
09 Dec 2025




Wan-Move presents a framework for motion-controllable video generation that utilizes latent trajectory guidance to directly edit image condition features within a pre-trained image-to-video model. This method yields superior visual quality and precise motion adherence compared to state-of-the-art academic approaches and rivals commercial solutions, while also establishing MoveBench, a new comprehensive evaluation benchmark.

09 Dec 2025



Researchers from Google DeepMind, University College London, and the University of Oxford developed D4RT, a unified feedforward model for reconstructing dynamic 4D scenes, encompassing depth, spatio-temporal correspondence, and camera parameters, from video using a single, flexible querying interface. The model achieved state-of-the-art accuracy across various 4D reconstruction and tracking benchmarks, with 3D tracking throughput 18-300 times faster and pose estimation over 100 times faster than prior methods.

10 Dec 2025


The growing adoption of XR devices has fueled strong demand for high-quality stereo video, yet its production remains costly and artifact-prone. To address this challenge, we present StereoWorld, an end-to-end framework that repurposes a pretrained video generator for high-fidelity monocular-to-stereo video generation. Our framework jointly conditions the model on the monocular video input while explicitly supervising the generation with a geometry-aware regularization to ensure 3D structural fidelity. A spatio-temporal tiling scheme is further integrated to enable efficient, high-resolution synthesis. To enable large-scale training and evaluation, we curate a high-definition stereo video dataset containing over 11M frames aligned to natural human interpupillary distance (IPD). Extensive experiments demonstrate that StereoWorld substantially outperforms prior methods, generating stereo videos with superior visual fidelity and geometric consistency. The project webpage is available at this https URL.

07 Dec 2025



MeshSplatting generates connected, opaque, and colored triangle meshes from images using differentiable rendering, enabling direct integration of neurally reconstructed scenes into traditional 3D graphics pipelines. The method achieves a +0.69 dB PSNR improvement over MiLo on the Mip-NeRF360 dataset and trains 2x faster while requiring 2.5x less memory.

09 Dec 2025
Visionary introduces a WebGPU-powered platform for 3D Gaussian Splatting (3DGS) that enables real-time, client-side rendering and inference for dynamic and generative 3DGS models. The platform demonstrates up to 135x speedup compared to WebGL-based viewers, while maintaining or improving visual quality and ensuring robust depth-aware composition.

08 Dec 2025

WorldReel develops a unified, feed-forward 4D generator that integrates geometry, motion, and appearance directly into a latent diffusion model, yielding videos with explicit 4D scene representations. The model achieves state-of-the-art photorealism and significantly improves geometric consistency and dynamic range, particularly for complex scenes with moving cameras.

09 Dec 2025

Researchers from Peking University, Nanchang University, and Tsinghua University developed the first on-the-fly 3D reconstruction framework for multi-camera rigs, enabling calibration-free, large-scale, and high-fidelity scene reconstruction. The system generates drift-free trajectories and photorealistic novel views, reconstructing 100 meters of road or 100,000 m² of aerial scenes in two minutes.

09 Dec 2025

We present WonderZoom, a novel approach to generating 3D scenes with contents across multiple spatial scales from a single image. Existing 3D world generation models remain limited to single-scale synthesis and cannot produce coherent scene contents at varying granularities. The fundamental challenge is the lack of a scale-aware 3D representation capable of generating and rendering content with largely different spatial sizes. WonderZoom addresses this through two key innovations: (1) scale-adaptive Gaussian surfels for generating and real-time rendering of multi-scale 3D scenes, and (2) a progressive detail synthesizer that iteratively generates finer-scale 3D contents. Our approach enables users to "zoom into" a 3D region and auto-regressively synthesize previously non-existent fine details from landscapes to microscopic features. Experiments demonstrate that WonderZoom significantly outperforms state-of-the-art video and 3D models in both quality and alignment, enabling multi-scale 3D world creation from a single image. We show video results and an interactive viewer of generated multi-scale 3D worlds in this https URL

08 Dec 2025

Researchers at Zhejiang University developed LIVINGSWAP, a high-fidelity video face swapping framework designed for cinematic quality by directly leveraging complete source video attributes and employing keyframe conditioning. The system outperforms existing methods on new cinematic benchmarks and reduces manual editing effort by approximately 40 times.

09 Dec 2025



Researchers from Cornell University, Google, and UC Berkeley developed Selfi, a framework that refines pre-trained 3D Vision Foundation Model features through self-supervised geometric alignment. It achieves state-of-the-art pose-free novel view synthesis quality and robust camera pose estimation, often rivaling methods requiring ground-truth camera parameters.

08 Dec 2025
The Multi-view Pyramid Transformer (MVP) introduces a scalable architecture for efficient 3D reconstruction from numerous input images, leveraging a dual attention hierarchy and pyramidal feature aggregation. It processes up to 128 views in under one second on a single H100 GPU, achieving superior quality compared to prior single-pass models and often matching or exceeding optimization-based 3D Gaussian Splatting on various benchmarks.

10 Dec 2025
Video head swapping aims to replace the entire head of a video subject, including facial identity, head shape, and hairstyle, with that of a reference image, while preserving the target body, background, and motion dynamics. Due to the lack of ground-truth paired swapping data, prior methods typically train on cross-frame pairs of the same person within a video and rely on mask-based inpainting to mitigate identity leakage. Beyond potential boundary artifacts, this paradigm struggles to recover essential cues occluded by the mask, such as facial pose, expressions, and motion dynamics. To address these issues, we prompt a video editing model to synthesize new heads for existing videos as fake swapping inputs, while maintaining frame-synchronized facial poses and expressions. This yields HeadSwapBench, the first cross-identity paired dataset for video head swapping, which supports both training (\TrainNum{} videos) and benchmarking (\TestNum{} videos) with genuine outputs. Leveraging this paired supervision, we propose DirectSwap, a mask-free, direct video head-swapping framework that extends an image U-Net into a video diffusion model with a motion module and conditioning inputs. Furthermore, we introduce the Motion- and Expression-Aware Reconstruction (MEAR) loss, which reweights the diffusion loss per pixel using frame-difference magnitudes and facial-landmark proximity, thereby enhancing cross-frame coherence in motion and expressions. Extensive experiments demonstrate that DirectSwap achieves state-of-the-art visual quality, identity fidelity, and motion and expression consistency across diverse in-the-wild video scenes. We will release the source code and the HeadSwapBench dataset to facilitate future research.

10 Dec 2025
Radiance field representations have recently been explored in the latent space of VAEs that are commonly used by diffusion models. This direction offers efficient rendering and seamless integration with diffusion-based pipelines. However, these methods face a fundamental limitation: The VAE latent space lacks multi-view consistency, leading to blurred textures and missing details during 3D reconstruction. Existing approaches attempt to address this by fine-tuning the VAE, at the cost of reconstruction quality, or by relying on pre-trained diffusion models to recover fine-grained details, at the risk of some hallucinations. We present Splatent, a diffusion-based enhancement framework designed to operate on top of 3D Gaussian Splatting (3DGS) in the latent space of VAEs. Our key insight departs from the conventional 3D-centric view: rather than reconstructing fine-grained details in 3D space, we recover them in 2D from input views through multi-view attention mechanisms. This approach preserves the reconstruction quality of pretrained VAEs while achieving faithful detail recovery. Evaluated across multiple benchmarks, Splatent establishes a new state-of-the-art for VAE latent radiance field reconstruction. We further demonstrate that integrating our method with existing feed-forward frameworks, consistently improves detail preservation, opening new possibilities for high-quality sparse-view 3D reconstruction.
10 Dec 2025

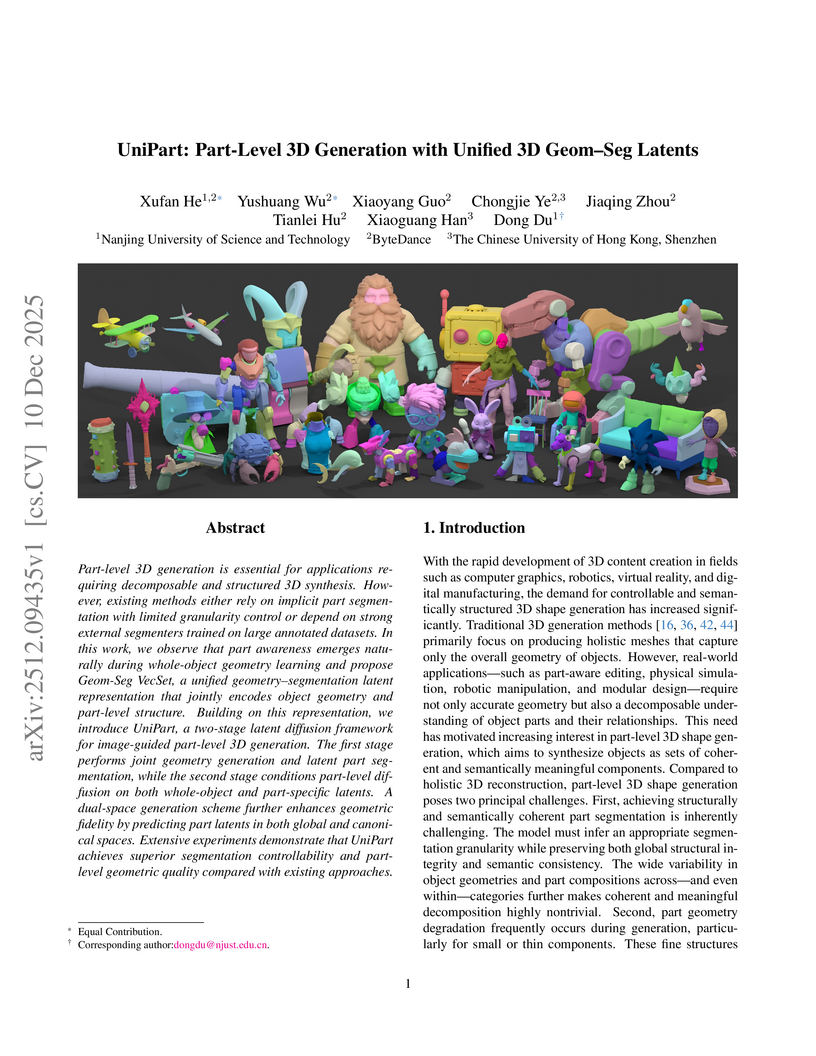
Part-level 3D generation is essential for applications requiring decomposable and structured 3D synthesis. However, existing methods either rely on implicit part segmentation with limited granularity control or depend on strong external segmenters trained on large annotated datasets. In this work, we observe that part awareness emerges naturally during whole-object geometry learning and propose Geom-Seg VecSet, a unified geometry-segmentation latent representation that jointly encodes object geometry and part-level structure. Building on this representation, we introduce UniPart, a two-stage latent diffusion framework for image-guided part-level 3D generation. The first stage performs joint geometry generation and latent part segmentation, while the second stage conditions part-level diffusion on both whole-object and part-specific latents. A dual-space generation scheme further enhances geometric fidelity by predicting part latents in both global and canonical spaces. Extensive experiments demonstrate that UniPart achieves superior segmentation controllability and part-level geometric quality compared with existing approaches.

08 Dec 2025
MOCA (Mixture-of-Components Attention) introduces a novel attention mechanism within a compositional Diffusion Transformer framework, enabling scalable and high-fidelity generation of 3D objects and scenes from images. This method effectively addresses the quadratic computational cost of previous approaches by intelligently routing attention based on component importance, successfully generating assets with up to 32 components per sample.

08 Dec 2025

ViSA presents a real-time framework for creating high-fidelity upper-body avatars from a single image by merging 3D reconstruction's geometric stability with video diffusion models' photorealistic dynamics. The method achieves superior visual quality (PSNR 22.09, LPIPS 0.043) and identity preservation at 15.15 FPS, surpassing existing state-of-the-art techniques.

09 Dec 2025
A modular neural image signal processing framework was developed to transform raw sensor data into high-quality sRGB images, addressing the limitations of "black-box" neural ISPs by offering fine-grained control and enhanced interpretability. This system achieves state-of-the-art performance, supports diverse photographic styles, and generalizes robustly to various cameras, demonstrated by quantitative metrics and user preferences.

09 Dec 2025
Simultaneous Localization and Mapping (SLAM) is a foundational component in robotics, AR/VR, and autonomous systems. With the rising focus on spatial AI in recent years, combining SLAM with semantic understanding has become increasingly important for enabling intelligent perception and interaction. Recent efforts have explored this integration, but they often rely on depth sensors or closed-set semantic models, limiting their scalability and adaptability in open-world environments. In this work, we present OpenMonoGS-SLAM, the first monocular SLAM framework that unifies 3D Gaussian Splatting (3DGS) with open-set semantic understanding. To achieve our goal, we leverage recent advances in Visual Foundation Models (VFMs), including MASt3R for visual geometry and SAM and CLIP for open-vocabulary semantics. These models provide robust generalization across diverse tasks, enabling accurate monocular camera tracking and mapping, as well as a rich understanding of semantics in open-world environments. Our method operates without any depth input or 3D semantic ground truth, relying solely on self-supervised learning objectives. Furthermore, we propose a memory mechanism specifically designed to manage high-dimensional semantic features, which effectively constructs Gaussian semantic feature maps, leading to strong overall performance. Experimental results demonstrate that our approach achieves performance comparable to or surpassing existing baselines in both closed-set and open-set segmentation tasks, all without relying on supplementary sensors such as depth maps or semantic annotations.

09 Dec 2025
Recent advancements in Gaussian Splatting have enabled increasingly accurate reconstruction of photorealistic head avatars, opening the door to numerous applications in visual effects, videoconferencing, and virtual reality. This, however, comes with the lack of intuitive editability offered by traditional triangle mesh-based methods. In contrast, we propose a method that combines the accuracy and fidelity of 2D Gaussian Splatting with the intuitiveness of UV texture mapping. By embedding each canonical Gaussian primitive's local frame into a patch in the UV space of a template mesh in a computationally efficient manner, we reconstruct continuous editable material head textures from a single monocular video on a conventional UV domain. Furthermore, we leverage an efficient physically based reflectance model to enable relighting and editing of these intrinsic material maps. Through extensive comparisons with state-of-the-art methods, we demonstrate the accuracy of our reconstructions, the quality of our relighting results, and the ability to provide intuitive controls for modifying an avatar's appearance and geometry via texture mapping without additional optimization.

09 Dec 2025
Recent progress in text-to-video generation has achieved remarkable realism, yet fine-grained control over camera motion and orientation remains elusive. Existing approaches typically encode camera trajectories through relative or ambiguous representations, limiting explicit geometric control. We introduce GimbalDiffusion, a framework that enables camera control grounded in physical-world coordinates, using gravity as a global reference. Instead of describing motion relative to previous frames, our method defines camera trajectories in an absolute coordinate system, allowing precise and interpretable control over camera parameters without requiring an initial reference frame. We leverage panoramic 360-degree videos to construct a wide variety of camera trajectories, well beyond the predominantly straight, forward-facing trajectories seen in conventional video data. To further enhance camera guidance, we introduce null-pitch conditioning, an annotation strategy that reduces the model's reliance on text content when conflicting with camera specifications (e.g., generating grass while the camera points towards the sky). Finally, we establish a benchmark for camera-aware video generation by rebalancing SpatialVID-HQ for comprehensive evaluation under wide camera pitch variation. Together, these contributions advance the controllability and robustness of text-to-video models, enabling precise, gravity-aligned camera manipulation within generative frameworks.
There are no more papers matching your filters at the moment.
