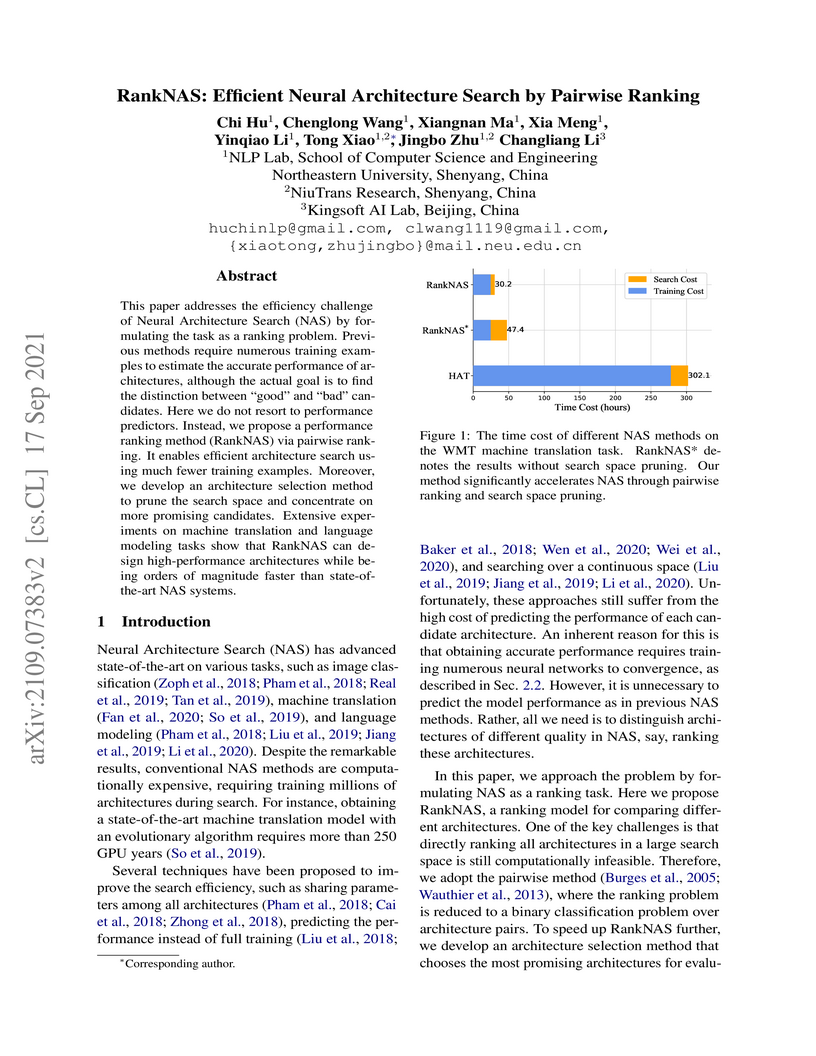
17 Sep 2021


This paper addresses the efficiency challenge of Neural Architecture Search
(NAS) by formulating the task as a ranking problem. Previous methods require
numerous training examples to estimate the accurate performance of
architectures, although the actual goal is to find the distinction between
"good" and "bad" candidates. Here we do not resort to performance predictors.
Instead, we propose a performance ranking method (RankNAS) via pairwise
ranking. It enables efficient architecture search using much fewer training
examples. Moreover, we develop an architecture selection method to prune the
search space and concentrate on more promising candidates. Extensive
experiments on machine translation and language modeling tasks show that
RankNAS can design high-performance architectures while being orders of
magnitude faster than state-of-the-art NAS systems.

17 May 2020
In encoder-decoder neural models, multiple encoders are in general used to
represent the contextual information in addition to the individual sentence. In
this paper, we investigate multi-encoder approaches in documentlevel neural
machine translation (NMT). Surprisingly, we find that the context encoder does
not only encode the surrounding sentences but also behaves as a noise
generator. This makes us rethink the real benefits of multi-encoder in
context-aware translation - some of the improvements come from robust training.
We compare several methods that introduce noise and/or well-tuned dropout setup
into the training of these encoders. Experimental results show that noisy
training plays an important role in multi-encoder-based NMT, especially when
the training data is small. Also, we establish a new state-of-the-art on IWSLT
Fr-En task by careful use of noise generation and dropout methods.

26 Aug 2021
Learning deeper models is usually a simple and effective approach to improve
model performance, but deeper models have larger model parameters and are more
difficult to train. To get a deeper model, simply stacking more layers of the
model seems to work well, but previous works have claimed that it cannot
benefit the model. We propose to train a deeper model with recurrent mechanism,
which loops the encoder and decoder blocks of Transformer in the depth
direction. To address the increasing of model parameters, we choose to share
parameters in different recursive moments. We conduct our experiments on WMT16
English-to-German and WMT14 English-to-France translation tasks, our model
outperforms the shallow Transformer-Base/Big baseline by 0.35, 1.45 BLEU
points, which is 27.23% of Transformer-Big model parameters. Compared to the
deep Transformer(20-layer encoder, 6-layer decoder), our model has similar
model performance and infer speed, but our model parameters are 54.72% of the
former.

05 Jun 2020
Neural architecture search (NAS) has advanced significantly in recent years
but most NAS systems restrict search to learning architectures of a recurrent
or convolutional cell. In this paper, we extend the search space of NAS. In
particular, we present a general approach to learn both intra-cell and
inter-cell architectures (call it ESS). For a better search result, we design a
joint learning method to perform intra-cell and inter-cell NAS simultaneously.
We implement our model in a differentiable architecture search system. For
recurrent neural language modeling, it outperforms a strong baseline
significantly on the PTB and WikiText data, with a new state-of-the-art on PTB.
Moreover, the learned architectures show good transferability to other systems.
E.g., they improve state-of-the-art systems on the CoNLL and WNUT named entity
recognition (NER) tasks and CoNLL chunking task, indicating a promising line of
research on large-scale pre-learned architectures.

03 Nov 2020

Traditional neural machine translation is limited to the topmost encoder
layer's context representation and cannot directly perceive the lower encoder
layers. Existing solutions usually rely on the adjustment of network
architecture, making the calculation more complicated or introducing additional
structural restrictions. In this work, we propose layer-wise multi-view
learning to solve this problem, circumventing the necessity to change the model
structure. We regard each encoder layer's off-the-shelf output, a by-product in
layer-by-layer encoding, as the redundant view for the input sentence. In this
way, in addition to the topmost encoder layer (referred to as the primary
view), we also incorporate an intermediate encoder layer as the auxiliary view.
We feed the two views to a partially shared decoder to maintain independent
prediction. Consistency regularization based on KL divergence is used to
encourage the two views to learn from each other. Extensive experimental
results on five translation tasks show that our approach yields stable
improvements over multiple strong baselines. As another bonus, our method is
agnostic to network architectures and can maintain the same inference speed as
the original model.

19 Jul 2021
Although attention-based Neural Machine Translation has achieved remarkable progress in recent layers, it still suffers from issue of making insufficient use of the output of each layer. In transformer, it only uses the top layer of encoder and decoder in the subsequent process, which makes it impossible to take advantage of the useful information in other layers. To address this issue, we propose a residual tree aggregation of layers for Transformer(RTAL), which helps to fuse information across layers. Specifically, we try to fuse the information across layers by constructing a post-order binary tree. In additional to the last node, we add the residual connection to the process of generating child nodes. Our model is based on the Neural Machine Translation model Transformer and we conduct our experiments on WMT14 English-to-German and WMT17 English-to-France translation tasks. Experimental results across language pairs show that the proposed approach outperforms the strong baseline model significantly
There are no more papers matching your filters at the moment.
