08 Jan 2022
Clustering Text has been an important problem in the domain of Natural
Language Processing. While there are techniques to cluster text based on using
conventional clustering techniques on top of contextual or non-contextual
vector space representations, it still remains a prevalent area of research
possible to various improvements in performance and implementation of these
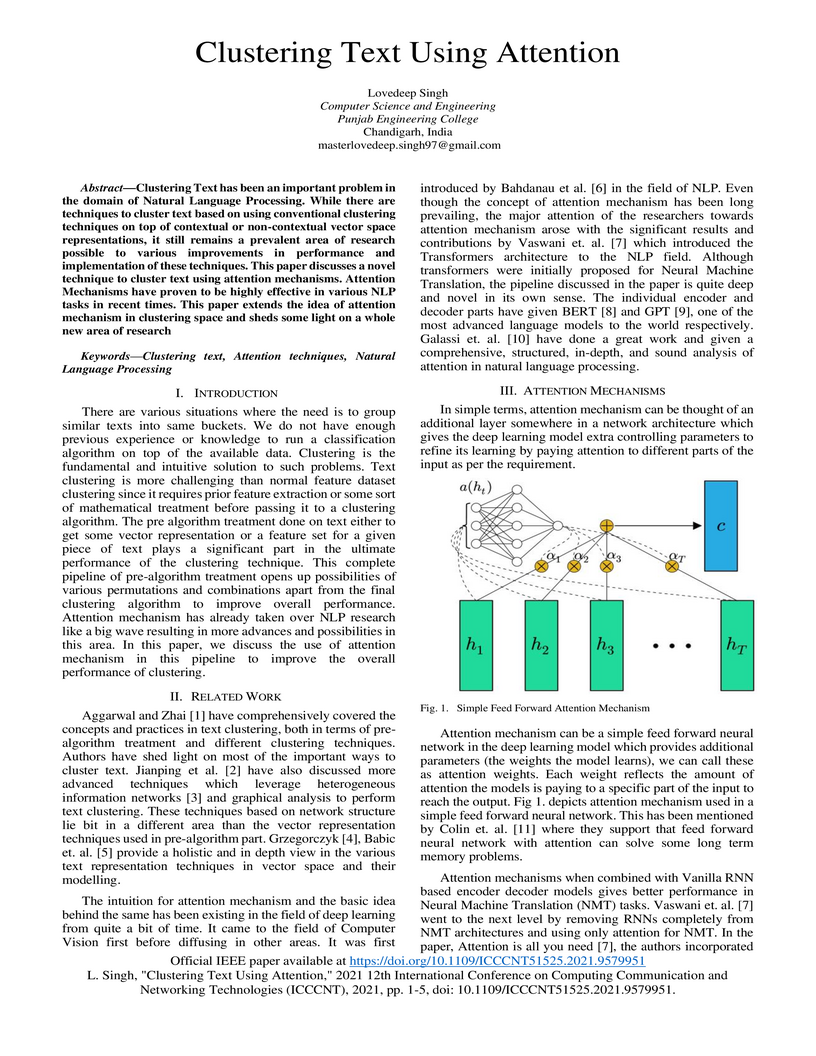
techniques. This paper discusses a novel technique to cluster text using
attention mechanisms. Attention Mechanisms have proven to be highly effective
in various NLP tasks in recent times. This paper extends the idea of attention
mechanism in clustering space and sheds some light on a whole new area of
research

12 Dec 2020

The vulnerability of models to data aberrations and adversarial attacks
influences their ability to demarcate distinct class boundaries efficiently.
The network's confidence and uncertainty play a pivotal role in weight
adjustments and the extent of acknowledging such attacks. In this paper, we
address the trade-off between the accuracy and calibration potential of a
classification network. We study the significance of ground-truth distribution
changes on the performance and generalizability of various state-of-the-art
networks and compare the proposed method's response to unanticipated attacks.
Furthermore, we demonstrate the role of label-smoothing regularization and
normalization in yielding better generalizability and calibrated probability
distribution by proposing normalized soft labels to enhance the calibration of
feature maps. Subsequently, we substantiate our inference by translating
conventional convolutions to padding based partial convolution to establish the
tangible impact of corrections in reinforcing the performance and convergence
rate. We graphically elucidate the implication of such variations with the
critical purpose of corroborating the reliability and reproducibility for
multiple datasets.

22 Feb 2022
Software development comprises the use of multiple Third-Party Libraries
(TPLs). However, the irrelevant libraries present in software application's
distributable often lead to excessive consumption of resources such as CPU
cycles, memory, and modile-devices' battery usage. Therefore, the
identification and removal of unused TPLs present in an application are
desirable. We present a rapid, storage-efficient, obfuscation-resilient method
to detect the irrelevant-TPLs in Java and Python applications. Our approach's
novel aspects are i) Computing a vector representation of a .class file using a
model that we call Lib2Vec. The Lib2Vec model is trained using the Paragraph
Vector Algorithm. ii) Before using it for training the Lib2Vec models, a .class
file is converted to a normalized form via semantics-preserving
transformations. iii) A eXtra Library Detector (XtraLibD) developed and tested
with 27 different language-specific Lib2Vec models. These models were trained
using different parameters and >30,000 .class and >478,000 .py files taken from
>100 different Java libraries and 43,711 Python available at MavenCentral.com
and Pypi.com, respectively. XtraLibD achieves an accuracy of 99.48% with an F1
score of 0.968 and outperforms the existing tools, viz., LibScout, LiteRadar,
and LibD with an accuracy improvement of 74.5%, 30.33%, and 14.1%,
respectively. Compared with LibD, XtraLibD achieves a response time improvement
of 61.37% and a storage reduction of 87.93% (99.85% over JIngredient). Our
program artifacts are available at this https URL

13 Jun 2022
Fake News Detection has been a challenging problem in the field of Machine Learning. Researchers have approached it via several techniques using old Statistical Classification models and modern Deep Learning. Today, with the growing amount of data, developments in the field of NLP and ML, and an increase in the computation power at disposal, there are infinite permutations and combinations to approach this problem from a different perspective. In this paper, we try different methods to tackle Fake News, and try to build, and propose the possibilities of a Hybrid Ensemble combining the classical Machine Learning techniques with the modern Deep Learning Approaches
There are no more papers matching your filters at the moment.
