuracy, respectively. The proposed algorithm is released as an open-source repository.

30 Nov 2025
SpeContext, developed by researchers at Shanghai Jiao Tong University, introduces an algorithm and system co-design that uses a lightweight distilled model for speculative KV cache sparsity, enabling efficient long-context reasoning in LLMs. The approach achieves up to 24.89x throughput improvement in cloud environments and 10.06x speedup on edge GPUs while maintaining accuracy.

04 Dec 2025
Voice authentication systems deployed at the network edge face dual threats: a) sophisticated deepfake synthesis attacks and b) control-plane poisoning in distributed federated learning protocols. We present a framework coupling physics-guided deepfake detection with uncertainty-aware in edge learning. The framework fuses interpretable physics features modeling vocal tract dynamics with representations coming from a self-supervised learning module. The representations are then processed via a Multi-Modal Ensemble Architecture, followed by a Bayesian ensemble providing uncertainty estimates. Incorporating physics-based characteristics evaluations and uncertainty estimates of audio samples allows our proposed framework to remain robust to both advanced deepfake attacks and sophisticated control-plane poisoning, addressing the complete threat model for networked voice authentication.

28 Nov 2025
The Liquid AI Team introduces LFM2, a family of foundation models designed for efficient on-device deployment, demonstrating up to 2x faster inference on CPUs compared to similarly sized models while achieving strong performance across language, vision-language, speech, and retrieval tasks. These models leverage a hardware-in-the-loop architectural search to optimize for latency, memory, and quality under strict edge constraints.

03 Dec 2025
KVNAND is the first architecture to enable entirely DRAM-free, on-device Large Language Model (LLM) inference by integrating both model weights and the dynamic Key-Value (KV) cache within compute-enabled 3D NAND flash. This approach resolves out-of-memory issues for long contexts up to 100K tokens, achieving geomean speedups up to 2.05x and reducing memory costs by 69% compared to DRAM-based solutions.
There are no more papers matching your filters at the moment.
