
28 Apr 2025


Perception Encoder introduces a family of vision models that achieve state-of-the-art performance across diverse vision and vision-language tasks, demonstrating that general, high-quality visual features can be extracted from the intermediate layers of a single, contrastively-trained network. It provides specific alignment tuning methods to make these features accessible for tasks ranging from zero-shot classification to dense spatial prediction and multimodal language understanding.

24 Dec 2023




This paper systematically studies using powerful language models as automated judges for evaluating other LLMs, introducing the MT-bench and Chatbot Arena benchmarks for human-preference-aligned assessment. It demonstrates that GPT-4, when used as a judge, exhibits high agreement with human evaluations, provides insights into LLM judge biases, and advocates for a hybrid evaluation framework to holistically measure LLM capabilities and human alignment.

18 Oct 2025
South China University of Technology California Institute of Technology
California Institute of Technology University of Cambridge
University of Cambridge Monash UniversityShanghai Artificial Intelligence Laboratory
Monash UniversityShanghai Artificial Intelligence Laboratory Chinese Academy of Sciences
Chinese Academy of Sciences University College London
University College London Fudan University
Fudan University Shanghai Jiao Tong University
Shanghai Jiao Tong University Nanjing University
Nanjing University Stanford University
Stanford University The Chinese University of Hong Kong
The Chinese University of Hong Kong The Hong Kong Polytechnic UniversityThe Chinese University of Hong Kong, Shenzhen
The Hong Kong Polytechnic UniversityThe Chinese University of Hong Kong, Shenzhen The University of Hong KongMBZUAI
The University of Hong KongMBZUAI Purdue University
Purdue University Virginia Tech
Virginia Tech HKUSTUniversity College DublinUNC-Chapel HillFuzhou UniversityNorth University of ChinaChina Pharmaceutical UniversityBeijing Institute of Heart, Lung and Blood Vessel Diseases
HKUSTUniversity College DublinUNC-Chapel HillFuzhou UniversityNorth University of ChinaChina Pharmaceutical UniversityBeijing Institute of Heart, Lung and Blood Vessel Diseases
California Institute of TechnologyUniversity of CambridgeMonash UniversityShanghai Artificial Intelligence LaboratoryChinese Academy of SciencesUniversity College LondonFudan UniversityShanghai Jiao Tong UniversityNanjing UniversityStanford UniversityThe Chinese University of Hong KongThe Hong Kong Polytechnic UniversityThe Chinese University of Hong Kong, ShenzhenThe University of Hong KongMBZUAIPurdue UniversityVirginia TechHKUSTUniversity College DublinUNC-Chapel HillFuzhou UniversityNorth University of ChinaChina Pharmaceutical UniversityBeijing Institute of Heart, Lung and Blood Vessel Diseases
A comprehensive survey by researchers from Shanghai AI Lab and various global institutions outlines the intricate relationship between scientific large language models (Sci-LLMs) and their data foundations, tracing their evolution towards autonomous agents for scientific discovery. The paper establishes a taxonomy for scientific data and knowledge, meticulously reviews over 270 datasets and 190 benchmarks, and identifies critical data challenges alongside future paradigms.

16 Oct 2025
A new method called Elastic-Cache manages Key-Value (KV) caches in Diffusion Large Language Models (DLMs) by adaptively updating them based on attention patterns and layer-specific dynamics. This approach yields up to a 45.1x speedup over baselines on tasks like GSM8K, maintaining or improving generation accuracy across various text-only and multimodal benchmarks.
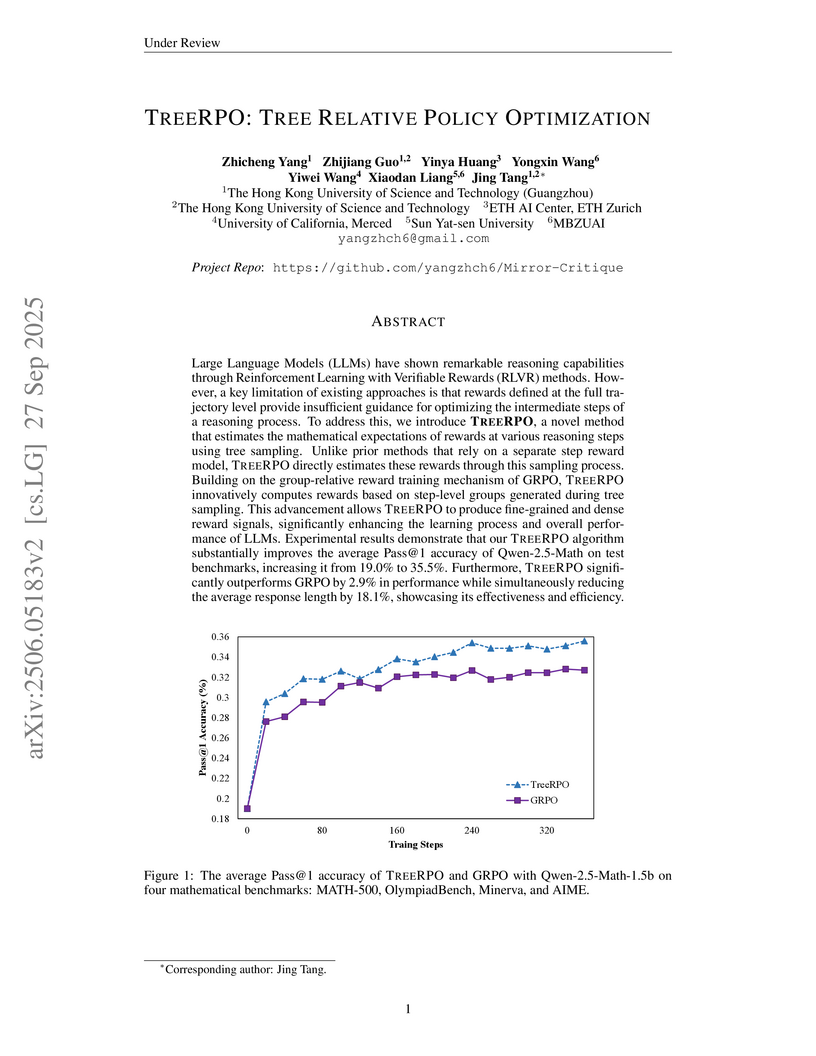
27 Sep 2025



TREERPO enhances Large Language Model reasoning by employing a novel tree sampling mechanism to generate fine-grained, step-level reward signals without requiring a separate process reward model. This method improves Pass@1 accuracy by up to 16.5% for Qwen2.5-Math-1.5B and reduces average response length by 18.1% compared to GRPO.

14 Oct 2025
DR.LLM introduces a retrofittable framework for Large Language Models that dynamically adjusts computational depth, achieving a mean accuracy gain of +2.25 percentage points and 5.0 fewer layers executed on average on in-domain tasks, while robustly generalizing to out-of-domain benchmarks with minimal accuracy drop.

28 Oct 2025
Researchers from UC San Diego, MBZUAI, and UC Berkeley developed VSA, a trainable sparse attention mechanism for video Diffusion Transformers. It reduces computational costs and inference latency for video generation by up to 2.53x during training and over 2x during inference while maintaining or improving quality.

23 Jul 2025
Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models. this https URL

16 Sep 2025

ActiveVLN introduces a two-stage framework that enhances Vision-and-Language Navigation agents through active exploration via multi-turn Reinforcement Learning. The method achieves an 11.6% success rate increase on R2R Val-Unseen and demonstrates competitive performance on RxR Val-Unseen with a smaller model and less data, effectively mitigating covariate shift and reducing expert data dependency.
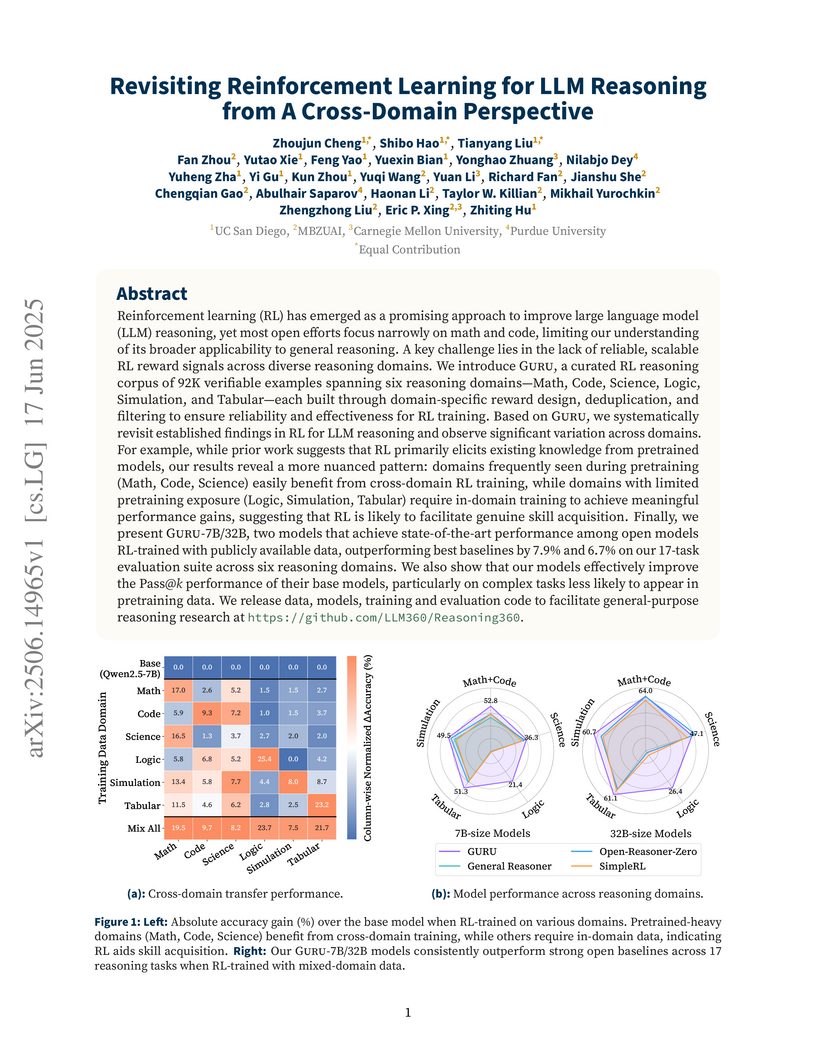
17 Jun 2025
The paper introduces GURU, a multi-domain reinforcement learning corpus with 92K verifiable examples across six distinct reasoning domains, enabling the training of GURU-7B and GURU-32B models. These models achieve state-of-the-art general reasoning capabilities among open RL-trained LLMs, demonstrating how multi-domain RL can lead to robust, generalized reasoning abilities.

26 Aug 2025
The paper introduces Token Order Prediction (TOP), an auxiliary objective for large language model pretraining that trains models to predict the relative proximity of future tokens rather than their exact identity. This method consistently enhances performance across standard NLP benchmarks compared to next-token prediction baselines and multi-token prediction approaches, while being more parameter-efficient.

23 Sep 2025


Researchers from the University of Rochester, University of Southern California, and MBZUAI developed a framework that quantifies uncertainty in Large Language Model (LLM) evaluations for rating-based tasks. This method leverages conformal prediction with a novel ordinal boundary adjustment, yielding statistically guaranteed prediction intervals and reducing bias in LLM judgments.

13 Nov 2025
 University of Washington
University of Washington University of Amsterdam
University of Amsterdam University of Waterloo
University of Waterloo Northeastern University
Northeastern University Imperial College LondonUniversity of Zurich
Imperial College LondonUniversity of Zurich New York UniversityBAAIKorea University
New York UniversityBAAIKorea University University of OxfordStanford University
University of OxfordStanford University Cornell University
Cornell University Peking University
Peking University McGill University
McGill University Allen Institute for AIAarhus University
Allen Institute for AIAarhus University University of Pennsylvania
University of Pennsylvania Hugging Face
Hugging Face Johns Hopkins UniversityMBZUAIJina AIHSE UniversitySapienza University of Rome
Johns Hopkins UniversityMBZUAIJina AIHSE UniversitySapienza University of Rome Princeton UniversityITMO UniversityINSA-LyonCentraleSupélec
Princeton UniversityITMO UniversityINSA-LyonCentraleSupélec Durham UniversityCISCO SystemsHong Kong UniversityFRC CSC RASKoç University
Durham UniversityCISCO SystemsHong Kong UniversityFRC CSC RASKoç University ServiceNowContextual AIComenius University BratislavaApart ResearchWikitHeritage Institute Of TechnologySalesforceThe London Institute of Banking and FinanceTano LabsNational Information Processing InstituteEskerArtefact Research CenterR. V. College of EngineeringEllamindOcciglotSaluteDevicesNirma UniversityRobert Koch InstituteWrocław UniversityIlluin TechnologyI.I.T Madras
ServiceNowContextual AIComenius University BratislavaApart ResearchWikitHeritage Institute Of TechnologySalesforceThe London Institute of Banking and FinanceTano LabsNational Information Processing InstituteEskerArtefact Research CenterR. V. College of EngineeringEllamindOcciglotSaluteDevicesNirma UniversityRobert Koch InstituteWrocław UniversityIlluin TechnologyI.I.T Madras
A collaborative effort produced MMTEB, the Massive Multilingual Text Embedding Benchmark, which offers over 500 quality-controlled evaluation tasks across more than 250 languages and 10 categories. The benchmark incorporates significant computational optimizations to enable accessible evaluation and reveals that instruction tuning enhances model performance, with smaller, broadly multilingual models often outperforming larger, English-centric models in low-resource contexts.

13 Oct 2025
Revealing hidden causal variables alongside the underlying causal mechanisms is essential to the development of science. Despite the progress in the past decades, existing practice in causal discovery (CD) heavily relies on high-quality measured variables, which are usually given by human experts. In fact, the lack of well-defined high-level variables behind unstructured data has been a longstanding roadblock to a broader real-world application of CD. This procedure can naturally benefit from an automated process that can suggest potential hidden variables in the system. Interestingly, Large language models (LLMs) are trained on massive observations of the world and have demonstrated great capability in processing unstructured data. To leverage the power of LLMs, we develop a new framework termed Causal representatiOn AssistanT (COAT) that incorporates the rich world knowledge of LLMs to propose useful measured variables for CD with respect to high-value target variables on their paired unstructured data. Instead of directly inferring causality with LLMs, COAT constructs feedback from intermediate CD results to LLMs to refine the proposed variables. Given the target variable and the paired unstructured data, we first develop COAT-MB that leverages the predictivity of the proposed variables to iteratively uncover the Markov Blanket of the target variable. Built upon COAT-MB, COAT-PAG further extends to uncover a more complete causal graph, i.e., Partial Ancestral Graph, by iterating over the target variables and actively seeking new high-level variables. Moreover, the reliable CD capabilities of COAT also extend the debiased causal inference to unstructured data by discovering an adjustment set. We establish theoretical guarantees for the CD results and verify their efficiency and reliability across realistic benchmarks and real-world case studies.

01 May 2025


BrowseComp-ZH introduces the first comprehensive benchmark for evaluating large language models' web browsing and reasoning capabilities in the Chinese information environment. The benchmark reveals consistently low performance across models and underscores the unique challenges of effectively integrating and reconciling retrieved information from the complex Chinese web.

17 Oct 2025


By introducing "trapping-free" ternary quantization, Tequila effectively reactivates inactive weights in Large Language Models, enabling near full-precision accuracy on zero-shot benchmarks while achieving a 3.0x inference speedup and reducing training data by 10x for efficient edge deployment.
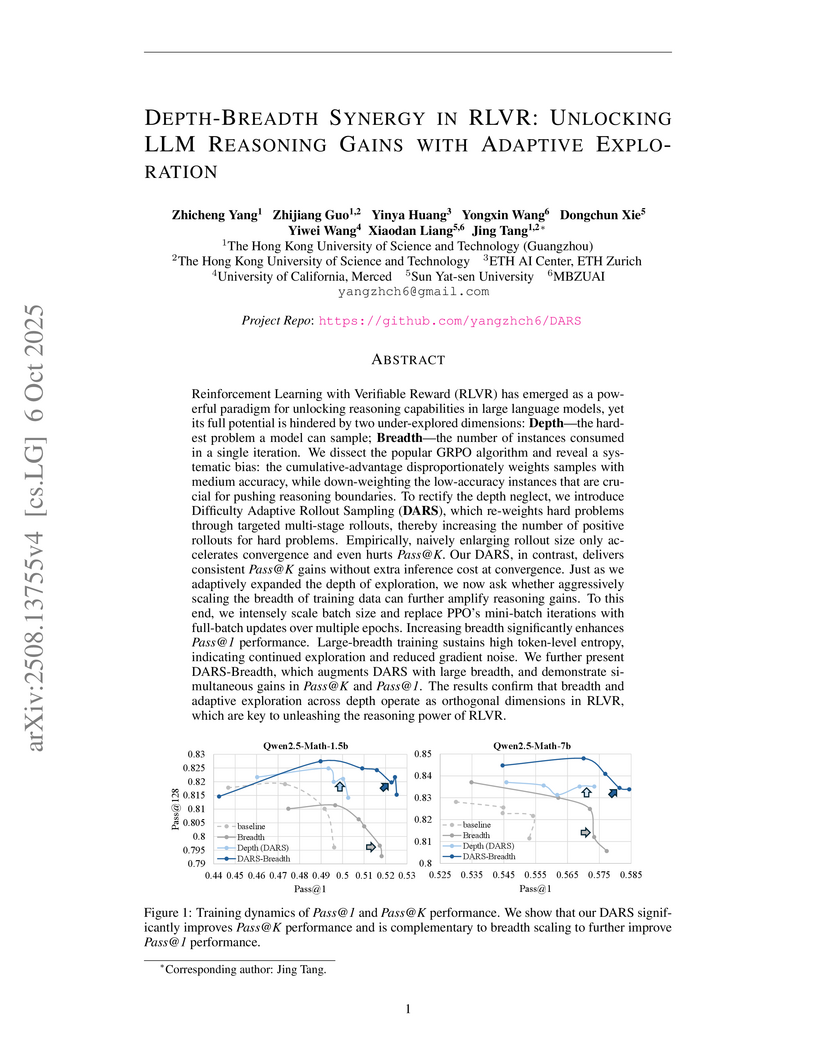
06 Oct 2025
Reinforcement Learning with Verifiable Reward (RLVR) has emerged as a powerful paradigm for unlocking reasoning capabilities in large language models, yet its full potential is hindered by two under-explored dimensions: Depth-the hardest problem a model can sample; Breadth-the number of instances consumed in a single iteration. We dissect the popular GRPO algorithm and reveal a systematic bias: the cumulative-advantage disproportionately weights samples with medium accuracy, while down-weighting the low-accuracy instances that are crucial for pushing reasoning boundaries. To rectify the depth neglect, we introduce Difficulty Adaptive Rollout Sampling (DARS), which re-weights hard problems through targeted multi-stage rollouts, thereby increasing the number of positive rollouts for hard problems. Empirically, naively enlarging rollout size only accelerates convergence and even hurts Pass@K. Our DARS, in contrast, delivers consistent Pass@K gains without extra inference cost at convergence. Just as we adaptively expanded the depth of exploration, we now ask whether aggressively scaling the breadth of training data can further amplify reasoning gains. To this end, we intensely scale batch size and replace PPO's mini-batch iterations with full-batch updates over multiple epochs. Increasing breadth significantly enhances Pass@1 performance. Large-breadth training sustains high token-level entropy, indicating continued exploration and reduced gradient noise. We further present DARS-B, which augments DARS with large breadth, and demonstrate simultaneous gains in Pass@K and Pass@1. The results confirm that breadth and adaptive exploration across depth operate as orthogonal dimensions in RLVR, which are key to unleashing the reasoning power of RLVR.

13 Oct 2025
Researchers from MBZUAI, Monash University, and other institutions developed StreamAgent, an anticipatory agent for streaming video understanding that integrates proactive temporal and spatial anticipation with a novel streaming Key-Value cache. This framework achieves state-of-the-art accuracy on streaming benchmarks, demonstrating up to 10.7% improvement in "Forward Active Responding" over prior models while reducing latency by up to 30% compared to existing efficient video processing methods.

20 Jul 2024

Researchers from Monash University and collaborating institutions introduce LongVLM, a VideoLLM that achieves fine-grained understanding of long videos by efficiently integrating local, temporally ordered segment features with global semantic context. The model outperforms previous state-of-the-art methods on the VideoChatGPT benchmark, showing improvements in Detail Orientation (+0.17) and Consistency (+0.65), and achieves higher accuracy on zero-shot video QA datasets like ANET-QA, MSRVTT-QA, and MSVD-QA.

25 Jun 2025
Researchers from MBZUAI, Sun Yat-sen University, and SUSTech developed A0, a hierarchical diffusion model for general robotic manipulation that understands spatial affordances by predicting object-centric contact points and post-contact trajectories. The embodiment-agnostic model achieved an average success rate of 62.50% on Franka and 53.75% on Kinova robots in real-world tasks, outperforming state-of-the-art methods, particularly in trajectory-intensive manipulations, with fewer execution steps.
There are no more papers matching your filters at the moment.
