
07 Dec 2025
Researchers at ShanghaiTech University and Ant Group developed FlashMHF, an efficient multi-head Feed-Forward Network (FFN) for Transformer architectures that integrates a multi-head design with an I/O-aware fused kernel. This approach consistently improves language modeling perplexity and downstream task accuracy while reducing peak memory usage by 3-5x and accelerating inference up to 1.08x compared to standard FFNs.
07 Dec 2025
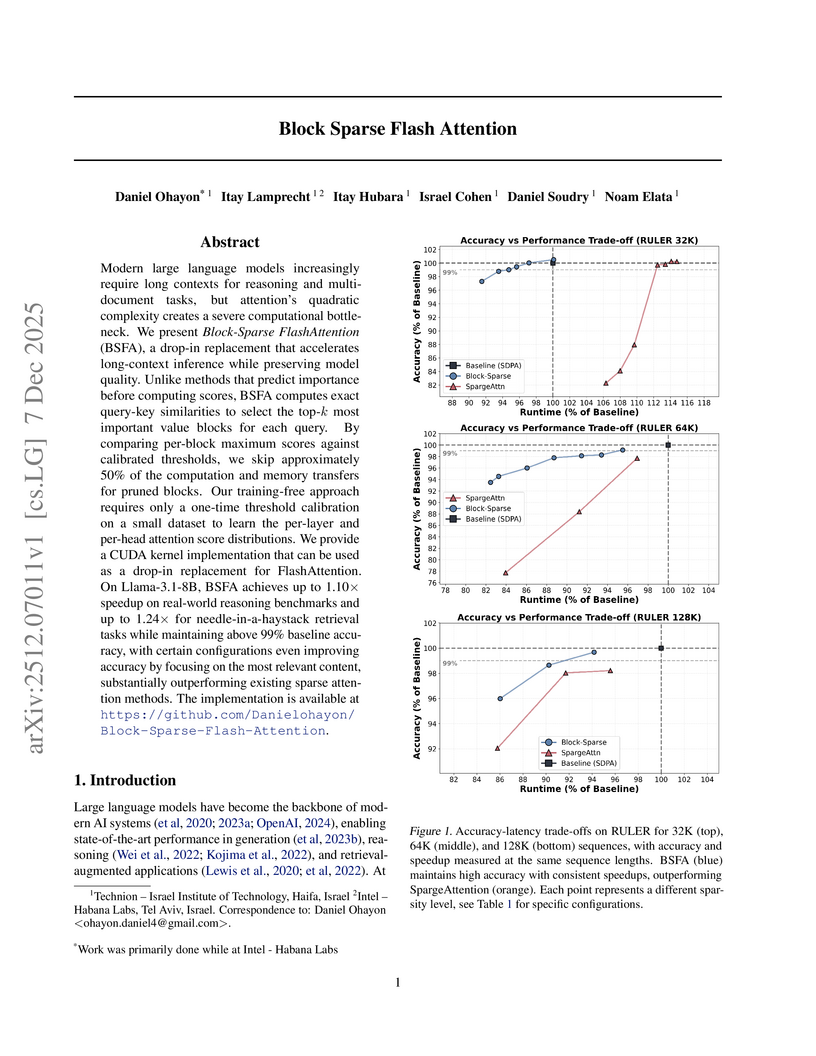
Block Sparse Flash Attention (BSFA) accelerates large language model inference for long input sequences by intelligently skipping computations for negligible value blocks based on exact attention scores. This training-free method maintains high accuracy while achieving speedups up to 1.24x on retrieval tasks and 1.10x for general reasoning.

07 Dec 2025




MeshSplatting generates connected, opaque, and colored triangle meshes from images using differentiable rendering, enabling direct integration of neurally reconstructed scenes into traditional 3D graphics pipelines. The method achieves a +0.69 dB PSNR improvement over MiLo on the Mip-NeRF360 dataset and trains 2x faster while requiring 2.5x less memory.

09 Dec 2025
OSMO is an open-source tactile glove platform designed to capture both shear and normal forces from human demonstrations, facilitating direct transfer of these skills to robots. Policies trained using OSMO achieved 71.69% success in a wiping task, outperforming vision-only baselines (55.75%) by eliminating contact-related failures.

10 Dec 2025
Always-on sensors are increasingly expected to embark a variety of tiny neural networks and to continuously perform inference on time-series of the data they sense. In order to fit lifetime and energy consumption requirements when operating on battery, such hardware uses microcontrollers (MCUs) with tiny memory budget e.g., 128kB of RAM. In this context, optimizing data flows across neural network layers becomes crucial. In this paper, we introduce TinyDéjàVu, a new framework and novel algorithms we designed to drastically reduce the RAM footprint required by inference using various tiny ML models for sensor data time-series on typical microcontroller hardware. We publish the implementation of TinyDéjàVu as open source, and we perform reproducible benchmarks on hardware. We show that TinyDéjàVu can save more than 60% of RAM usage and eliminate up to 90% of redundant compute on overlapping sliding window inputs.

09 Dec 2025
Football player tracking is challenged by frequent occlusions, similar appearances, and rapid motion in crowded scenes. This paper presents a lightweight SAM-based tracking method combining the Segment Anything Model (SAM) with CSRT trackers and jersey color-based appearance models. We propose a team-aware tracking system that uses SAM for precise initialization and HSV histogram-based re-identification to improve occlusion recovery. Our evaluation measures three dimensions: processing speed (FPS and memory), tracking accuracy (success rate and box stability), and robustness (occlusion recovery and identity consistency). Experiments on football video sequences show that the approach achieves 7.6-7.7 FPS with stable memory usage (~1880 MB), maintaining 100 percent tracking success in light occlusions and 90 percent in crowded penalty-box scenarios with 5 or more players. Appearance-based re-identification recovers 50 percent of heavy occlusions, demonstrating the value of domain-specific cues. Analysis reveals key trade-offs: the SAM + CSRT combination provides consistent performance across crowd densities but struggles with long-term occlusions where players leave the frame, achieving only 8.66 percent re-acquisition success. These results offer practical guidelines for deploying football tracking systems under resource constraints, showing that classical tracker-based methods work well with continuous visibility but require stronger re-identification mechanisms for extended absences.

09 Dec 2025
The advancement of camera-only Bird's-Eye-View(BEV) perception is currently impeded by a fundamental tension between state-of-the-art performance and on-vehicle deployment tractability. This bottleneck stems from a deep-rooted dependency on computationally prohibitive view transformations and bespoke, platform-specific kernels. This paper introduces FastBEV++, a framework engineered to reconcile this tension, demonstrating that high performance and deployment efficiency can be achieved in unison via two guiding principles: Fast by Algorithm and Deployable by Design. We realize the "Deployable by Design" principle through a novel view transformation paradigm that decomposes the monolithic projection into a standard Index-Gather-Reshape pipeline. Enabled by a deterministic pre-sorting strategy, this transformation is executed entirely with elementary, operator native primitives (e.g Gather, Matrix Multiplication), which eliminates the need for specialized CUDA kernels and ensures fully TensorRT-native portability. Concurrently, our framework is "Fast by Algorithm", leveraging this decomposed structure to seamlessly integrate an end-to-end, depth-aware fusion mechanism. This jointly learned depth modulation, further bolstered by temporal aggregation and robust data augmentation, significantly enhances the geometric fidelity of the BEV this http URL validation on the nuScenes benchmark corroborates the efficacy of our approach. FastBEV++ establishes a new state-of-the-art 0.359 NDS while maintaining exceptional real-time performance, exceeding 134 FPS on automotive-grade hardware (e.g Tesla T4). By offering a solution that is free of custom plugins yet highly accurate, FastBEV++ presents a mature and scalable design philosophy for production autonomous systems. The code is released at: this https URL

10 Dec 2025
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads.
We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8 compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5 more requests compared to the GPU-sharing system.

08 Dec 2025

Google DeepMind and Google Quantum AI introduce AlphaQubit 2 (AQ2), a neural decoder achieving near-optimal accuracy for topological quantum codes, including the surface code and the challenging color code, at large scales. Its real-time variant, AQ2-RT, processes error syndromes at sub-microsecond speeds on commercial hardware and demonstrates effectiveness on experimental data from the 105-qubit Willow chip.

08 Dec 2025
Convolutional Neural Networks (CNNs) have proven highly effective for edge and mobile vision tasks due to their computational efficiency. While many recent works seek to enhance CNNs with global contextual understanding via self-attention-based Vision Transformers, these approaches often introduce significant computational overhead. In this work, we demonstrate that it is possible to retain strong global perception without relying on computationally expensive components. We present GlimmerNet, an ultra-lightweight convolutional network built on the principle of separating receptive field diversity from feature recombination. GlimmerNet introduces Grouped Dilated Depthwise Convolutions(GDBlocks), which partition channels into groups with distinct dilation rates, enabling multi-scale feature extraction at no additional parameter cost. To fuse these features efficiently, we design a novel Aggregator module that recombines cross-group representations using grouped pointwise convolution, significantly lowering parameter overhead. With just 31K parameters and 29% fewer FLOPs than the most recent baseline, GlimmerNet achieves a new state-of-the-art weighted F1-score of 0.966 on the UAV-focused AIDERv2 dataset. These results establish a new accuracy-efficiency trade-off frontier for real-time emergency monitoring on resource-constrained UAV platforms. Our implementation is publicly available at this https URL.

10 Dec 2025
The massive scale of modern AI accelerators presents critical challenges to traditional fault assessment methodologies, which face prohibitive computational costs and provide poor coverage of critical failure modes. This paper introduces RIFT (Reinforcement Learning-guided Intelligent Fault Targeting), a scalable framework that automates the discovery of minimal, high-impact fault scenarios for efficient design-time fault assessment. RIFT transforms the complex search for worst-case faults into a sequential decision-making problem, combining hybrid sensitivity analysis for search space pruning with reinforcement learning to intelligently generate minimal, high-impact test suites. Evaluated on billion-parameter Large Language Model (LLM) workloads using NVIDIA A100 GPUs, RIFT achieves a \textbf{2.2} fault assessment speedup over evolutionary methods and reduces the required test vector volume by over \textbf{99\%} compared to random fault injection, all while achieving \textbf{superior fault coverage}. The proposed framework also provides actionable data to enable intelligent hardware protection strategies, demonstrating that RIFT-guided selective error correction code provides a \textbf{12.8} improvement in \textbf{cost-effectiveness} (coverage per unit area) compared to uniform triple modular redundancy protection. RIFT automatically generates UVM-compliant verification artifacts, ensuring its findings are directly actionable and integrable into commercial RTL verification workflows.

10 Dec 2025
We describe SynthPix, a synthetic image generator for Particle Image Velocimetry (PIV) with a focus on performance and parallelism on accelerators, implemented in JAX. SynthPix supports the same configuration parameters as existing tools but achieves a throughput several orders of magnitude higher in image-pair generation per second. SynthPix was developed to enable the training of data-hungry reinforcement learning methods for flow estimation and for reducing the iteration times during the development of fast flow estimation methods used in recent active fluids control studies with real-time PIV feedback. We believe SynthPix to be useful for the fluid dynamics community, and in this paper we describe the main ideas behind this software package.

10 Dec 2025
Low-power microcontroller (MCU) hardware is currently evolving from single-core architectures to predominantly multi-core architectures. In parallel, new embedded software building blocks are more and more written in Rust, while C/C++ dominance fades in this domain. On the other hand, small artificial neural networks (ANN) of various kinds are increasingly deployed in edge AI use cases, thus deployed and executed directly on low-power MCUs. In this context, both incremental improvements and novel innovative services will have to be continuously retrofitted using ANNs execution in software embedded on sensing/actuating systems already deployed in the field. However, there was so far no Rust embedded software platform automating parallelization for inference computation on multi-core MCUs executing arbitrary TinyML models. This paper thus fills this gap by introducing Ariel-ML, a novel toolkit we designed combining a generic TinyML pipeline and an embedded Rust software platform which can take full advantage of multi-core capabilities of various 32bit microcontroller families (Arm Cortex-M, RISC-V, ESP-32). We published the full open source code of its implementation, which we used to benchmark its capabilities using a zoo of various TinyML models. We show that Ariel-ML outperforms prior art in terms of inference latency as expected, and we show that, compared to pre-existing toolkits using embedded C/C++, Ariel-ML achieves comparable memory footprints. Ariel-ML thus provides a useful basis for TinyML practitioners and resource-constrained embedded Rust developers.

06 Dec 2025
Reinforcement learning (RL) has emerged as the de-facto paradigm for improving the reasoning capabilities of large language models (LLMs). We have developed RLAX, a scalable RL framework on TPUs. RLAX employs a parameter-server architecture. A master trainer periodically pushes updated model weights to the parameter server while a fleet of inference workers pull the latest weights and generates new rollouts. We introduce a suite of system techniques to enable scalable and preemptible RL for a diverse set of state-of-art RL algorithms. To accelerate convergence and improve model quality, we have devised new dataset curation and alignment techniques. Large-scale evaluations show that RLAX improves QwQ-32B's pass@8 accuracy by 12.8% in just 12 hours 48 minutes on 1024 v5p TPUs, while remaining robust to preemptions during training.

08 Dec 2025
The rapid adoption of large language models (LLMs) is pushing AI accelerators toward increasingly powerful and specialized designs. Instead of further complicating software development with deeply hierarchical scratchpad memories (SPMs) and their asynchronous management, we investigate the opposite point of the design spectrum: a multi-core AI accelerator equipped with a shared system-level cache and application-aware management policies, which keeps the programming effort modest. Our approach exploits dataflow information available in the software stack to guide cache replacement (including dead-block prediction), in concert with bypass decisions and mechanisms that alleviate cache thrashing.
We assess the proposal using a cycle-accurate simulator and observe substantial performance gains (up to 1.80x speedup) compared with conventional cache architectures. In addition, we build and validate an analytical model that takes into account the actual overlapping behaviors to extend the measurement results of our policies to real-world larger-scale workloads. Experiment results show that when functioning together, our bypassing and thrashing mitigation strategies can handle scenarios both with and without inter-core data sharing and achieve remarkable speedups.
Finally, we implement the design in RTL and the area of our design is with 15nm process, which can run at 2 GHz clock frequency. Our findings explore the potential of the shared cache design to assist the development of future AI accelerator systems.

08 Dec 2025
3D Gaussian Splatting (3DGS) has emerged as a powerful explicit representation enabling real-time, high-fidelity 3D reconstruction and novel view synthesis. However, its practical use is hindered by the massive memory and computational demands required to store and render millions of Gaussians. These challenges become even more severe in 4D dynamic scenes. To address these issues, the field of Efficient Gaussian Splatting has rapidly evolved, proposing methods that reduce redundancy while preserving reconstruction quality. This survey provides the first unified overview of efficient 3D and 4D Gaussian Splatting techniques. For both 3D and 4D settings, we systematically categorize existing methods into two major directions, Parameter Compression and Restructuring Compression, and comprehensively summarize the core ideas and methodological trends within each category. We further cover widely used datasets, evaluation metrics, and representative benchmark comparisons. Finally, we discuss current limitations and outline promising research directions toward scalable, compact, and real-time Gaussian Splatting for both static and dynamic 3D scene representation.

10 Dec 2025
Physics-Informed Neural Networks (PINNs) have emerged as a promising paradigm for solving partial differential equations (PDEs) by embedding physical laws into neural network training objectives. However, their deployment on resource-constrained platforms is hindered by substantial computational and memory overhead, primarily stemming from higher-order automatic differentiation, intensive tensor operations, and reliance on full-precision arithmetic. To address these challenges, we present a framework that enables scalable and energy-efficient PINN training on edge devices. This framework integrates fully quantized training, Stein's estimator (SE)-based residual loss computation, and tensor-train (TT) decomposition for weight compression. It contributes three key innovations: (1) a mixed-precision training method that use a square-block MX (SMX) format to eliminate data duplication during backpropagation; (2) a difference-based quantization scheme for the Stein's estimator that mitigates underflow; and (3) a partial-reconstruction scheme (PRS) for TT-Layers that reduces quantization-error accumulation. We further design PINTA, a precision-scalable hardware accelerator, to fully exploit the performance of the framework. Experiments on the 2-D Poisson, 20-D Hamilton-Jacobi-Bellman (HJB), and 100-D Heat equations demonstrate that the proposed framework achieves accuracy comparable to or better than full-precision, uncompressed baselines while delivering 5.5x to 83.5x speedups and 159.6x to 2324.1x energy savings. This work enables real-time PDE solving on edge devices and paves the way for energy-efficient scientific computing at scale.

10 Dec 2025
Quantum neural networks (QNNs) and parameterized quantum circuits (PQCs) are key building blocks for near-term quantum machine learning. However, their scalability is constrained by excessive parameters, barren plateaus, and hardware limitations. We propose LiePrune, the first mathematically grounded one-shot structured pruning framework for QNNs that leverages Lie group structure and quantum geometric information. Each gate is jointly represented in a Lie group--Lie algebra dual space and a quantum geometric feature space, enabling principled redundancy detection and aggressive compression. Experiments on quantum classification (MNIST, FashionMNIST), quantum generative modeling (Bars-and-Stripes), and quantum chemistry (LiH VQE) show that LiePrune achieves over compression with negligible or even improved task performance, while providing provable guarantees on redundancy detection, functional approximation, and computational complexity.

07 Dec 2025
As Large Language Models (LLMs) scale in size and context length, the memory requirements of the key value (KV) cache have emerged as a major bottleneck during autoregressive decoding. The KV cache grows with sequence length and embedding dimension, often exceeding the memory footprint of the model itself and limiting achievable batch sizes and context windows. To address this challenge, we present KV CAR, a unified and architecture agnostic framework that significantly reduces KV cache storage while maintaining model fidelity. KV CAR combines two complementary techniques. First, a lightweight autoencoder learns compact representations of key and value tensors along the embedding dimension, compressing them before they are stored in the KV cache and restoring them upon retrieval. Second, a similarity driven reuse mechanism identifies opportunities to reuse KV tensors of specific attention heads across adjacent layers. Together, these methods reduce the dimensional and structural redundancy in KV tensors without requiring changes to the transformer architecture. Evaluations on GPT 2 and TinyLLaMA models across Wikitext, C4, PIQA, and Winogrande datasets demonstrate that KV CAR achieves up to 47.85 percent KV cache memory reduction with minimal impact on perplexity and zero shot accuracy. System level measurements on an NVIDIA A40 GPU show that the reduced KV footprint directly translates into longer sequence lengths and larger batch sizes during inference. These results highlight the effectiveness of KV CAR in enabling memory efficient LLM inference.

05 Dec 2025


Researchers from HKUST, Moffett AI, and ByteDance Seed developed SQ-format, a unified sparse-quantized hardware-friendly data format for Large Language Models (LLMs). This format enables a 1.71x inference speedup for Llama-3-70B while maintaining accuracy and reduces the total silicon area for dedicated hardware units by 35.8%.
There are no more papers matching your filters at the moment.
