
05 Dec 2024

Eugene Wu of Columbia University establishes a theoretical framework for "faithful database visualization," proposing that visualizations should directly map not only data content but also underlying database constraints, moving beyond the prevalent single-table data model. This work demonstrates how common visualization designs can be understood as emergent properties of multi-table data structures and their visual constraint preservation.

25 Jun 2025
A new framework, Diffusion Steering via Reinforcement Learning (DSRL), enables rapid, autonomous adaptation of pre-trained diffusion policies for robotic control by learning to manipulate their latent noise input space. This approach achieves high sample efficiency and black-box compatibility, making it practical for real-world fine-tuning of large generalist robot policies such as π0.

08 Jan 2025



A comprehensive survey details the field of Retrieval-Augmented Generation with Graphs (GraphRAG), proposing a unified framework for integrating graph-structured data into RAG systems and specializing its application across ten distinct domains, providing a structured understanding of current techniques and future research directions.

17 Oct 2025


Amazon Web Services researchers developed Chronos-2, a pretrained time series model designed for zero-shot forecasting across univariate, multivariate, and covariate-informed tasks using a unified framework. The model achieved an average win rate of 90.7% and a 47.3% skill score on the fev-bench, demonstrating superior performance, especially when leveraging in-context learning for covariate data.

12 Jun 2023
 ETH Zurich
ETH Zurich KAIST
KAIST University of WashingtonRensselaer Polytechnic Institute
University of WashingtonRensselaer Polytechnic Institute Google DeepMind
Google DeepMind University of Amsterdam
University of Amsterdam University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of CambridgeHeidelberg University
University of CambridgeHeidelberg University University of WaterlooFacebook
University of WaterlooFacebook Carnegie Mellon University
Carnegie Mellon University University of Southern California
University of Southern California Google
Google New York UniversityUniversity of Stuttgart
New York UniversityUniversity of Stuttgart UC Berkeley
UC Berkeley National University of Singapore
National University of Singapore University College London
University College London University of OxfordLMU Munich
University of OxfordLMU Munich Shanghai Jiao Tong University
Shanghai Jiao Tong University University of California, Irvine
University of California, Irvine Tsinghua University
Tsinghua University Stanford University
Stanford University University of Michigan
University of Michigan University of Copenhagen
University of Copenhagen The Chinese University of Hong KongUniversity of Melbourne
The Chinese University of Hong KongUniversity of Melbourne MetaUniversity of Edinburgh
MetaUniversity of Edinburgh OpenAI
OpenAI The University of Texas at Austin
The University of Texas at Austin Cornell University
Cornell University University of California, San DiegoYonsei University
University of California, San DiegoYonsei University McGill University
McGill University Boston UniversityUniversity of Bamberg
Boston UniversityUniversity of Bamberg Nanyang Technological University
Nanyang Technological University Microsoft
Microsoft KU Leuven
KU Leuven Columbia UniversityUC Santa Barbara
Columbia UniversityUC Santa Barbara Allen Institute for AIGerman Research Center for Artificial Intelligence (DFKI)
Allen Institute for AIGerman Research Center for Artificial Intelligence (DFKI) University of Pennsylvania
University of Pennsylvania Johns Hopkins University
Johns Hopkins University Arizona State University
Arizona State University University of Maryland
University of Maryland University of TokyoUniversity of North Carolina at Chapel HillHebrew University of JerusalemAmazonTilburg UniversityUniversity of Massachusetts AmherstUniversity of RochesterUniversity of Duisburg-EssenSapienza University of RomeUniversity of Sheffield
University of TokyoUniversity of North Carolina at Chapel HillHebrew University of JerusalemAmazonTilburg UniversityUniversity of Massachusetts AmherstUniversity of RochesterUniversity of Duisburg-EssenSapienza University of RomeUniversity of Sheffield Princeton University
Princeton University HKUSTUniversity of TübingenTU BerlinSaarland UniversityTechnical University of DarmstadtUniversity of HaifaUniversity of TrentoUniversity of MontrealBilkent UniversityUniversity of Cape TownBar Ilan UniversityIBMUniversity of Mannheim
HKUSTUniversity of TübingenTU BerlinSaarland UniversityTechnical University of DarmstadtUniversity of HaifaUniversity of TrentoUniversity of MontrealBilkent UniversityUniversity of Cape TownBar Ilan UniversityIBMUniversity of Mannheim ServiceNowPotsdam UniversityPolish-Japanese Academy of Information TechnologySalesforceASAPPAI21 LabsValencia Polytechnic UniversityUniversity of Trento, Italy
ServiceNowPotsdam UniversityPolish-Japanese Academy of Information TechnologySalesforceASAPPAI21 LabsValencia Polytechnic UniversityUniversity of Trento, Italy

A large-scale and diverse benchmark, BIG-bench, was introduced to rigorously evaluate the capabilities and limitations of large language models across 204 tasks. The evaluation revealed that even state-of-the-art models currently achieve aggregate scores below 20 (on a 0-100 normalized scale), indicating significantly lower performance compared to human experts.

15 Jul 2025




Chain of Thought (CoT) monitorability offers a distinct capability for AI safety by providing insight into an AI's internal reasoning processes, including potential intent to misbehave. This paper argues that while currently useful for detecting misbehavior and misalignment, this property is fragile and requires proactive research and development to preserve it as AI systems scale.

05 Aug 2025


The open-source Goedel-Prover-V2 series of language models improves formal theorem proving in Lean through scaffolded data synthesis and verifier-guided self-correction. Its 32B-parameter model achieves 90.4% pass@32 on MiniF2F, outperforming a 671B-parameter system by a large margin while being 20 times smaller, and establishes a new open-source record on PutnamBench with 86 problems solved at pass@184.

08 Oct 2025


Researchers from Amazon, the University of Virginia, and Georgia Institute of Technology developed WEBAGENT-R1, an end-to-end multi-turn reinforcement learning framework for training large language model (LLM) based web agents. The framework significantly boosted Llama-3.1-8B's task success rate from 20.6% (Behavior Cloning) to 44.8% on the WebArena-Lite benchmark, surpassing strong proprietary models like OpenAI o3 (39.4%).

05 Nov 2025
Retrieval-augmented generation (RAG) systems empower large language models (LLMs) to access external knowledge during inference. Recent advances have enabled LLMs to act as search agents via reinforcement learning (RL), improving information acquisition through multi-turn interactions with retrieval engines. However, existing approaches either optimize retrieval using search-only metrics (e.g., NDCG) that ignore downstream utility or fine-tune the entire LLM to jointly reason and retrieve-entangling retrieval with generation and limiting the real search utility and compatibility with frozen or proprietary models. In this work, we propose s3, a lightweight, model-agnostic framework that decouples the searcher from the generator and trains the searcher using a Gain Beyond RAG reward: the improvement in generation accuracy over naive RAG. s3 requires only 2.4k training samples to outperform baselines trained on over 70x more data, consistently delivering stronger downstream performance across six general QA and five medical QA benchmarks.

06 Oct 2025

This survey provides a comprehensive review of instruction tuning for Large Language Models, detailing methodologies, datasets, models, and applications. It highlights how instruction tuning aligns LLMs with human instructions and demonstrates its continued necessity as a foundational step in modern alignment pipelines, while also addressing challenges like superficial alignment.

27 Oct 2025

Researchers from Penn State, in collaboration with industry partners, provide the first comprehensive survey of Reinforcement Learning-based agentic search, systematically organizing its foundational concepts, functional roles, optimization strategies, and applications. This work clarifies the interplay between RL and agentic LLMs, delineating current capabilities, evaluation methods, and critical future research directions.

30 May 2025
M+ extends the MemoryLLM architecture, enabling Large Language Models to retain and recall information over sequence lengths exceeding 160,000 tokens, a substantial improvement over MemoryLLM's previous 20,000 token limit. This is achieved through a scalable long-term memory mechanism and a co-trained retriever that efficiently retrieves relevant hidden states, while maintaining competitive GPU memory usage.

25 Sep 2025


Research from Amazon and academic partners demonstrates that domain-specific Supervised Fine-Tuning (SFT) in Large Language Models does not inherently degrade general capabilities, but rather its impact is strongly influenced by the learning rate. The study introduces Token-Adaptive Loss Reweighting (TALR) as a method to maintain a superior balance between domain-specific performance and general capability preservation.
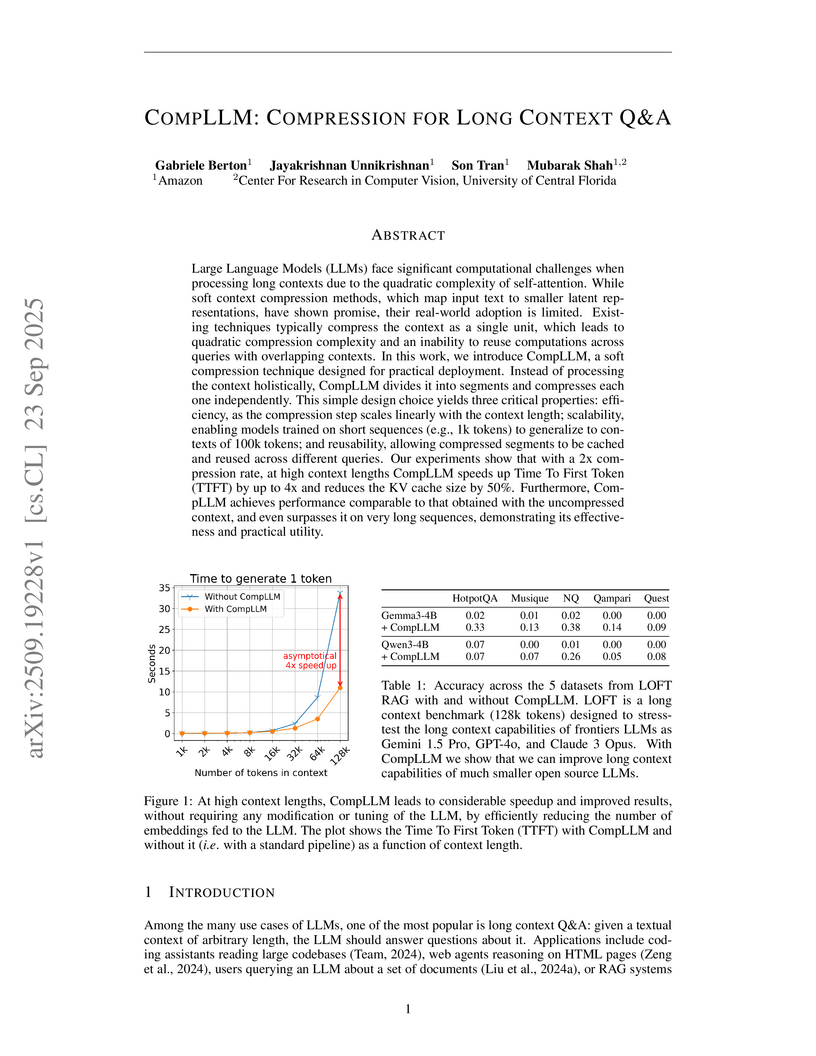
23 Sep 2025
A soft context compression method for Large Language Models, CompLLM, developed by Amazon and UCF, uses a segment-based approach to significantly improve efficiency and scalability for long-context Question & Answer tasks. It achieves up to a 4x speedup in Time To First Token and a 50% reduction in KV cache size, while also enhancing accuracy on contexts exceeding 50,000 tokens.

07 Aug 2025


The paper introduces the Agentic Benchmark Checklist (ABC), a systematic framework for designing and assessing rigorous evaluations for AI agents, addressing pervasive flaws in existing benchmarks that can lead to up to 100% relative misestimation of agent capabilities. It identifies key threats to evaluation rigor and demonstrates how applying the ABC empirically validates flaws and guides the creation of more accurate benchmarks.

02 Sep 2025


Reasoning-enhanced large language models (RLLMs), whether explicitly trained for reasoning or prompted via chain-of-thought (CoT), have achieved state-of-the-art performance on many complex reasoning tasks. However, we uncover a surprising and previously overlooked phenomenon: explicit CoT reasoning can significantly degrade instruction-following accuracy. Evaluating 15 models on two benchmarks: IFEval (with simple, rule-verifiable constraints) and ComplexBench (with complex, compositional constraints), we consistently observe performance drops when CoT prompting is applied. Through large-scale case studies and an attention-based analysis, we identify common patterns where reasoning either helps (e.g., with formatting or lexical precision) or hurts (e.g., by neglecting simple constraints or introducing unnecessary content). We propose a metric, constraint attention, to quantify model focus during generation and show that CoT reasoning often diverts attention away from instruction-relevant tokens. To mitigate these effects, we introduce and evaluate four strategies: in-context learning, self-reflection, self-selective reasoning, and classifier-selective reasoning. Our results demonstrate that selective reasoning strategies, particularly classifier-selective reasoning, can substantially recover lost performance. To our knowledge, this is the first work to systematically expose reasoning-induced failures in instruction-following and offer practical mitigation strategies.

05 May 2022
PatchCore introduces a method for cold-start industrial anomaly detection that leverages locally aware patch features and a coreset-reduced memory bank, achieving state-of-the-art image-level AUROC of 99.6% and efficient pixel-wise anomaly localization on the MVTec AD benchmark.

03 Jul 2025
University of Illinois at Urbana-Champaign UCLATsinghua UniversityThe Chinese University of Hong KongThe Hong Kong University of Science and Technology (Guangzhou)University of California, San Diego
UCLATsinghua UniversityThe Chinese University of Hong KongThe Hong Kong University of Science and Technology (Guangzhou)University of California, San Diego Peking UniversityUniversity of Illinois ChicagoAmazonZhejiang University of TechnologySalesforce AI ResearchHKUST
Peking UniversityUniversity of Illinois ChicagoAmazonZhejiang University of TechnologySalesforce AI ResearchHKUSTA new paradigm, Agentic Deep Research, is proposed where Large Language Models act as autonomous agents, performing iterative reasoning and strategic search to address complex information needs. This approach empirically outperforms traditional web search and basic RAG systems on challenging benchmarks, demonstrating its ability to significantly reduce user cognitive load for deep information tasks.
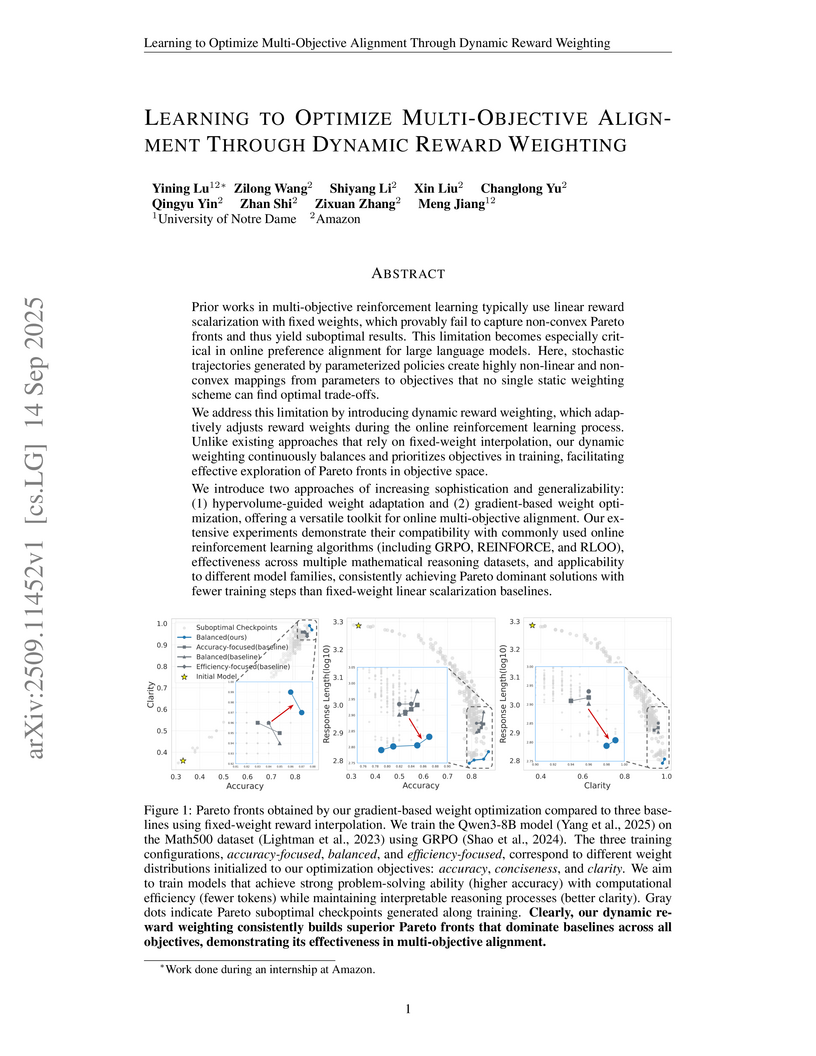
14 Sep 2025

Prior works in multi-objective reinforcement learning typically use linear reward scalarization with fixed weights, which provably fail to capture non-convex Pareto fronts and thus yield suboptimal results. This limitation becomes especially critical in online preference alignment for large language models. Here, stochastic trajectories generated by parameterized policies create highly non-linear and non-convex mappings from parameters to objectives that no single static weighting scheme can find optimal trade-offs. We address this limitation by introducing dynamic reward weighting, which adaptively adjusts reward weights during the online reinforcement learning process. Unlike existing approaches that rely on fixed-weight interpolation, our dynamic weighting continuously balances and prioritizes objectives in training, facilitating effective exploration of Pareto fronts in objective space. We introduce two approaches of increasing sophistication and generalizability: (1) hypervolume-guided weight adaptation and (2) gradient-based weight optimization, offering a versatile toolkit for online multi-objective alignment. Our extensive experiments demonstrate their compatibility with commonly used online reinforcement learning algorithms (including GRPO, REINFORCE, and RLOO), effectiveness across multiple mathematical reasoning datasets, and applicability to different model families, consistently achieving Pareto dominant solutions with fewer training steps than fixed-weight linear scalarization baselines.

02 Oct 2025

OpenTSLM introduces time-series language models that enable large language models (LLMs) to natively integrate and reason over multivariate medical text- and time-series data. The models significantly outperform existing baselines on tasks like ECG question answering and sleep staging, while generating interpretable Chain-of-Thought rationales validated by medical experts.
There are no more papers matching your filters at the moment.
