
08 Dec 2025

DeepCode presents a multi-stage agentic framework for autonomously generating executable code repositories from scientific papers, achieving a 73.5% replication score on the PaperBench Code-Dev benchmark and exceeding PhD-level human expert performance.

05 Dec 2025
An agentic file-system abstraction unifies heterogeneous context sources for Generative AI, enabling a systematic and verifiable context engineering pipeline that addresses architectural constraints like limited token windows and statelessness. This approach, implemented in the AIGNE framework, fosters robust, traceable, and human-aligned GenAI systems.

09 Dec 2025
Researchers at RheinMain University of Applied Sciences introduce multicalibration to LLM-based code generation, demonstrating that incorporating code-related contextual information significantly enhances the reliability of confidence scores. The approach achieves up to a 58.4% improvement in binary classification accuracy for code correctness over uncalibrated methods and consistently outperforms traditional calibration baselines.

09 Dec 2025
Large language models (LLMs) have shown exceptional performance in code generation and understanding tasks, yet their high computational costs hinder broader adoption. One important factor is the inherent verbosity of programming languages, such as unnecessary formatting elements and lengthy boilerplate code. This leads to inflated token counts in both input and generated outputs, which increases inference costs and slows down the generation process. Prior work improves this through simplifying programming language grammar, reducing token usage across both code understanding and generation tasks. However, it is confined to syntactic transformations, leaving significant opportunities for token reduction unrealized at the semantic level.
In this work, we propose Token Sugar, a concept that replaces frequent and verbose code patterns with reversible, token-efficient shorthand in the source code. To realize this concept in practice, we designed a systematic solution that mines high-frequency, token-heavy patterns from a code corpus, maps each to a unique shorthand, and integrates them into LLM pretraining via code transformation. With this solution, we obtain 799 (code pattern, shorthand) pairs, which can reduce up to 15.1% token count in the source code and is complementary to existing syntax-focused methods. We further trained three widely used LLMs on Token Sugar-augmented data. Experimental results show that these models not only achieve significant token savings (up to 11.2% reduction) during generation but also maintain near-identical Pass@1 scores compared to baselines trained on unprocessed code.
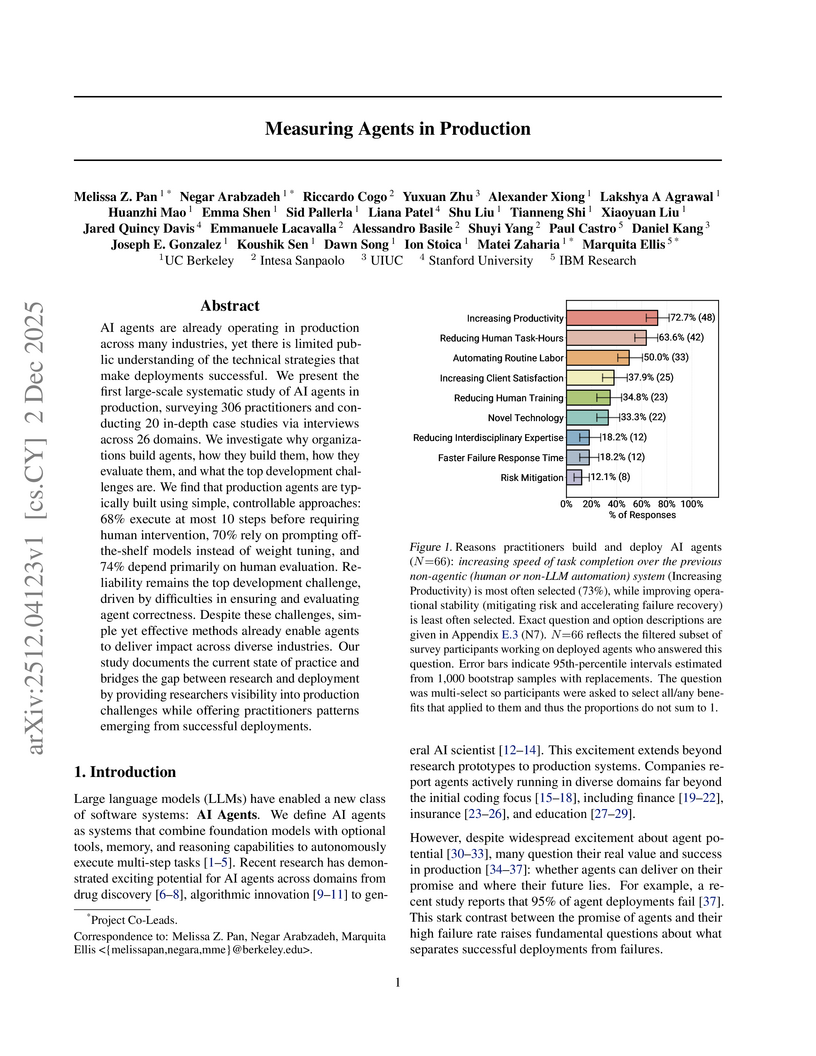
02 Dec 2025
An empirical study surveyed 306 AI agent practitioners and conducted 20 in-depth case studies to analyze the technical strategies, architectural patterns, and challenges of successfully deployed AI agents. The research reveals how real-world production agents prioritize reliability and controlled autonomy to achieve productivity gains across diverse industries.

08 Dec 2025
A study by NYU Abu Dhabi and UC Davis demonstrated that Large Language Models internalize a signal of code correctness, which can be extracted to rank code candidates more effectively than traditional confidence measures. Their Representation Engineering method improved code selection accuracy by up to 29 percentage points and often surpassed execution-feedback based rankers.

09 Dec 2025
DOVER is an auto-debugging framework for LLM multi-agent systems that moves beyond speculative log-based failure attribution to actively verify and repair failures through targeted interventions. The system successfully recovers a substantial percentage of failed tasks, with up to 49.0% trial success on the AutoGen2 framework, and provides mechanisms to quantify progress and validate debugging hypotheses.

08 Dec 2025
We investigate how large language models (LLMs) fail when operating as autonomous agents with tool-use capabilities. Using the Kamiwaza Agentic Merit Index (KAMI) v0.1 benchmark, we analyze 900 execution traces from three representative models - Granite 4 Small, Llama 4 Maverick, and DeepSeek V3.1 - across filesystem, text extraction, CSV analysis, and SQL scenarios. Rather than focusing on aggregate scores, we perform fine-grained, per-trial behavioral analysis to surface the strategies that enable successful multi-step tool execution and the recurrent failure modes that undermine reliability. Our findings show that model scale alone does not predict agentic robustness: Llama 4 Maverick (400B) performs only marginally better than Granite 4 Small (32B) in some uncertainty-driven tasks, while DeepSeek V3.1's superior reliability derives primarily from post-training reinforcement learning rather than architecture or size. Across models, we identify four recurring failure archetypes: premature action without grounding, over-helpfulness that substitutes missing entities, vulnerability to distractor-induced context pollution, and fragile execution under load. These patterns highlight the need for agentic evaluation methods that emphasize interactive grounding, recovery behavior, and environment-aware adaptation, suggesting that reliable enterprise deployment requires not just stronger models but deliberate training and design choices that reinforce verification, constraint discovery, and adherence to source-of-truth data.

08 Dec 2025
Large Language Models (LLMs) have demonstrated remarkable performance in code intelligence tasks such as code generation, summarization, and translation. However, their reliance on linearized token sequences limits their ability to understand the structural semantics of programs. While prior studies have explored graphaugmented prompting and structure-aware pretraining, they either suffer from prompt length constraints or require task-specific architectural changes that are incompatible with large-scale instructionfollowing LLMs. To address these limitations, this paper proposes CGBridge, a novel plug-and-play method that enhances LLMs with Code Graph information through an external, trainable Bridge module. CGBridge first pre-trains a code graph encoder via selfsupervised learning on a large-scale dataset of 270K code graphs to learn structural code semantics. It then trains an external module to bridge the modality gap among code, graph, and text by aligning their semantics through cross-modal attention mechanisms. Finally, the bridge module generates structure-informed prompts, which are injected into a frozen LLM, and is fine-tuned for downstream code intelligence tasks. Experiments show that CGBridge achieves notable improvements over both the original model and the graphaugmented prompting method. Specifically, it yields a 16.19% and 9.12% relative gain in LLM-as-a-Judge on code summarization, and a 9.84% and 38.87% relative gain in Execution Accuracy on code translation. Moreover, CGBridge achieves over 4x faster inference than LoRA-tuned models, demonstrating both effectiveness and efficiency in structure-aware code understanding.

07 Dec 2025
As software systems evolve, developers increasingly work across multiple programming languages and often face the need to migrate code from one language to another. While automatic code translation offers a promising solution, it has long remained a challenging task. Recent advancements in Large Language Models (LLMs) have shown potential for this task, yet existing approaches remain limited in accuracy and fail to effectively leverage contextual and structural cues within the code. Prior work has explored translation and repair mechanisms, but lacks a structured, agentic framework where multiple specialized agents collaboratively improve translation quality. In this work, we introduce BabelCoder, an agentic framework that performs code translation by decomposing the task into specialized agents for translation, testing, and refinement, each responsible for a specific aspect such as generating code, validating correctness, or repairing errors. We evaluate BabelCoder on four benchmark datasets and compare it against four state-of-the-art baselines. BabelCoder outperforms existing methods by 0.5%-13.5% in 94% of cases, achieving an average accuracy of 94.16%.

08 Dec 2025
Automatically synthesizing verifiable code from natural language requirements ensures software correctness and reliability while significantly lowering the barrier to adopting the techniques of formal methods. With the rise of large language models (LLMs), long-standing efforts at autoformalization have gained new momentum. However, existing approaches suffer from severe syntactic and semantic errors due to the scarcity of domain-specific pre-training corpora and often fail to formalize implicit knowledge effectively. In this paper, we propose AutoICE, an LLM-driven evolutionary search for synthesizing verifiable C code. It introduces the diverse individual initialization and the collaborative crossover to enable diverse iterative updates, thereby mitigating error propagation inherent in single-agent iterations. Besides, it employs the self-reflective mutation to facilitate the discovery of implicit knowledge. Evaluation results demonstrate the effectiveness of AutoICE: it successfully verifies \% of code, outperforming the state-of-the-art (SOTA) approach. Besides, on a developer-friendly dataset variant, AutoICE achieves a \% verification success rate, significantly surpassing the \% success rate of the SOTA approach.

08 Dec 2025
As AI agents built on large language models (LLMs) become increasingly embedded in society, issues of coordination, control, delegation, and accountability are entangled with concerns over their reliability. To design and implement LLM agents around reliable operations, we should consider the task complexity in the application settings and reduce their limitations while striving to minimize agent failures and optimize resource efficiency. High-functioning human organizations have faced similar balancing issues, which led to evidence-based theories that seek to understand their functioning strategies. We examine the parallels between LLM agents and the compatible frameworks in organization science, focusing on what the design, scaling, and management of organizations can inform agentic systems towards improving reliability. We offer three preliminary accounts of organizational principles for AI agent engineering to attain reliability and effectiveness, through balancing agency and capabilities in agent design, resource constraints and performance benefits in agent scaling, and internal and external mechanisms in agent management. Our work extends the growing exchanges between the operational and governance principles of AI systems and social systems to facilitate system integration.

09 Dec 2025
The integration of Large Language Models (LLMs) into mobile and software development workflows faces a persistent tension among three demands: semantic awareness, developer productivity, and data privacy. Traditional cloud-based tools offer strong reasoning but risk data exposure and latency, while on-device solutions lack full-context understanding across codebase and developer tooling. We introduce SolidGPT, an open-source, edge-cloud hybrid developer assistant built on GitHub, designed to enhance code and workspace semantic search. SolidGPT enables developers to: talk to your codebase: interactively query code and project structure, discovering the right methods and modules without manual searching. Automate software project workflows: generate PRDs, task breakdowns, Kanban boards, and even scaffold web app beginnings, with deep integration via VSCode and Notion. Configure private, extensible agents: onboard private code folders (up to approximately 500 files), connect Notion, customize AI agent personas via embedding and in-context training, and deploy via Docker, CLI, or VSCode extension. In practice, SolidGPT empowers developer productivity through: Semantic-rich code navigation: no more hunting through files or wondering where a feature lives. Integrated documentation and task management: seamlessly sync generated PRD content and task boards into developer workflows. Privacy-first design: running locally via Docker or VSCode, with full control over code and data, while optionally reaching out to LLM APIs as needed. By combining interactive code querying, automated project scaffolding, and human-AI collaboration, SolidGPT provides a practical, privacy-respecting edge assistant that accelerates real-world development workflows, ideal for intelligent mobile and software engineering contexts.

08 Dec 2025
Time series forecasting has applications across domains and industries, especially in healthcare, but the technical expertise required to analyze data, build models, and interpret results can be a barrier to using these techniques. This article presents a web platform that makes the process of analyzing and plotting data, training forecasting models, and interpreting and viewing results accessible to researchers and clinicians. Users can upload data and generate plots to showcase their variables and the relationships between them. The platform supports multiple forecasting models and training techniques which are highly customizable according to the user's needs. Additionally, recommendations and explanations can be generated from a large language model that can help the user choose appropriate parameters for their data and understand the results for each model. The goal is to integrate this platform into learning health systems for continuous data collection and inference from clinical pipelines.

08 Dec 2025
Configuring computational fluid dynamics (CFD) simulations requires significant expertise in physics modeling and numerical methods, posing a barrier to non-specialists. Although automating scientific tasks with large language models (LLMs) has attracted attention, applying them to the complete, end-to-end CFD workflow remains a challenge due to its stringent domain-specific requirements. We introduce CFD-copilot, a domain-specialized LLM framework designed to facilitate natural language-driven CFD simulation from setup to post-processing. The framework employs a fine-tuned LLM to directly translate user descriptions into executable CFD setups. A multi-agent system integrates the LLM with simulation execution, automatic error correction, and result analysis. For post-processing, the framework utilizes the model context protocol (MCP), an open standard that decouples LLM reasoning from external tool execution. This modular design allows the LLM to interact with numerous specialized post-processing functions through a unified and scalable interface, improving the automation of data extraction and analysis. The framework was evaluated on benchmarks including the NACA~0012 airfoil and the three-element 30P-30N airfoil. The results indicate that domain-specific adaptation and the incorporation of the MCP jointly enhance the reliability and efficiency of LLM-driven engineering workflows.

02 Dec 2025
PaperDebugger: A Plugin-Based Multi-Agent System for In-Editor Academic Writing, Review, and Editing
PaperDebugger: A Plugin-Based Multi-Agent System for In-Editor Academic Writing, Review, and Editing

PaperDebugger, developed by NUS researchers, introduces an in-editor multi-agent system as a Chrome extension for Overleaf, embedding LLM-driven academic writing assistance directly into the LaTeX editing environment. The system offers capabilities like structured critiques, text refinement, and literature lookup via patch-based edits, demonstrating successful technical integration and positive early user adoption.

09 Dec 2025
Agentic AI systems built on large language models (LLMs) offer significant potential for automating complex workflows, from software development to customer support. However, LLM agents often underperform due to suboptimal configurations; poorly tuned prompts, tool descriptions, and parameters that typically require weeks of manual refinement. Existing optimization methods either are too complex for general use or treat components in isolation, missing critical interdependencies.
We present ARTEMIS, a no-code evolutionary optimization platform that jointly optimizes agent configurations through semantically-aware genetic operators. Given only a benchmark script and natural language goals, ARTEMIS automatically discovers configurable components, extracts performance signals from execution logs, and evolves configurations without requiring architectural modifications.
We evaluate ARTEMIS on four representative agent systems: the \emph{ALE Agent} for competitive programming on AtCoder Heuristic Contest, achieving a \textbf{ improvement} in acceptance rate; the \emph{Mini-SWE Agent} for code optimization on SWE-Perf, with a statistically significant \textbf{10.1\% performance gain}; and the \emph{CrewAI Agent} for cost and mathematical reasoning on Math Odyssey, achieving a statistically significant \textbf{ reduction} in the number of tokens required for evaluation. We also evaluate the \emph{MathTales-Teacher Agent} powered by a smaller open-source model (Qwen2.5-7B) on GSM8K primary-level mathematics problems, achieving a \textbf{22\% accuracy improvement} and demonstrating that ARTEMIS can optimize agents based on both commercial and local models.

09 Dec 2025
The rising global prevalence of diabetes necessitates early detection to prevent severe complications. While AI-powered prediction applications offer a promising solution, they require a responsive and scalable back-end architecture to serve a large user base effectively. This paper details the development and evaluation of a scalable back-end system designed for a mobile diabetes prediction application. The primary objective was to maintain a failure rate below 5% and an average latency of under 1000 ms. The architecture leverages horizontal scaling, database sharding, and asynchronous communication via a message queue. Performance evaluation showed that 83% of the system's features (20 out of 24) met the specified performance targets. Key functionalities such as user profile management, activity tracking, and read-intensive prediction operations successfully achieved the desired performance. The system demonstrated the ability to handle up to 10,000 concurrent users without issues, validating its scalability. The implementation of asynchronous communication using RabbitMQ proved crucial in minimizing the error rate for computationally intensive prediction requests, ensuring system reliability by queuing requests and preventing data loss under heavy load.

02 Dec 2025
This research evaluates the security of code generated by Large Language Model (LLM) agents in “vibe coding” scenarios using a new repository-level benchmark, SU S VI B E S. It reveals that over 80% of functionally correct solutions from leading LLM agents contain security vulnerabilities, and simple prompting strategies do not improve security.

08 Dec 2025
Large language models for code (LLM4Code) have greatly improved developer productivity but also raise privacy concerns due to their reliance on open-source repositories containing abundant personally identifiable information (PII). Prior work shows that commercial models can reproduce sensitive PII, yet existing studies largely treat PII as a single category and overlook the heterogeneous risks among different types. We investigate whether distinct PII types vary in their likelihood of being learned and leaked by LLM4Code, and whether this relationship is causal. Our methodology includes building a dataset with diverse PII types, fine-tuning representative models of different scales, computing training dynamics on real PII data, and formulating a structural causal model to estimate the causal effect of learnability on leakage. Results show that leakage risks differ substantially across PII types and correlate with their training dynamics: easy-to-learn instances such as IP addresses exhibit higher leakage, while harder types such as keys and passwords leak less frequently. Ambiguous types show mixed behaviors. This work provides the first causal evidence that leakage risks are type-dependent and offers guidance for developing type-aware and learnability-aware defenses for LLM4Code.
There are no more papers matching your filters at the moment.
