
01 Dec 2025


Researchers from Harbin Institute of Technology, Pengcheng Laboratory, and others developed MCAT, a framework that scales multimodal large language models for many-to-many speech-to-text translation across 70 languages. It achieves state-of-the-art performance on the FLEURS dataset, outperforming SeamlessM4T-V2-Large by over 8 COMET points, while accelerating inference speed by 3.3x through a 25x compression of speech input tokens.

02 Dec 2025

The globalization of education and rapid growth of online learning have made localizing educational content a critical challenge. Lecture materials are inherently multimodal, combining spoken audio with visual slides, which requires systems capable of processing multiple input modalities. To provide an accessible and complete learning experience, translations must preserve all modalities: text for reading, slides for visual understanding, and speech for auditory learning. We present \textbf{BOOM}, a multimodal multilingual lecture companion that jointly translates lecture audio and slides to produce synchronized outputs across three modalities: translated text, localized slides with preserved visual elements, and synthesized speech. This end-to-end approach enables students to access lectures in their native language while aiming to preserve the original content in its entirety. Our experiments demonstrate that slide-aware transcripts also yield cascading benefits for downstream tasks such as summarization and question answering. We release our Slide Translation code at this https URL and integrate it in Lecture Translator at this https URL}\footnote{All released code and models are licensed under the MIT License.

02 Dec 2025
The advent of strong generative AI has a considerable impact on various software engineering tasks such as code repair, test generation, or language translation. While tools like GitHub Copilot are already in widespread use in interactive settings, automated approaches require a higher level of reliability before being usable in industrial practice. In this paper, we focus on three aspects that directly influence the quality of the results: a) the effect of automated feedback loops, b) the choice of Large Language Model (LLM), and c) the influence of behavior-preserving code changes.
We study the effect of these three variables on an automated C-to-Rust translation system. Code translation from C to Rust is an attractive use case in industry due to Rust's safety guarantees. The translation system is based on a generate-and-check pattern, in which Rust code generated by the LLM is automatically checked for compilability and behavioral equivalence with the original C code. For negative checking results, the LLM is re-prompted in a feedback loop to repair its output. These checks also allow us to evaluate and compare the respective success rates of the translation system when varying the three variables.
Our results show that without feedback loops LLM selection has a large effect on translation success. However, when the translation system uses feedback loops the differences across models diminish. We observe this for the average performance of the system as well as its robustness under code perturbations. Finally, we also identify that diversity provided by code perturbations can even result in improved system performance.

28 Nov 2025
There has been significant progress in open-source text-only translation large language models (LLMs) with better language coverage and quality. However, these models can be only used in cascaded pipelines for speech translation (ST), performing automatic speech recognition first followed by translation. This introduces additional latency, which is particularly critical in simultaneous ST (SimulST), and prevents the model from exploiting multimodal context, such as images, which can aid disambiguation. Pretrained multimodal foundation models (MMFMs) already possess strong perception and reasoning capabilities across multiple modalities, but generally lack the multilingual coverage and specialized translation performance of dedicated translation LLMs. To build an effective multimodal translation system, we propose an end-to-end approach that fuses MMFMs with translation LLMs. We introduce a novel fusion strategy that connects hidden states from multiple layers of a pretrained MMFM to a translation LLM, enabling joint end-to-end training. The resulting model, OmniFusion, built on Omni 2.5-7B as the MMFM and SeedX PPO-7B as the translation LLM, can perform speech-to-text, speech-and-image-to-text, and text-and-image-to-text translation. Experiments demonstrate that OmniFusion effectively leverages both audio and visual inputs, achieves a 1-second latency reduction in SimulST compared to cascaded pipelines and also improves the overall translation quality\footnote{Code is available at this https URL}.

30 Nov 2025
We present a culturally-grounded multimodal dataset of 1,060 traditional recipes crowdsourced from rural communities across remote regions of Eastern India, spanning 10 endangered languages. These recipes, rich in linguistic and cultural nuance, were collected using a mobile interface designed for contributors with low digital literacy. Endangered Language Recipes (ELR)-1000 -- captures not only culinary practices but also the socio-cultural context embedded in indigenous food traditions. We evaluate the performance of several state-of-the-art large language models (LLMs) on translating these recipes into English and find the following: despite the models' capabilities, they struggle with low-resource, culturally-specific language. However, we observe that providing targeted context -- including background information about the languages, translation examples, and guidelines for cultural preservation -- leads to significant improvements in translation quality. Our results underscore the need for benchmarks that cater to underrepresented languages and domains to advance equitable and culturally-aware language technologies. As part of this work, we release the ELR-1000 dataset to the NLP community, hoping it motivates the development of language technologies for endangered languages.
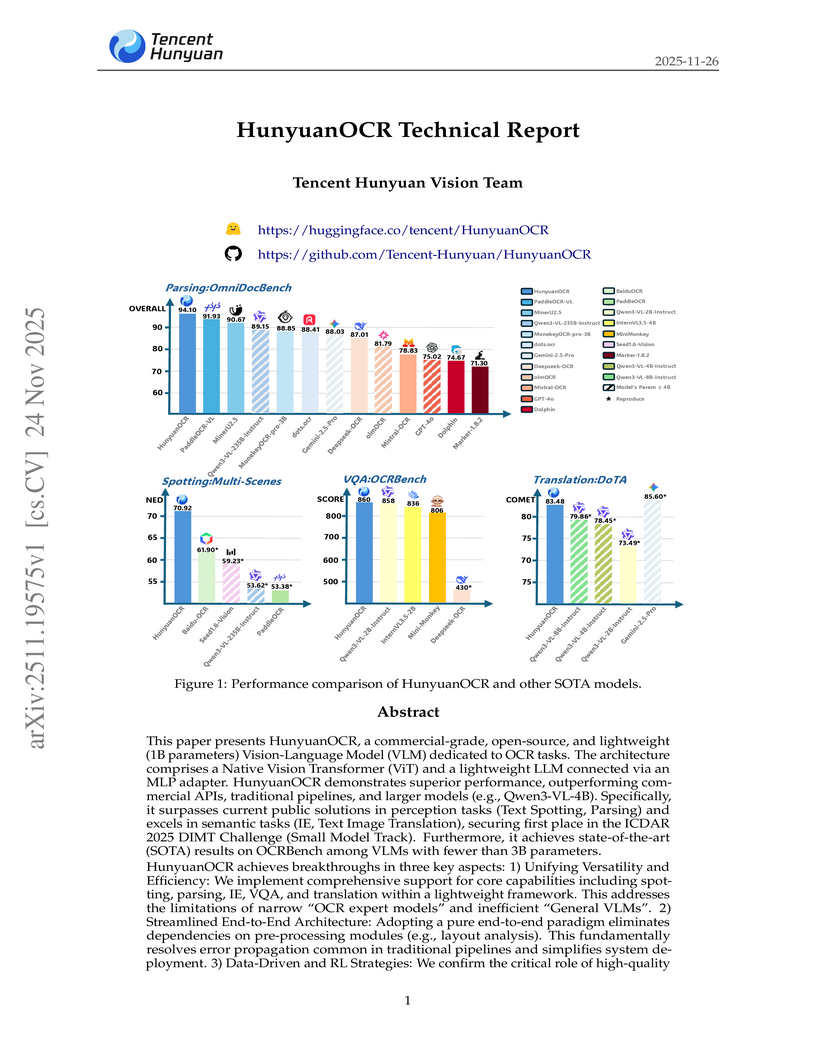
24 Nov 2025
Tencent's HunyuanOCR introduces a 1-billion-parameter Vision-Language Model for end-to-end Optical Character Recognition, unifying tasks like text spotting, document parsing, and information extraction. It achieves commercial-grade performance, outperforming larger general VLMs and traditional pipeline methods, and pioneers the application of Reinforcement Learning for OCR optimization.

28 Nov 2025
Bangladesh's low-income population faces major barriers to affordable legal advice due to complex legal language, procedural opacity, and high costs. Existing AI legal assistants lack Bengali-language support and jurisdiction-specific adaptation, limiting their effectiveness. To address this, we developed Mina, a multilingual LLM-based legal assistant tailored for the Bangladeshi context. It employs multilingual embeddings and a RAG-based chain-of-tools framework for retrieval, reasoning, translation, and document generation, delivering context-aware legal drafts, citations, and plain-language explanations via an interactive chat interface. Evaluated by law faculty from leading Bangladeshi universities across all stages of the 2022 and 2023 Bangladesh Bar Council Exams, Mina scored 75-80% in Preliminary MCQs, Written, and simulated Viva Voce exams, matching or surpassing average human performance and demonstrating clarity, contextual understanding, and sound legal reasoning. Even under a conservative upper bound, Mina operates at just 0.12-0.61% of typical legal consultation costs in Bangladesh, yielding a 99.4-99.9\% cost reduction relative to human-provided services. These results confirm its potential as a low-cost, multilingual AI assistant that automates key legal tasks and scales access to justice, offering a real-world case study on building domain-specific, low-resource systems and addressing challenges of multilingual adaptation, efficiency, and sustainable public-service AI deployment.

31 Oct 2025
Kang et al. identified that failures in the language understanding stage are the primary cause of multilingual reasoning disparities in Reasoning Language Models (RLMs). The work introduces a selective translation strategy that leverages automatically detected understanding failures to efficiently bridge this performance gap across diverse languages.

26 Oct 2025
The Efficient Encoder-Decoder Diffusion (E2D2) framework introduces an encoder-decoder architecture for discrete diffusion language models, significantly improving training and inference efficiency. This method achieves up to a 75% higher throughput for summarization and nearly 3 times faster inference for machine translation compared to decoder-only diffusion models, while maintaining or improving generation quality.

26 Oct 2025
This paper presents a real-time modular defense system named Sentra-Guard. The system detects and mitigates jailbreak and prompt injection attacks targeting large language models (LLMs). The framework uses a hybrid architecture with FAISS-indexed SBERT embedding representations that capture the semantic meaning of prompts, combined with fine-tuned transformer classifiers, which are machine learning models specialized for distinguishing between benign and adversarial language inputs. It identifies adversarial prompts in both direct and obfuscated attack vectors. A core innovation is the classifier-retriever fusion module, which dynamically computes context-aware risk scores that estimate how likely a prompt is to be adversarial based on its content and context. The framework ensures multilingual resilience with a language-agnostic preprocessing layer. This component automatically translates non-English prompts into English for semantic evaluation, enabling consistent detection across over 100 languages. The system includes a HITL feedback loop, where decisions made by the automated system are reviewed by human experts for continual learning and rapid adaptation under adversarial pressure. Sentra-Guard maintains an evolving dual-labeled knowledge base of benign and malicious prompts, enhancing detection reliability and reducing false positives. Evaluation results show a 99.96% detection rate (AUC = 1.00, F1 = 1.00) and an attack success rate (ASR) of only 0.004%. This outperforms leading baselines such as LlamaGuard-2 (1.3%) and OpenAI Moderation (3.7%). Unlike black-box approaches, Sentra-Guard is transparent, fine-tunable, and compatible with diverse LLM backends. Its modular design supports scalable deployment in both commercial and open-source environments. The system establishes a new state-of-the-art in adversarial LLM defense.

29 Sep 2025
Researchers from George Mason University and Zoom Communications introduced Pivot-Based Reinforcement Learning with Semantically Verifiable Rewards (PB-RLSVR), a framework to enhance multilingual reasoning in Large Language Models. This method utilizes a high-performing English LLM as a pivot to generate semantic rewards, leading to a substantial reduction in the reasoning performance gap between English and other languages, with an average improvement of 8.4 points for Llama-3.1-8B-Instruct and 7.4 points for Qwen3-32B.

25 Sep 2025

We present our journey in training a speech language model for Wolof, an underrepresented language spoken in West Africa, and share key insights. We first emphasize the importance of collecting large-scale, spontaneous, high-quality unsupervised speech data, and show that continued pretraining HuBERT on this dataset outperforms both the base model and African-centric models on ASR. We then integrate this speech encoder into a Wolof LLM to train the first Speech LLM for this language, extending its capabilities to tasks such as speech translation. Furthermore, we explore training the Speech LLM to perform multi-step Chain-of-Thought before transcribing or translating. Our results show that the Speech LLM not only improves speech recognition but also performs well in speech translation. The models and the code will be openly shared.

17 Sep 2025
Achieving human-level translations requires leveraging context to ensure coherence and handle complex phenomena like pronoun disambiguation. Sparsity of contextually rich examples in the standard training data has been hypothesized as the reason for the difficulty of context utilization. In this work, we systematically validate this claim in both single- and multilingual settings by constructing training datasets with a controlled proportions of contextually relevant examples. We demonstrate a strong association between training data sparsity and model performance confirming sparsity as a key bottleneck. Importantly, we reveal that improvements in one contextual phenomenon do no generalize to others. While we observe some cross-lingual transfer, it is not significantly higher between languages within the same sub-family. Finally, we propose and empirically evaluate two training strategies designed to leverage the available data. These strategies improve context utilization, resulting in accuracy gains of up to 6 and 8 percentage points on the ctxPro evaluation in single- and multilingual settings respectively.

20 Aug 2025


DuPO introduces a self-supervised dual preference optimization framework that enables reliable LLM self-verification without external annotations by utilizing a generalized duality principle based on complementary tasks. The method achieves substantial performance gains in multilingual translation and mathematical reasoning, bringing smaller models to state-of-the-art levels and significantly improving inference-time reranking.

06 Aug 2025
Large language model (LLM) training faces a critical bottleneck: the scarcity of high-quality, reasoning-intensive question-answer pairs, especially from sparse, domain-specific sources like PubMed papers or legal documents. Existing methods rely on surface patterns, fundamentally failing to generate controllable, complex multi-hop reasoning questions that test genuine understanding-essential for advancing LLM training paradigms. We present \textbf{Semantic Bridge}, the first universal framework for controllably generating sophisticated multi-hop reasoning questions from arbitrary sources. Our breakthrough innovation is \textit{semantic graph weaving}-three complementary bridging mechanisms (entity bridging for role-varying shared entities, predicate chain bridging for temporal/causal/logical sequences, and causal bridging for explicit reasoning chains)-that systematically construct complex pathways across documents, with fine-grained control over complexity and types via AMR-driven analysis. Our multi-modal AMR pipeline achieves up to 9.5% better round-trip quality, enabling production-ready controllable QA generation. Extensive evaluation demonstrates performance across both general-purpose datasets (Wikipedia) and specialized domains (biomedicine) It yields consistent 18.3%-25.4% gains over baselines across four languages (English, Chinese, French, German). Question pairs generated from 200 sources outperform 600 native human annotation examples with 67% fewer materials. Human evaluation shows 23.4% higher complexity, 18.7% better answerability, and 31.2% improved pattern coverage. Semantic Bridge establishes a new paradigm for LLM training data synthesis, enabling controllable generation of targeted reasoning questions from sparse sources. We will release our core code and semantic bridge model.

07 Aug 2025
We introduce **EvoGraph**, a framework that enables software systems to evolve their own source code, build pipelines, documentation, and tickets. EvoGraph represents every artefact in a typed directed graph, applies learned mutation operators driven by specialized small language models (SLMs), and selects survivors with a multi-objective fitness. On three benchmarks, EvoGraph fixes 83% of known security vulnerabilities, translates COBOL to Java with 93% functional equivalence (test verified), and maintains documentation freshness within two minutes. Experiments show a 40% latency reduction and a sevenfold drop in feature lead time compared with strong baselines. We extend our approach to **evoGraph**, leveraging language-specific SLMs for modernizing .NET, Lisp, CGI, ColdFusion, legacy Python, and C codebases, achieving 82-96% semantic equivalence across languages while reducing computational costs by 90% compared to large language models. EvoGraph's design responds to empirical failure modes in legacy modernization, such as implicit contracts, performance preservation, and integration evolution. Our results suggest a practical path toward Software 3.0, where systems adapt continuously yet remain under measurable control.

05 Aug 2025

Despite the impressive performance of LLMs on English-based tasks, little is known about their capabilities in specific languages such as Filipino. In this work, we address this gap by introducing FilBench, a Filipino-centric benchmark designed to evaluate LLMs across a diverse set of tasks and capabilities in Filipino, Tagalog, and Cebuano. We carefully curate the tasks in FilBench to reflect the priorities and trends of NLP research in the Philippines such as Cultural Knowledge, Classical NLP, Reading Comprehension, and Generation. By evaluating 27 state-of-the-art LLMs on FilBench, we find that several LLMs suffer from reading comprehension and translation capabilities. Our results indicate that FilBench is challenging, with the best model, GPT-4o, achieving only a score of 72.23%. Moreover, we also find that models trained specifically for Southeast Asian languages tend to underperform on FilBench, with the highest-performing model, SEA-LION v3 70B, achieving only a score of 61.07%. Our work demonstrates the value of curating language-specific LLM benchmarks to aid in driving progress on Filipino NLP and increasing the inclusion of Philippine languages in LLM development.
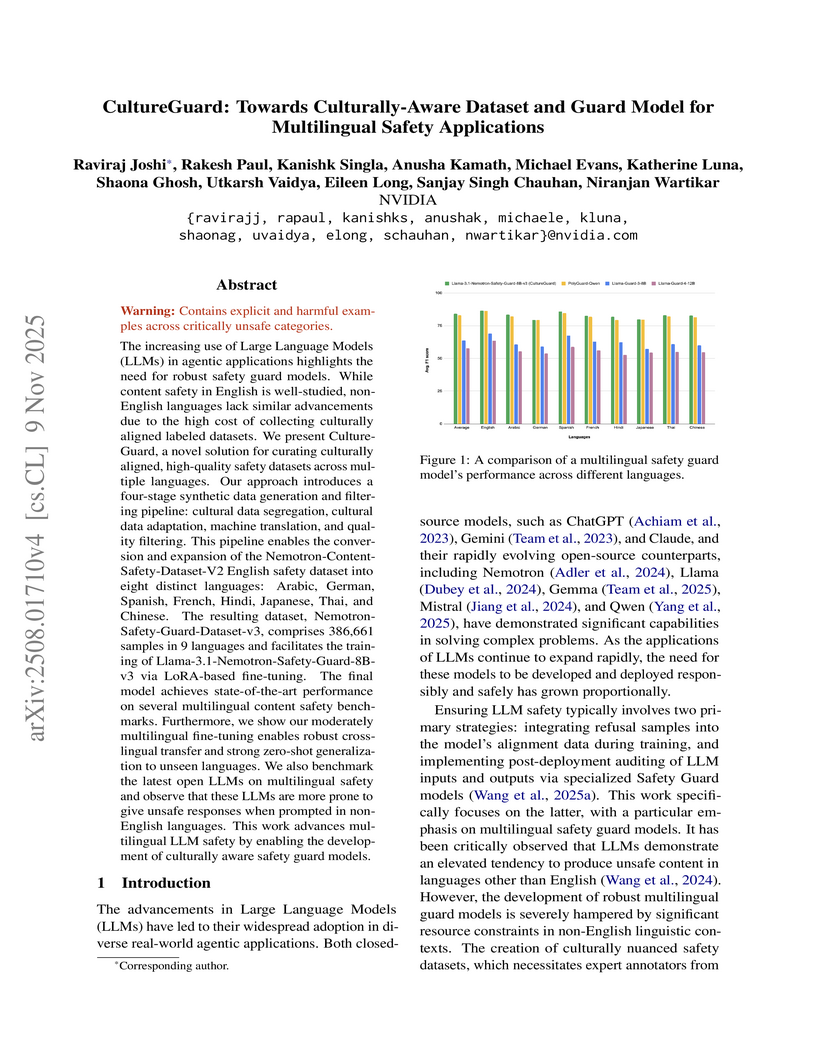
09 Nov 2025

The increasing use of Large Language Models (LLMs) in agentic applications highlights the need for robust safety guard models. While content safety in English is well-studied, non-English languages lack similar advancements due to the high cost of collecting culturally aligned labeled datasets. We present CultureGuard, a novel solution for curating culturally aligned, high-quality safety datasets across multiple languages. Our approach introduces a four-stage synthetic data generation and filtering pipeline: cultural data segregation, cultural data adaptation, machine translation, and quality filtering. This pipeline enables the conversion and expansion of the Nemotron-Content-Safety-Dataset-V2 English safety dataset into eight distinct languages: Arabic, German, Spanish, French, Hindi, Japanese, Thai, and Chinese. The resulting dataset, Nemotron-Safety-Guard-Dataset-v3, comprises 386,661 samples in 9 languages and facilitates the training of Llama-3.1-Nemotron-Safety-Guard-8B-v3 via LoRA-based fine-tuning. The final model achieves state-of-the-art performance on several multilingual content safety benchmarks. Furthermore, we show our moderately multilingual fine-tuning enables robust cross-lingual transfer and strong zero-shot generalization to unseen languages. We also benchmark the latest open LLMs on multilingual safety and observe that these LLMs are more prone to give unsafe responses when prompted in non-English languages. This work advances multilingual LLM safety by enabling the development of culturally aware safety guard models.

25 Jul 2025
Rationale and Objectives: To develop and validate PARROT (Polyglottal Annotated Radiology Reports for Open Testing), a large, multicentric, open-access dataset of fictional radiology reports spanning multiple languages for testing natural language processing applications in radiology. Materials and Methods: From May to September 2024, radiologists were invited to contribute fictional radiology reports following their standard reporting practices. Contributors provided at least 20 reports with associated metadata including anatomical region, imaging modality, clinical context, and for non-English reports, English translations. All reports were assigned ICD-10 codes. A human vs. AI report differentiation study was conducted with 154 participants (radiologists, healthcare professionals, and non-healthcare professionals) assessing whether reports were human-authored or AI-generated. Results: The dataset comprises 2,658 radiology reports from 76 authors across 21 countries and 13 languages. Reports cover multiple imaging modalities (CT: 36.1%, MRI: 22.8%, radiography: 19.0%, ultrasound: 16.8%) and anatomical regions, with chest (19.9%), abdomen (18.6%), head (17.3%), and pelvis (14.1%) being most prevalent. In the differentiation study, participants achieved 53.9% accuracy (95% CI: 50.7%-57.1%) in distinguishing between human and AI-generated reports, with radiologists performing significantly better (56.9%, 95% CI: 53.3%-60.6%, p<0.05) than other groups. Conclusion: PARROT represents the largest open multilingual radiology report dataset, enabling development and validation of natural language processing applications across linguistic, geographic, and clinical boundaries without privacy constraints.

15 Jul 2025

Researchers from the University of Maryland and Lawrence Livermore National Laboratory introduce IRCoder, a method that integrates graph-based representations of LLVM Intermediate Representation (IR) into large language models (LLMs) for code. This approach enhances LLMs' ability to reason about structured code properties, leading to improved performance on diverse code understanding and generation tasks.
There are no more papers matching your filters at the moment.
