
20 Jul 2023



Metric3D presents a method for zero-shot metric 3D prediction from a single image, enabling the inference of real-world scale and distances regardless of the camera model. This is achieved by explicitly accounting for camera focal length through a Canonical Camera Transformation Module and training on a massive dataset of over 8 million images, demonstrating improved performance over existing state-of-the-art affine-invariant methods and significantly reducing scale drift in monocular SLAM systems.

05 Oct 2023

Self-supervised monocular depth estimation has shown impressive results in
static scenes. It relies on the multi-view consistency assumption for training
networks, however, that is violated in dynamic object regions and occlusions.
Consequently, existing methods show poor accuracy in dynamic scenes, and the
estimated depth map is blurred at object boundaries because they are usually
occluded in other training views. In this paper, we propose SC-DepthV3 for
addressing the challenges. Specifically, we introduce an external pretrained
monocular depth estimation model for generating single-image depth prior,
namely pseudo-depth, based on which we propose novel losses to boost
self-supervised training. As a result, our model can predict sharp and accurate
depth maps, even when training from monocular videos of highly-dynamic scenes.
We demonstrate the significantly superior performance of our method over
previous methods on six challenging datasets, and we provide detailed ablation
studies for the proposed terms. Source code and data will be released at
this https URL

13 Mar 2025
In this research, we propose a novel denoising diffusion model based on
shortest-path modeling that optimizes residual propagation to enhance both
denoising efficiency and quality. Drawing on Denoising Diffusion Implicit
Models (DDIM) and insights from graph theory, our model, termed the Shortest
Path Diffusion Model (ShortDF), treats the denoising process as a shortest-path
problem aimed at minimizing reconstruction error. By optimizing the initial
residuals, we improve the efficiency of the reverse diffusion process and the
quality of the generated samples. Extensive experiments on multiple standard
benchmarks demonstrate that ShortDF significantly reduces diffusion time (or
steps) while enhancing the visual fidelity of generated samples compared to
prior arts. This work, we suppose, paves the way for interactive
diffusion-based applications and establishes a foundation for rapid data
generation. Code is available at this https URL

12 Mar 2024

Researchers from Huazhong University of Science and Technology and DJI Technology developed AFNet, a depth estimation system that adaptively fuses single-view and multi-view cues to maintain high accuracy and superior robustness, particularly when camera poses are noisy. The method achieved state-of-the-art performance on DDAD and KITTI datasets, reducing AbsRel error on KITTI by 27.8% compared to previous methods, and demonstrated improved precision in dynamic object regions.

11 Dec 2023


Multi-camera setups find widespread use across various applications, such as autonomous driving, as they greatly expand sensing capabilities. Despite the fast development of Neural radiance field (NeRF) techniques and their wide applications in both indoor and outdoor scenes, applying NeRF to multi-camera systems remains very challenging. This is primarily due to the inherent under-calibration issues in multi-camera setup, including inconsistent imaging effects stemming from separately calibrated image signal processing units in diverse cameras, and system errors arising from mechanical vibrations during driving that affect relative camera poses. In this paper, we present UC-NeRF, a novel method tailored for novel view synthesis in under-calibrated multi-view camera systems. Firstly, we propose a layer-based color correction to rectify the color inconsistency in different image regions. Second, we propose virtual warping to generate more viewpoint-diverse but color-consistent virtual views for color correction and 3D recovery. Finally, a spatiotemporally constrained pose refinement is designed for more robust and accurate pose calibration in multi-camera systems. Our method not only achieves state-of-the-art performance of novel view synthesis in multi-camera setups, but also effectively facilitates depth estimation in large-scale outdoor scenes with the synthesized novel views.

18 Oct 2022
In this paper, we address monocular depth estimation with deep neural
networks. To enable training of deep monocular estimation models with various
sources of datasets, state-of-the-art methods adopt image-level normalization
strategies to generate affine-invariant depth representations. However,
learning with image-level normalization mainly emphasizes the relations of
pixel representations with the global statistic in the images, such as the
structure of the scene, while the fine-grained depth difference may be
overlooked. In this paper, we propose a novel multi-scale depth normalization
method that hierarchically normalizes the depth representations based on
spatial information and depth distributions. Compared with previous
normalization strategies applied only at the holistic image level, the proposed
hierarchical normalization can effectively preserve the fine-grained details
and improve accuracy. We present two strategies that define the hierarchical
normalization contexts in the depth domain and the spatial domain,
respectively. Our extensive experiments show that the proposed normalization
strategy remarkably outperforms previous normalization methods, and we set new
state-of-the-art on five zero-shot transfer benchmark datasets.
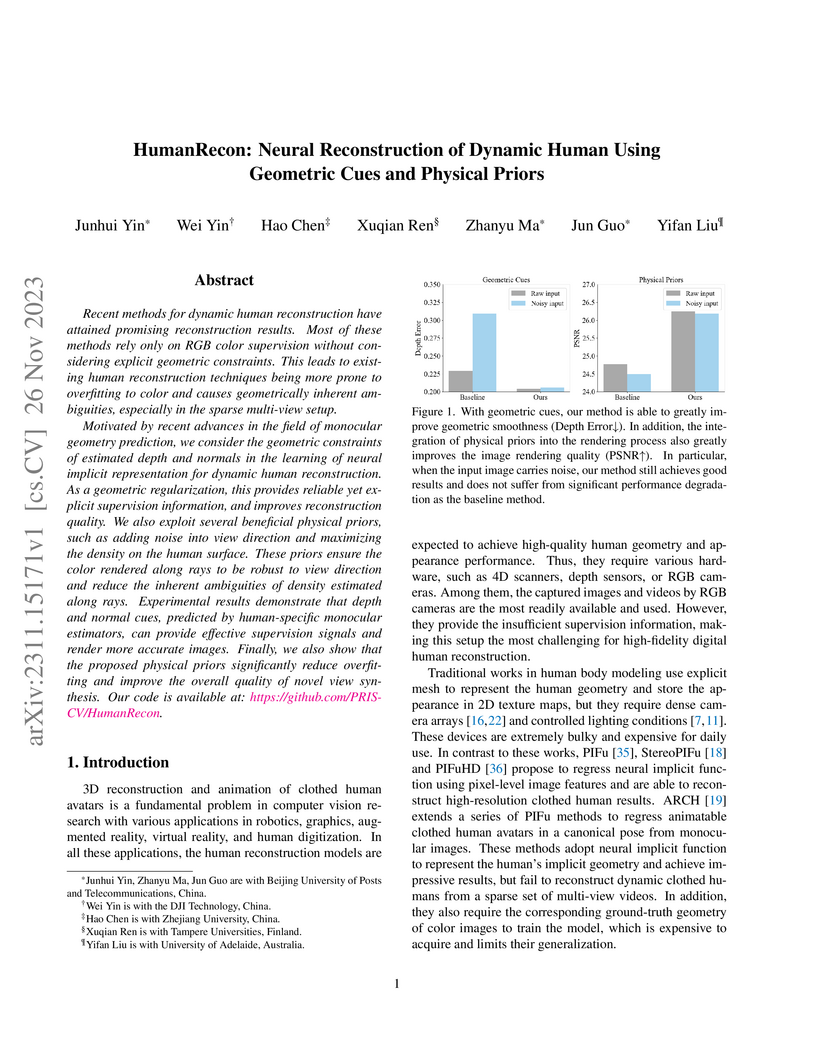
26 Nov 2023
Recent methods for dynamic human reconstruction have attained promising reconstruction results. Most of these methods rely only on RGB color supervision without considering explicit geometric constraints. This leads to existing human reconstruction techniques being more prone to overfitting to color and causes geometrically inherent ambiguities, especially in the sparse multi-view setup.
Motivated by recent advances in the field of monocular geometry prediction, we consider the geometric constraints of estimated depth and normals in the learning of neural implicit representation for dynamic human reconstruction. As a geometric regularization, this provides reliable yet explicit supervision information, and improves reconstruction quality. We also exploit several beneficial physical priors, such as adding noise into view direction and maximizing the density on the human surface. These priors ensure the color rendered along rays to be robust to view direction and reduce the inherent ambiguities of density estimated along rays. Experimental results demonstrate that depth and normal cues, predicted by human-specific monocular estimators, can provide effective supervision signals and render more accurate images. Finally, we also show that the proposed physical priors significantly reduce overfitting and improve the overall quality of novel view synthesis. Our code is available at:~\href{this https URL}{this https URL}.

18 Sep 2023

In this study, we address the challenge of 3D scene structure recovery from
monocular depth estimation. While traditional depth estimation methods leverage
labeled datasets to directly predict absolute depth, recent advancements
advocate for mix-dataset training, enhancing generalization across diverse
scenes. However, such mixed dataset training yields depth predictions only up
to an unknown scale and shift, hindering accurate 3D reconstructions. Existing
solutions necessitate extra 3D datasets or geometry-complete depth annotations,
constraints that limit their versatility. In this paper, we propose a learning
framework that trains models to predict geometry-preserving depth without
requiring extra data or annotations. To produce realistic 3D structures, we
render novel views of the reconstructed scenes and design loss functions to
promote depth estimation consistency across different views. Comprehensive
experiments underscore our framework's superior generalization capabilities,
surpassing existing state-of-the-art methods on several benchmark datasets
without leveraging extra training information. Moreover, our innovative loss
functions empower the model to autonomously recover domain-specific
scale-and-shift coefficients using solely unlabeled images.

10 Aug 2023
3D scene reconstruction is a long-standing vision task. Existing approaches
can be categorized into geometry-based and learning-based methods. The former
leverages multi-view geometry but can face catastrophic failures due to the
reliance on accurate pixel correspondence across views. The latter was
proffered to mitigate these issues by learning 2D or 3D representation
directly. However, without a large-scale video or 3D training data, it can
hardly generalize to diverse real-world scenarios due to the presence of tens
of millions or even billions of optimization parameters in the deep network.
Recently, robust monocular depth estimation models trained with large-scale
datasets have been proven to possess weak 3D geometry prior, but they are
insufficient for reconstruction due to the unknown camera parameters, the
affine-invariant property, and inter-frame inconsistency. Here, we propose a
novel test-time optimization approach that can transfer the robustness of
affine-invariant depth models such as LeReS to challenging diverse scenes while
ensuring inter-frame consistency, with only dozens of parameters to optimize
per video frame. Specifically, our approach involves freezing the pre-trained
affine-invariant depth model's depth predictions, rectifying them by optimizing
the unknown scale-shift values with a geometric consistency alignment module,
and employing the resulting scale-consistent depth maps to robustly obtain
camera poses and achieve dense scene reconstruction, even in low-texture
regions. Experiments show that our method achieves state-of-the-art
cross-dataset reconstruction on five zero-shot testing datasets.

26 Apr 2023

This paper discusses the results for the second edition of the Monocular
Depth Estimation Challenge (MDEC). This edition was open to methods using any
form of supervision, including fully-supervised, self-supervised, multi-task or
proxy depth. The challenge was based around the SYNS-Patches dataset, which
features a wide diversity of environments with high-quality dense ground-truth.
This includes complex natural environments, e.g. forests or fields, which are
greatly underrepresented in current benchmarks.
The challenge received eight unique submissions that outperformed the
provided SotA baseline on any of the pointcloud- or image-based metrics. The
top supervised submission improved relative F-Score by 27.62%, while the top
self-supervised improved it by 16.61%. Supervised submissions generally
leveraged large collections of datasets to improve data diversity.
Self-supervised submissions instead updated the network architecture and
pretrained backbones. These results represent a significant progress in the
field, while highlighting avenues for future research, such as reducing
interpolation artifacts at depth boundaries, improving self-supervised indoor
performance and overall natural image accuracy.
There are no more papers matching your filters at the moment.
