
14 Nov 2024



This review paper from NVIDIA Corporation and a consortium of leading institutions comprehensively surveys how Artificial Intelligence (AI) techniques are applied across the entire quantum computing stack, from hardware design to error correction. The work demonstrates that AI is critical for overcoming scaling challenges and accelerating the development of fault-tolerant quantum systems.

08 Oct 2025

Fault-tolerant Quantum Processing Units (QPUs) promise to deliver exponential speed-ups in select computational tasks, yet their integration into modern deep learning pipelines remains unclear. In this work, we take a step towards bridging this gap by presenting the first fully-coherent quantum implementation of a multilayer neural network with non-linear activation functions. Our constructions mirror widely used deep learning architectures based on ResNet, and consist of residual blocks with multi-filter 2D convolutions, sigmoid activations, skip-connections, and layer normalizations. We analyse the complexity of inference for networks under three quantum data access regimes. Without any assumptions, we establish a quadratic speedup over classical methods for shallow bilinear-style networks. With efficient quantum access to the weights, we obtain a quartic speedup over classical methods. With efficient quantum access to both the inputs and the network weights, we prove that a network with an -dimensional vectorized input, residual block layers, and a final residual-linear-pooling layer can be implemented with an error of with inference cost.

28 Dec 2023
The paper offers a comprehensive review of Quantum Error Mitigation (QEM) techniques, detailing their theoretical foundations, practical implementations, and role in enabling accurate calculations on current noisy quantum hardware. It highlights that QEM can reduce noise-induced bias in expectation values, but typically incurs an exponential sampling overhead, and also uniquely addresses algorithmic errors not covered by quantum error correction.

17 Jan 2025
With the successful demonstration of transversal CNOTs in many recent experiments, it is the right moment to examine its implications on one of the most critical parts of fault-tolerant computation -- magic state preparation. Using an algorithm that can recompile and simplify a circuit of consecutive multi-qubit phase rotations, we manage to construct fault-tolerant circuits for CCZ, CS and T states with minimal T-depth and also much lower CNOT depths and qubit counts than before. These circuits can play crucial roles in fault-tolerant computation with transversal CNOTs, and we hope that the algorithms and methods developed in this paper can be used to further simplify other protocols in similar contexts.

06 Oct 2025
Classical error-correcting codes are powerful but incompatible with quantum noise, which includes both bit-flips and phase-flips. We introduce Hadamard-based Virtual Error Correction (H-VEC), a protocol that empowers any classical bit-flip code to correct arbitrary Pauli noise with the addition of only a single ancilla qubit and two layers of controlled-Hadamard gates. Through classical post-processing, H-VEC virtually filters the error channel, projecting the noise into pure Y-type errors that are subsequently corrected using the classical code's native decoding algorithm. We demonstrate this by applying H-VEC to the classical repetition code. Under a code-capacity noise model, the resulting protocol not only provides full quantum protection but also achieves an exponentially stronger error suppression (in distance) than the original classical code, and even larger improvements over the surface code while using much fewer qubits, simpler checks and straight-forward decoding. H-VEC comes with a sampling overhead due to its post-processing nature. It represents a new hybrid quantum error correction and mitigation framework that redefines the trade-offs between physical hardware requirements and classical processing for error suppression.

15 Dec 2024

The paper introduces the Choi channel representation, a universal method to map arbitrary non-Markovian quantum dynamics to a conventional quantum channel. This framework enables the direct application of existing Markovian noise suppression protocols, such as Pauli twirling, probabilistic error cancellation, and virtual channel purification, to address complex time-correlated noise.

28 Jul 2025

State-of-the-art quantum processors have recently grown to reach 100s of physical qubits. As the number of qubits continues to grow, new challenges associated with scaling arise, such as device variability reduction and integration with cryogenic electronics for I/O management. Spin qubits in silicon quantum dots provide a platform where these problems may be mitigated, having demonstrated high control and readout fidelities and compatibility with large-scale manufacturing techniques of the semiconductor industry. Here, we demonstrate the monolithic integration of 384 p-type quantum dots, each embedded in a silicon transistor, with on-chip digital and analog electronics, all operating at deep cryogenic temperatures. The chip is fabricated using 22-nm fully-depleted silicon-on-insulator (FDSOI) CMOS technology. We extract key quantum dot parameters by fast readout and automated machine learning routines to determine the link between device dimensions and quantum dot yield, variability, and charge noise figures. Overall, our results demonstrate a path to monolithic integration of quantum and classical electronics at scale.

03 Jan 2025
Recent demonstrations indicate that silicon-spin QPUs will be able to shuttle physical qubits rapidly and with high fidelity - a desirable feature for maximising logical connectivity, supporting new codes, and routing around damage. However it may seem that shuttling at the logical level is unwise: static defects in the device may 'scratch' a logical qubit as it passes, causing correlated errors to which the code is highly vulnerable. Here we explore an architecture where logical qubits are 1D strings ('snakes') which can be moved freely over a planar latticework. Possible scratch events are inferred via monitor qubits and the complimentary gap; if deemed a risk, remarkably the shuttle process can be undone in a way that negates any corruption. Interaction between logical snakes is facilitated by a semi-transversal method. We obtain encouraging estimates for the tolerable levels of shuttling-related imperfections.

10 Jan 2025
 California Institute of Technology
California Institute of Technology University College London
University College London University of OxfordTechnology Innovation InstituteIBM QuantumUniversity of HelsinkiAWS Center for Quantum ComputingTrinity College DublinAlgorithmiq Ltd.Ecole Polytechnique Fédérale de LausannePhasecraft Ltd.HUN-REN Wigner Research Centre for PhysicsQuantum MotionHUN-REN Alfréd Rényi Institute of MathematicsGoogle Quantum AIUniversità di FirenzeICREA (Institucio Catalana de Recerca i Estudis Avançats)ICFO
Institut de Ciencies FotoniquesINFN
Sezione di Firenze
University of OxfordTechnology Innovation InstituteIBM QuantumUniversity of HelsinkiAWS Center for Quantum ComputingTrinity College DublinAlgorithmiq Ltd.Ecole Polytechnique Fédérale de LausannePhasecraft Ltd.HUN-REN Wigner Research Centre for PhysicsQuantum MotionHUN-REN Alfréd Rényi Institute of MathematicsGoogle Quantum AIUniversità di FirenzeICREA (Institucio Catalana de Recerca i Estudis Avançats)ICFO
Institut de Ciencies FotoniquesINFN
Sezione di FirenzeA team of 22 researchers from leading quantum computing companies and academic institutions examines six prevalent 'myths' in quantum computing discourse. The paper offers a balanced perspective on the field's progress, arguing that techniques like Quantum Error Mitigation and Variational Quantum Algorithms will continue to be important as quantum hardware evolves towards fault tolerance.
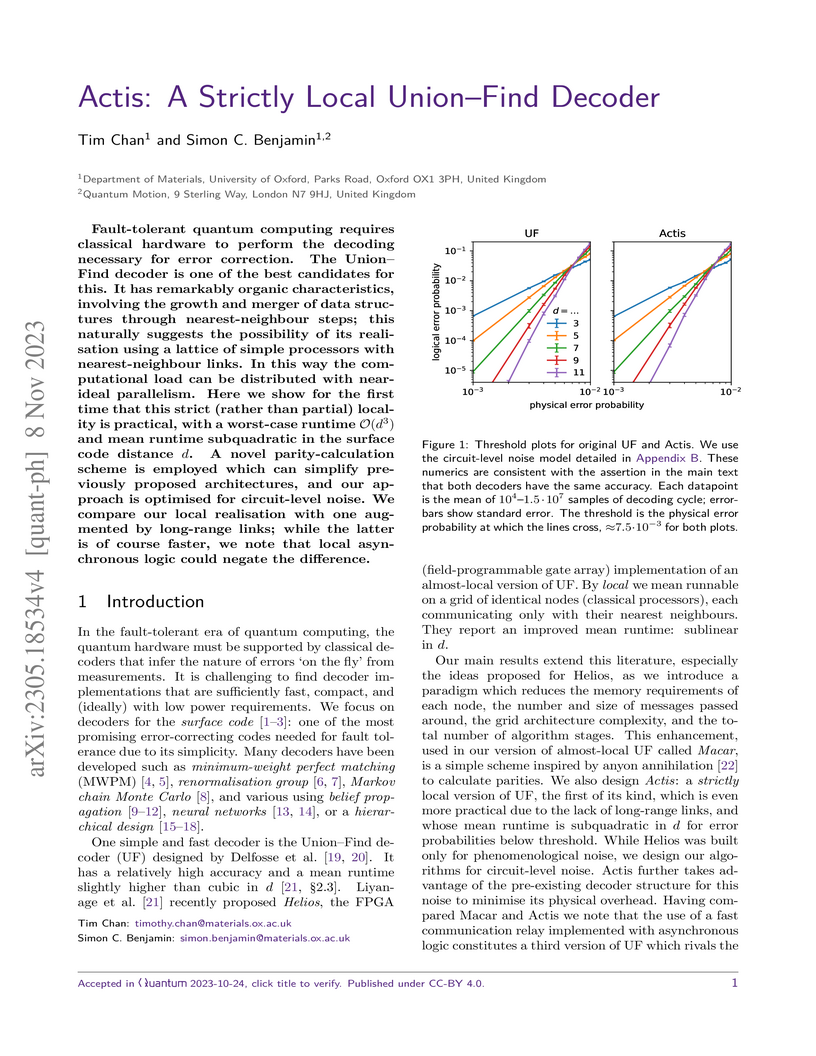
08 Nov 2023
Fault-tolerant quantum computing requires classical hardware to perform the
decoding necessary for error correction. The Union-Find decoder is one of the
best candidates for this. It has remarkably organic characteristics, involving
the growth and merger of data structures through nearest-neighbour steps; this
naturally suggests the possibility of its realisation using a lattice of simple
processors with nearest-neighbour links. In this way the computational load can
be distributed with near-ideal parallelism. Here we show for the first time
that this strict (rather than partial) locality is practical, with a worst-case
runtime and mean runtime subquadratic in the surface code
distance . A novel parity-calculation scheme is employed which can simplify
previously proposed architectures, and our approach is optimised for
circuit-level noise. We compare our local realisation with one augmented by
long-range links; while the latter is of course faster, we note that local
asynchronous logic could negate the difference.

22 Aug 2025
Researchers at Quantum Motion and Boehringer Ingelheim developed "Fullqubit Alchemist," a quantum algorithm for alchemical free energy calculations that eliminates the need for exponentially scaling entropy estimation, while also achieving super-polynomial precision speedup for quantum molecular dynamics simulations. This advancement makes the quantum computation of relative binding free energies more practical for drug discovery applications.

09 Jun 2024
We present shadow spectroscopy as a simulator-agnostic quantum algorithm for estimating energy gaps using very few circuit repetitions (shots) and no extra resources (ancilla qubits) beyond performing time evolution and measurements. The approach builds on the fundamental feature that every observable property of a quantum system must evolve according to the same harmonic components: we can reveal them by post-processing classical shadows of time-evolved quantum states to extract a large number of time-periodic signals , whose frequencies correspond to Hamiltonian energy differences with Heisenberg-limited precision. We provide strong analytical guarantees that (a) quantum resources scale as , while the classical computational complexity is linear , (b) the signal-to-noise ratio increases with the number of processed signals as , and (c) spectral peak positions are immune to reasonable levels of noise. We demonstrate our approach on model spin systems and the excited state conical intersection of molecular CH and verify that our method is indeed intuitively easy to use in practice, robust against gate noise, amiable to a new type of algorithmic-error mitigation technique, and uses orders of magnitude fewer number of shots than typical near-term quantum algorithms -- as low as 10 shots per timestep is sufficient. Finally, we measured a high-quality, experimental shadow spectrum of a spin chain on readily-available IBM quantum computers, achieving the same precision as in noise-free simulations without using any advanced error mitigation, and verified scalability in tensor-network simulations of up to 100-qubit systems.

24 Apr 2025

In quantum learning tasks, quantum memory can offer exponential reductions in statistical complexity compared to any single-copy strategies, but this typically necessitates at least doubling the system size. We show that such exponential reductions can also be achieved by having access to the purification of the target mixed state. Specifically, for a low-rank mixed state, only a constant number of ancilla qubits is needed for estimating properties related to its purity, cooled form, principal component and quantum Fisher information with constant sample complexity, which utilizes single-copy measurements on the purification. Without access to the purification, we prove that these tasks require exponentially many copies of the target mixed state for any strategies utilizing a bounded number of ancilla qubits, even with the knowledge of the target state's rank. Our findings also lead to practical applications in areas such as quantum cryptography. With further discussions about the source and extent of the advantages brought by purification, our work uncovers a new resource with significant potential for quantum learning and other applications.

28 Mar 2025


Quantum error mitigation is a key approach for extracting target state
properties on state-of-the-art noisy machines and early fault-tolerant devices.
Using the ideas from flag fault tolerance and virtual state purification, we
develop the virtual channel purification (VCP) protocol, which consumes similar
qubit and gate resources as virtual state purification but offers stronger
error suppression with increased system size and more noisy operation copies.
The application of VCP does not require specific knowledge about the target
quantum state, the target problem and the gate noise model in the target
circuit, and can still offer rigorous performance guarantees for practical
noise regimes as long as the noise is incoherent. Further connections are made
between VCP and quantum error correction to produce the virtual error
correction (VEC) protocol, one of the first protocols that combine quantum
error correction (QEC) and quantum error mitigation beyond directly applying
error mitigation protocols on top of logical qubits. Assuming perfect syndrome
extraction, VEC can virtually remove all correctable noise in the channel while
paying only the same sampling cost as low-order purification. It can achieve
QEC-level protection on an unencoded register when transmitting it through a
noisy channel, removing the associated encoding qubit overhead. Another variant
of VEC can mimic the error suppression power of the surface code by inputting
only a bit-flip and a phase-flip code. Our protocol can also be adapted to key
tasks in quantum networks like channel capacity activation and entanglement
distribution.

07 Oct 2025


In semiconductor nanostructures, spin blockade (SB) is the most scalable mechanism for electrical spin readout, requiring only two bound spins for its implementation. In conjunction with charge sensing techniques, SB has led to high-fidelity readout of spins in semiconductor-based quantum processors. However, various mechanisms may lift SB, such as strong spin-orbit coupling (SOC) or low-lying excited states, hence posing challenges to perform spin readout at scale and with high fidelity in such systems. Here, we present a method, based on the dependence of the two-spin system polarizability on energy detuning, to perform spin state readout even when SB lifting mechanisms are dominant. It leverages SB lifting as a resource to detect selectively different spin measurement outcomes. We demonstrate the method using a hybrid system formed by a quantum dot (QD) and a Boron acceptor in a silicon p-type transistor and show spin-selective readout of different spin states under SB lifting conditions due to (i) SOC and (ii) low-lying orbital states in the QD. We further use the method to determine the detuning-dependent spin relaxation time of 0.1 - 8 s. Our method should help perform projective spin measurements with high spin-to-charge conversion fidelity in systems subject to strong SOC, will facilitate state leakage detection and enable complete readout of two-spin states.

15 Sep 2025
Superinductors are circuit elements characterised by an intrinsic impedance in excess of the superconducting resistance quantum (k), with applications from metrology and sensing to quantum computing. However, they are typically obtained using exotic materials with high density inductance such as Josephson junctions, superconducting nanowires or twisted two-dimensional materials. Here, we present a superinductor realised within a silicon integrated circuit (IC), exploiting the high kinetic inductance (~nH/) of TiN thin films native to the manufacturing process (22-nm FDSOI). By interfacing the superinductor to a silicon quantum dot formed within the same IC, we demonstrate a radio-frequency single-electron transistor (rfSET), the most widely used sensor in semiconductor-based quantum computers. The integrated nature of the rfSET reduces its parasitics which, together with the high impedance, yields a sensitivity improvement of more than two orders of magnitude over the state-of-the-art, combined with a 10,000-fold area reduction. Beyond providing the basis for dense arrays of integrated and high-performance qubit sensors, the realization of high-kinetic-inductance superconducting devices integrated within modern silicon ICs opens many opportunities, including kinetic-inductance detector arrays for astronomy and the study of metamaterials and quantum simulators based on 1D and 2D resonator arrays.

14 Nov 2023
Quantum computing requires a universal set of gate operations; regarding gates as rotations, any rotation angle must be possible. However a real device may only be capable of bits of resolution, i.e. it might support only possible variants of a given physical gate. Naive discretization of an algorithm's gates to the nearest available options causes coherent errors, while decomposing an impermissible gate into several allowed operations increases circuit depth. Conversely, demanding higher can greatly complexify hardware. Here we explore an alternative: Probabilistic Angle Interpolation (PAI). This effectively implements any desired, continuously parametrised rotation by randomly choosing one of three discretised gate settings and postprocessing individual circuit outputs. The approach is particularly relevant for near-term applications where one would in any case average over many runs of circuit executions to estimate expected values. While PAI increases that sampling cost, we prove that a) the approach is optimal in the sense that PAI achieves the least possible overhead and c) the overhead is remarkably modest even with thousands of parametrised gates and only bits of resolution available. This is a profound relaxation of engineering requirements for first generation quantum computers where even bits of resolution may suffice and, as we demonstrate, the approach is many orders of magnitude more efficient than prior techniques. Moreover we conclude that, even for more mature late-NISQ hardware, no more than bits will be necessary.

03 Dec 2025
Extensive theoretical and experimental work has established high-fidelity electron shuttling in Si/SiGe systems, whereas demonstrations in Si/SiO2 (SiMOS) remain at an early stage. To help address this, we perform full 3D simulations of conveyor-belt charge shuttling in a realistic SiMOS device, building on earlier 2D modelling. We solve the Poisson and time-dependent Schrodinger equations for varying shuttling speeds and gate voltages, focusing on potential pitfalls of typical SiMOS devices such as oxide-interface roughness, gate fabrication imperfections, and charge defects along the transport path. The simulations reveal that for low clavier-gate voltages, the additional oxide screening in multi-layer gate architectures causes conveyor-belt shuttling to collapse to the bucket-brigade mode, inducing considerable orbital excitation in the process. Increasing the confinement restores conveyor-belt operation, which we find to be robust against interface roughness, gate misalignment, and charge defects buried in the oxide. However, our results indicate that defects located at the Si/SiO2-interface can induce considerable orbital excitation. For lower conveyor gate biases, positive defects in the transport channel can even capture passing electrons. Hence we identify key challenges and find operating regimes for reliable charge transport in SiMOS architectures.

22 Jan 2025
Many quantum computing platforms are based on a two-dimensional physical
layout. Here we explore a concept called looped pipelines which permits one to
obtain many of the advantages of a 3D lattice while operating a strictly 2D
device. The concept leverages qubit shuttling, a well-established feature in
platforms like semiconductor spin qubits and trapped-ion qubits. The looped
pipeline architecture has similar hardware requirements to other shuttling
approaches, but can process a stack of qubit arrays instead of just one. Even a
stack of limited height is enabling for diverse schemes ranging from NISQ-era
error mitigation through to fault-tolerant codes. For the former, protocols
involving multiple states can be implemented with a space-time resource cost
comparable to preparing one noisy copy. For the latter, one can realise a far
broader variety of code structures; as an example we consider layered 2D codes
within which transversal CNOTs are available. Under reasonable assumptions this
approach can reduce the space-time cost of magic state distillation by two
orders of magnitude. Numerical modelling using experimentally-motivated noise
models verifies that the architecture provides this benefit without significant
reduction to the code's threshold.

05 Nov 2022
Any architecture for practical quantum computing must be scalable. An
attractive approach is to create multiple cores, computing regions of fixed
size that are well-spaced but interlinked with communication channels. This
exploded architecture can relax the demands associated with a single monolithic
device: the complexity of control, cooling and power infrastructure as well as
the difficulties of cross-talk suppression and near-perfect component yield.
Here we explore interlinked multicore architectures through analytic and
numerical modelling. While elements of our analysis are relevant to diverse
platforms, our focus is on semiconductor electron spin systems in which
numerous cores may exist on a single chip. We model shuttling and
microwave-based interlinks and estimate the achievable fidelities, finding
values that are encouraging but markedly inferior to intra-core operations. We
therefore introduce optimsed entanglement purification to enable high-fidelity
communication, finding that is a very realistic goal. We then assess
the prospects for quantum advantage using such devices in the NISQ-era and
beyond: we simulate recently proposed exponentially-powerful error mitigation
schemes in the multicore environment and conclude that these techniques
impressively suppress imperfections in both the inter- and intra-core
operations.
There are no more papers matching your filters at the moment.
