
09 Dec 2025
Training large language models (LLMs) efficiently requires a deep understanding of how modern GPU systems behave under real-world distributed training workloads. While prior work has focused primarily on kernel-level performance or single-GPU microbenchmarks, the complex interaction between communication, computation, memory behavior, and power management in multi-GPU LLM training remains poorly characterized. In this work, we introduce Chopper, a profiling and analysis framework that collects, aligns, and visualizes GPU kernel traces and hardware performance counters across multiple granularities (i.e., from individual kernels to operations, layers, phases, iterations, and GPUs). Using Chopper, we perform a comprehensive end-to-end characterization of Llama 3 8B training under fully sharded data parallelism (FSDP) on an eight-GPU AMD InstinctTM MI300X node. Our analysis reveals several previously underexplored bottlenecks and behaviors, such as memory determinism enabling higher, more stable GPU and memory frequencies. We identify several sources of inefficiencies, with frequency overhead (DVFS effects) being the single largest contributor to the gap between theoretical and observed performance, exceeding the impact of MFMA utilization loss, communication/computation overlap, and kernel launch overheads. Overall, Chopper provides the first holistic, multi-granularity characterization of LLM training on AMD InstinctTM MI300X GPUs, yielding actionable insights for optimizing training frameworks, improving power-management strategies, and guiding future GPU architecture and system design.

08 Dec 2025
The rapid adoption of large language models (LLMs) is pushing AI accelerators toward increasingly powerful and specialized designs. Instead of further complicating software development with deeply hierarchical scratchpad memories (SPMs) and their asynchronous management, we investigate the opposite point of the design spectrum: a multi-core AI accelerator equipped with a shared system-level cache and application-aware management policies, which keeps the programming effort modest. Our approach exploits dataflow information available in the software stack to guide cache replacement (including dead-block prediction), in concert with bypass decisions and mechanisms that alleviate cache thrashing.
We assess the proposal using a cycle-accurate simulator and observe substantial performance gains (up to 1.80x speedup) compared with conventional cache architectures. In addition, we build and validate an analytical model that takes into account the actual overlapping behaviors to extend the measurement results of our policies to real-world larger-scale workloads. Experiment results show that when functioning together, our bypassing and thrashing mitigation strategies can handle scenarios both with and without inter-core data sharing and achieve remarkable speedups.
Finally, we implement the design in RTL and the area of our design is with 15nm process, which can run at 2 GHz clock frequency. Our findings explore the potential of the shared cache design to assist the development of future AI accelerator systems.

10 Dec 2025
Physics-Informed Neural Networks (PINNs) have emerged as a promising paradigm for solving partial differential equations (PDEs) by embedding physical laws into neural network training objectives. However, their deployment on resource-constrained platforms is hindered by substantial computational and memory overhead, primarily stemming from higher-order automatic differentiation, intensive tensor operations, and reliance on full-precision arithmetic. To address these challenges, we present a framework that enables scalable and energy-efficient PINN training on edge devices. This framework integrates fully quantized training, Stein's estimator (SE)-based residual loss computation, and tensor-train (TT) decomposition for weight compression. It contributes three key innovations: (1) a mixed-precision training method that use a square-block MX (SMX) format to eliminate data duplication during backpropagation; (2) a difference-based quantization scheme for the Stein's estimator that mitigates underflow; and (3) a partial-reconstruction scheme (PRS) for TT-Layers that reduces quantization-error accumulation. We further design PINTA, a precision-scalable hardware accelerator, to fully exploit the performance of the framework. Experiments on the 2-D Poisson, 20-D Hamilton-Jacobi-Bellman (HJB), and 100-D Heat equations demonstrate that the proposed framework achieves accuracy comparable to or better than full-precision, uncompressed baselines while delivering 5.5x to 83.5x speedups and 159.6x to 2324.1x energy savings. This work enables real-time PDE solving on edge devices and paves the way for energy-efficient scientific computing at scale.

04 Dec 2025
Researchers from Rensselaer Polytechnic Institute and IBM Research propose a context-aware system for Mixture-of-Experts (MoE) Large Language Model inference on CXL-enabled GPU-NDP systems. This approach achieves up to 11.2x speedup over previous GPU-NDP methods and up to 19x over GPU-only baselines, while maintaining accuracy with an average 0.13% drop for 3-bit quantization.

05 Dec 2025
We present an end-to-end open-source compiler toolchain that targets synthesizable SystemVerilog from ML models written in PyTorch. Our toolchain leverages the accelerator design language Allo, the hardware intermediate representation (IR) Calyx, and the CIRCT project under LLVM. We also implement a set of compiler passes for memory partitioning, enabling effective parallelism in memory-intensive ML workloads. Experimental results demonstrate that our compiler can effectively generate optimized FPGA-implementable hardware designs that perform reasonably well against closed-source industry-grade tools such as Vitis HLS.

10 Dec 2025
Serving large language models (LLMs) on accelerators with poor random-access bandwidth (e.g., LPDDR5-based) is limited by current memory managers. Static pre-allocation wastes memory, while fine-grained paging (e.g., PagedAttention) is ill-suited due to high random-access costs. Existing HBM-centric solutions do not exploit the characteristics of random-access-constrained memory (RACM) accelerators like Cambricon MLU370. We present ODMA, an on-demand memory allocation framework for RACM. ODMA addresses distribution drift and heavy-tailed requests by coupling a lightweight length predictor with dynamic bucket partitioning and a large-bucket safeguard. Boundaries are periodically updated from live traces to maximize utilization. On Alpaca and Google-NQ, ODMA improves prediction accuracy of prior work significantly (e.g., from 82.68% to 93.36%). Serving DeepSeek-R1-Distill-Qwen-7B on Cambricon MLU370-X4, ODMA raises memory utilization from 55.05% to 72.45% and improves RPS and TPS by 29% and 27% over static baselines. This demonstrates that hardware-aware allocation unlocks efficient LLM serving on RACM platforms.
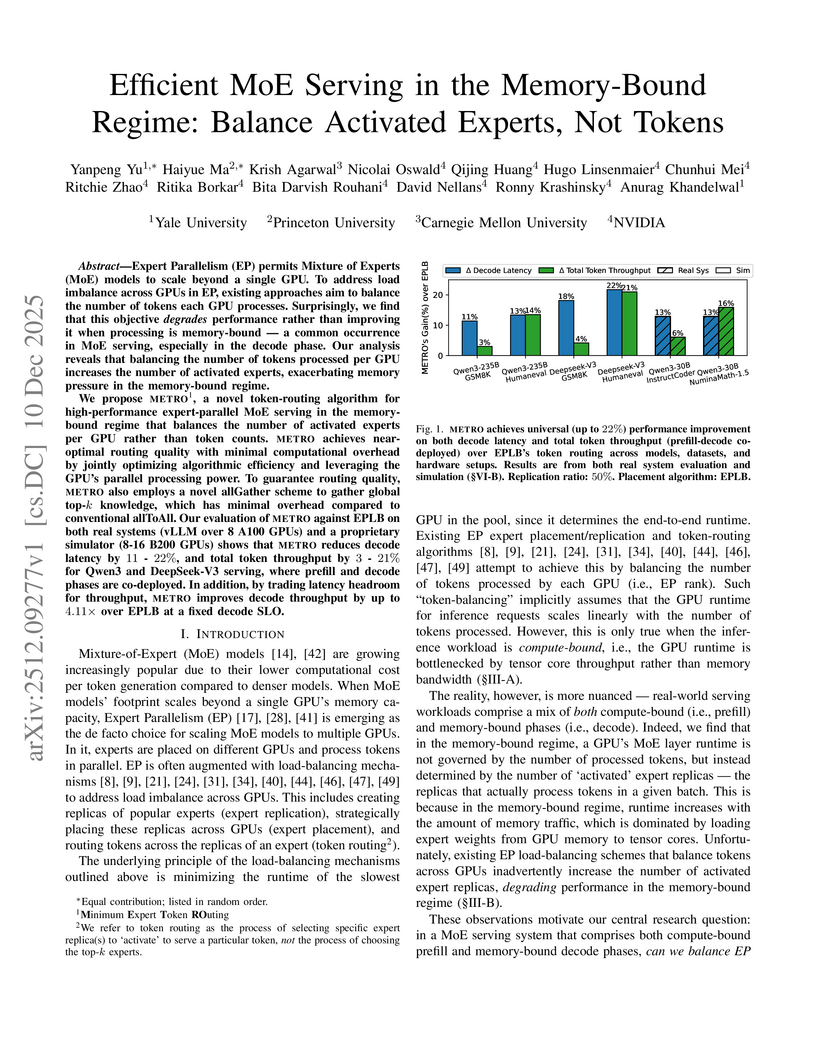
10 Dec 2025
Expert Parallelism (EP) permits Mixture of Experts (MoE) models to scale beyond a single GPU. To address load imbalance across GPUs in EP, existing approaches aim to balance the number of tokens each GPU processes. Surprisingly, we find that this objective degrades performance rather than improving it when processing is memory-bound - a common occurrence in MoE serving, especially in the decode phase. Our analysis reveals that balancing the number of tokens processed per GPU increases the number of activated experts, exacerbating memory pressure in the memory-bound regime.
We propose Minimum Expert Token ROuting, a novel token-routing algorithm for high-performance expert-parallel MoE serving in the memory-bound regime that balances the number of activated experts per GPU rather than token counts. METRO achieves near-optimal routing quality with minimal computational overhead by jointly optimizing algorithmic efficiency and leveraging the GPU's parallel processing power. To guarantee routing quality, METRO also employs a novel allGather scheme to gather global top-k knowledge, which has minimal overhead compared to conventional allToAll. Our evaluation of METRO against EPLB on both real systems (vLLM over 8 A100 GPUs) and a proprietary simulator (8-16 B200 GPUs) shows that METRO reduces decode latency by 11 - 22%, and total token throughput by 3 - 21% for Qwen3 and DeepSeek-V3 serving, where prefill and decode phases are co-deployed. In addition, by trading latency headroom for throughput, METRO improves decode throughput by up to 4.11x over EPLB at a fixed decode SLO.

05 Dec 2025


Inference of standard CNNs on FPGAs often incurs high latency and a long initiation interval due to the deep nested loops required to densely convolve every input pixel regardless of its feature value, especially when the image size is large. However, in some image data, input features can be spatially sparse, and semantic information may occupy only a small fraction of the input pixels. In this case most computation would be wasted on empty regions. In this work, we introduce SparsePixels, a framework for efficient convolution for spatially sparse image data on FPGAs, targeting fast inference applications in constrained environments with latency requirements of microseconds or below. Our approach implements a special class of CNNs that selectively retain and compute on a small subset of pixels that are active while ignoring the rest. We show that, for example, in a neutrino physics dataset for identifying neutrino interactions in LArTPC images that have around 4k input pixels but are naturally very sparse, a standard CNN with a compact size of 4k parameters incurs an inference latency of 48.665 s on an FPGA, whereas a sparse CNN of the same base architecture computing on less than 1% of the input pixels results in a inference speedup to 0.665 s, with resource utilization well within on-chip budgets, trading only a small percent-level performance loss. At least one-order-of magnitude speedups with comparable performance are also demonstrated in similar datasets with sparse image patterns. This work aims to benefit future algorithm developments for fast and efficient data readout in modern experiments such as the trigger and data acquisition systems at the CERN Large Hadron Collider. For easy adoption, we have developed a library to support building sparse CNNs with quantization-aware training, as well as an HLS implementation for FPGA deployment.

04 Dec 2025
Researchers from IIT Guwahati and NXP USA, Inc. developed an agentic AI framework that enables small language models (SLMs) to achieve performance comparable to or exceeding large language models (LLMs) in hardware design tasks. This framework improved SLM pass@1 scores by 30-140% in code generation and allowed SLMs to outperform LLMs in specific code improvement and comprehension scenarios, significantly reducing computational cost and energy.

03 Dec 2025
KVNAND is the first architecture to enable entirely DRAM-free, on-device Large Language Model (LLM) inference by integrating both model weights and the dynamic Key-Value (KV) cache within compute-enabled 3D NAND flash. This approach resolves out-of-memory issues for long contexts up to 100K tokens, achieving geomean speedups up to 2.05x and reducing memory costs by 69% compared to DRAM-based solutions.

04 Dec 2025
Resistive random-access memory (RRAM) provides an excellent platform for analog matrix computing (AMC), enabling both matrix-vector multiplication (MVM) and the solution of matrix equations through open-loop and closed-loop circuit architectures. While RRAM-based AMC has been widely explored for accelerating neural networks, its application to signal processing in massive multiple-input multiple-output (MIMO) wireless communication is rapidly emerging as a promising direction. In this Review, we summarize recent advances in applying AMC to massive MIMO, including DFT/IDFT computation for OFDM modulation and demodulation using MVM circuits; MIMO detection and precoding using MVM-based iterative algorithms; and rapid one-step solutions enabled by matrix inversion (INV) and generalized inverse (GINV) circuits. We also highlight additional opportunities, such as AMC-based compressed-sensing recovery for channel estimation and eigenvalue circuits for leakage-based precoding. Finally, we outline key challenges, including RRAM device reliability, analog circuit precision, array scalability, and data conversion bottlenecks, and discuss the opportunities for overcoming these barriers. With continued progress in device-circuit-algorithm co-design, RRAM-based AMC holds strong promise for delivering high-efficiency, high-reliability solutions to (ultra)massive MIMO signal processing in the 6G era.

01 Dec 2025
This work presents the first detailed microbenchmark characterization of NVIDIA's Blackwell B200 GPU, quantifying performance gains from its new Tensor Memory, hardware Decompression Engine, and 5th-generation Tensor Cores. It reveals up to 2.5x throughput improvement for LLM inference with FP4 precision and a 42% increase in energy efficiency for GPT training.

26 Nov 2025

Large Language Models (LLMs) have achieved unprecedented success across various applications, but their substantial memory requirements pose significant challenges to current memory system designs, especially during inference. Our work targets last-level cache (LLC) based architectures, including GPUs (e.g., NVIDIA GPUs) and AI accelerators. We introduce LLaMCAT, a novel approach to optimize the LLC for LLM inference. LLaMCAT combines Miss Status Holding Register (MSHR)- and load balance-aware cache arbitration with thread throttling to address stringent bandwidth demands and minimize cache stalls in KV Cache access. We also propose a hybrid simulation framework integrating analytical models with cycle-level simulators via memory traces, balancing architecture detail and efficiency.
Experiments demonstrate that LLaMCAT achieves an average speedup of 1.26x when the system is mainly bottlenecked by miss handling throughput, while baselines mostly show negative improvements since they are not optimized for this scenario. When the cache size is also limited, our policy achieves a speedup of 1.58x over the unoptimized version, and a 1.26x improvement over the best baseline (dyncta). Overall, LLaMCAT is the first to target LLM decoding-specific MSHR contention, a gap in previous work. It presents a practical solution for accelerating LLM inference on future hardware platforms.

20 Nov 2025
This research introduces Asymmetric Tile Buffering (ATB) to optimize General Matrix Multiplication (GEMM) on AI accelerators. The technique, which decouples input and output tile dimensions, significantly boosts arithmetic intensity and achieves record-breaking performance, demonstrating up to a 4.54x speedup on the AMD XDNA2
™ AI Engine for mixed-precision BFP16 operations.
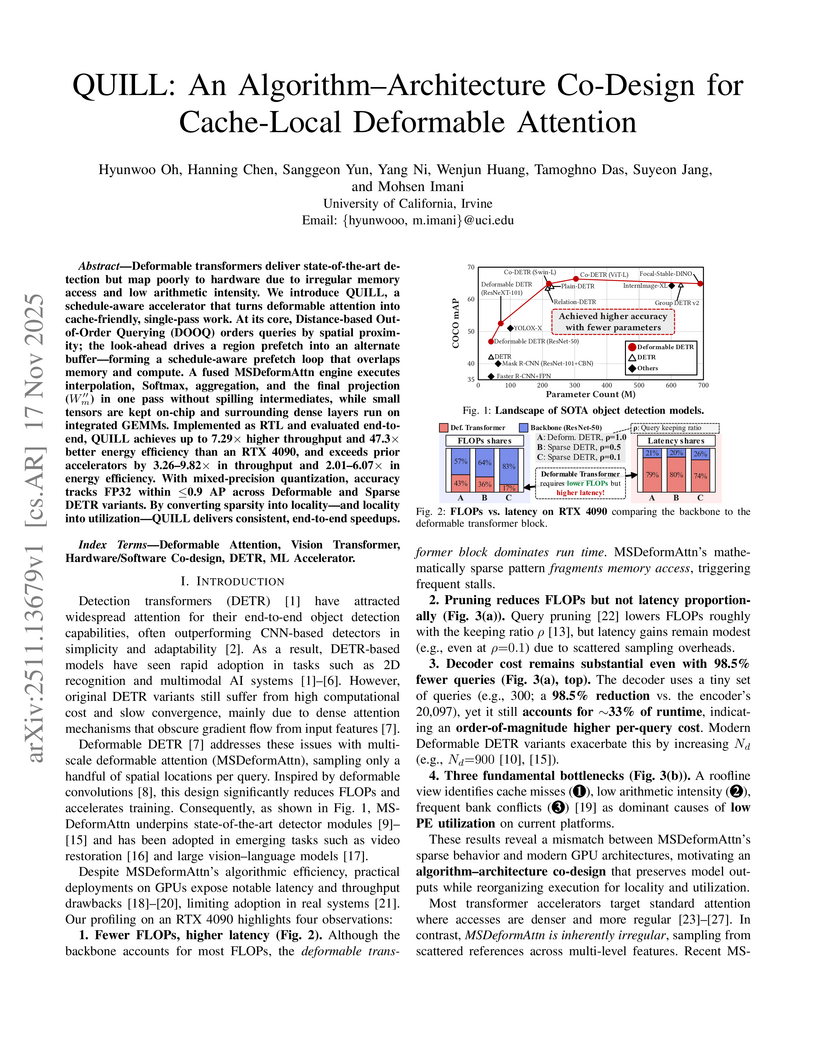
17 Nov 2025
Deformable transformers deliver state-of-the-art detection but map poorly to hardware due to irregular memory access and low arithmetic intensity. We introduce QUILL, a schedule-aware accelerator that turns deformable attention into cache-friendly, single-pass work. At its core, Distance-based Out-of-Order Querying (DOOQ) orders queries by spatial proximity; the look-ahead drives a region prefetch into an alternate buffer--forming a schedule-aware prefetch loop that overlaps memory and compute. A fused MSDeformAttn engine executes interpolation, Softmax, aggregation, and the final projection (W''m) in one pass without spilling intermediates, while small tensors are kept on-chip and surrounding dense layers run on integrated GEMMs. Implemented as RTL and evaluated end-to-end, QUILL achieves up to 7.29x higher throughput and 47.3x better energy efficiency than an RTX 4090, and exceeds prior accelerators by 3.26-9.82x in throughput and 2.01-6.07x in energy efficiency. With mixed-precision quantization, accuracy tracks FP32 within <=0.9 AP across Deformable and Sparse DETR variants. By converting sparsity into locality--and locality into utilization--QUILL delivers consistent, end-to-end speedups.

24 Nov 2025

Modern AI workloads, especially Mixture-of-Experts (MoE) architectures, increasingly demand low-latency, fine-grained GPU-to-GPU communication with device-side control. Traditional GPU communication follows a host-initiated model, where the CPU orchestrates all communication operations - a characteristic of the CUDA runtime. Although robust for collective operations, applications requiring tight integration of computation and communication can benefit from device-initiated communication that eliminates CPU coordination overhead.
NCCL 2.28 introduces the Device API with three operation modes: Load/Store Accessible (LSA) for NVLink/PCIe, Multimem for NVLink SHARP, and GPU-Initiated Networking (GIN) for network RDMA. This paper presents the GIN architecture, design, semantics, and highlights its impact on MoE communication. GIN builds on a three-layer architecture: i) NCCL Core host-side APIs for device communicator setup and collective memory window registration; ii) Device-side APIs for remote memory operations callable from CUDA kernels; and iii) A network plugin architecture with dual semantics (GPUDirect Async Kernel-Initiated and Proxy) for broad hardware support. The GPUDirect Async Kernel-Initiated backend leverages DOCA GPUNetIO for direct GPU-to-NIC communication, while the Proxy backend provides equivalent functionality via lock-free GPU-to-CPU queues over standard RDMA networks. We demonstrate GIN's practicality through integration with DeepEP, an MoE communication library. Comprehensive benchmarking shows that GIN provides device-initiated communication within NCCL's unified runtime, combining low-latency operations with NCCL's collective algorithms and production infrastructure.

16 Nov 2025
The growing demand for low-power and area-efficient TinyML inference on AIoT devices necessitates memory architectures that minimise data movement while sustaining high computational efficiency. This paper presents FERMI-ML, a Flexible and Resource-Efficient Memory-In-Situ (MIS) SRAM macro designed for TinyML acceleration. The proposed 9T XNOR-based RX9T bit-cell integrates a 5T storage cell with a 4T XNOR compute unit, enabling variable-precision MAC and CAM operations within the same array. A 22-transistor (C22T) compressor-tree-based accumulator facilitates logarithmic 1-64-bit MAC computation with reduced delay and power compared to conventional adder trees. The 4 KB macro achieves dual functionality for in-situ computation and CAM-based lookup operations, supporting Posit-4 or FP-4 precision. Post-layout results at 65 nm show operation at 350 MHz with 0.9 V, delivering a throughput of 1.93 TOPS and an energy efficiency of 364 TOPS/W, while maintaining a Quality-of-Result (QoR) above 97.5% with InceptionV4 and ResNet-18. FERMI-ML thus demonstrates a compact, reconfigurable, and energy-aware digital Memory-In-Situ macro capable of supporting mixed-precision TinyML workloads.

14 Nov 2025
The rapidly growing computation demands of deep neural networks (DNNs) have driven hardware vendors to integrate matrix multiplication accelerators (MMAs), such as NVIDIA Tensor Cores and AMD Matrix Cores, into modern GPUs. However, due to distinct and undocumented arithmetic specifications for floating-point matrix multiplication, some MMAs can lead to numerical imprecision and inconsistency that can compromise the stability and reproducibility of DNN training and inference.
This paper presents MMA-Sim, the first bit-accurate reference model that reveals the detailed arithmetic behaviors of the MMAs from ten GPU architectures (eight from NVIDIA and two from AMD). By dissecting the MMAs using a combination of targeted and randomized tests, our methodology derives nine arithmetic algorithms to simulate the floating-point matrix multiplication of the MMAs. Large-scale validation confirms bitwise equivalence between MMA-Sim and the real hardware. Using MMA-Sim, we investigate arithmetic behaviors that affect DNN training stability, and identify undocumented behaviors that could lead to significant errors.

29 Oct 2025
The continuous miniaturisation of metal-oxide-semiconductor field-effect transistors (MOSFETs) from long- to short-channel architectures has advanced beyond the predictions of Moore's Law. Continued advances in semiconductor electronics, even near current scaling and performance boundaries under cryogenic conditions, are driving the development of innovative device paradigms that enable ultra-low-power and high-speed functionality. Among emerging candidates, the Josephson Junction Field-Effect Transistor (JJFET or JoFET) provides an alternative by integrating superconducting source and drain electrodes for efficient, phase-coherent operation at ultra-low temperatures. These hybrid devices have the potential to bridge conventional semiconductor electronics with cryogenic logic and quantum circuits, enabling energy-efficient and high-coherence signal processing across temperature domains. This review traces the evolution from Josephson junctions to field-effect transistors, emphasising the structural and functional innovations that underpin modern device scalability. The performance and material compatibility of JJFETs fabricated on Si, GaAs, and InGaAs substrates are analysed, alongside an assessment of their switching dynamics and material compatibility. Particular attention is given to superconductor-silicon-superconductor Josephson junctions as the active core of JJFET architectures. By unfolding more than four decades of experimental progress, this work highlights the promise of JJFETs as foundational building blocks for next-generation cryogenic logic and quantum electronic systems.
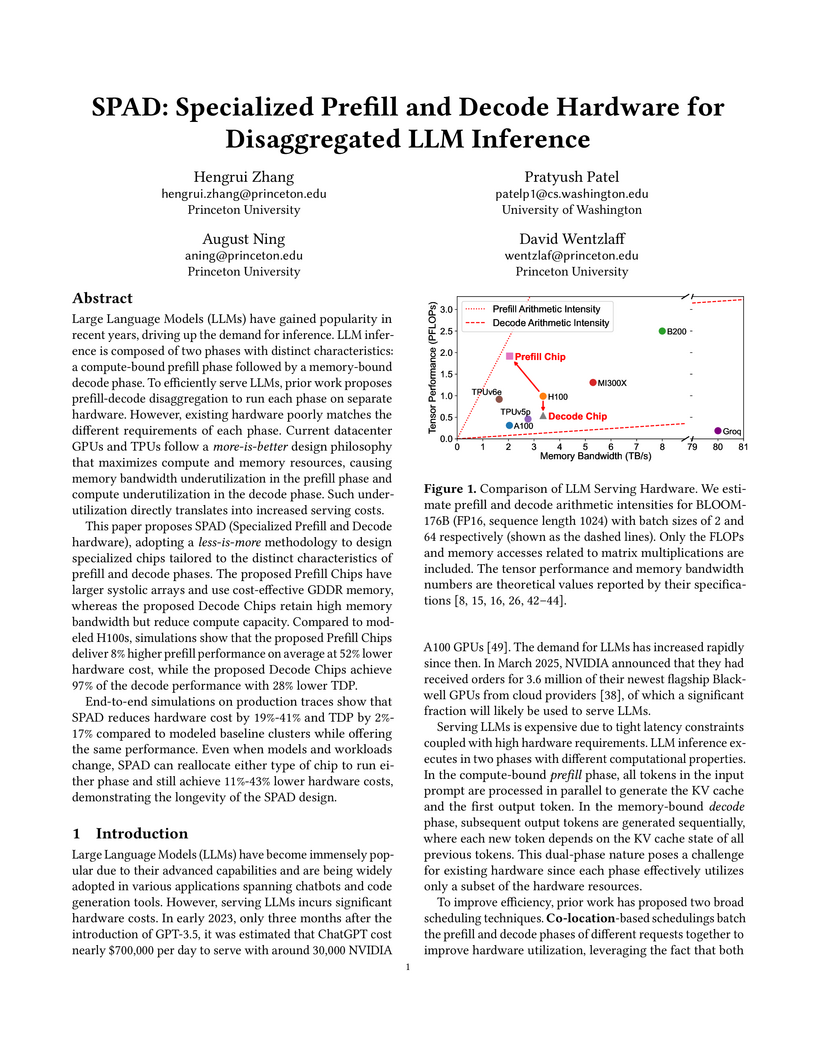
09 Oct 2025


Researchers from Princeton University and the University of Washington introduce SPAD, a specialized hardware framework for disaggregated Large Language Model inference, comprising distinct Prefill and Decode chips. This "less-is-more" design approach, which right-sizes hardware resources for each inference phase, achieves 19-41% lower hardware costs and 2-17% lower Total Design Power (TDP) for LLM serving clusters compared to current GPU baselines.
There are no more papers matching your filters at the moment.
