
08 Dec 2025


Vision-language models (VLMs) have demonstrated impressive multimodal comprehension capabilities and are being deployed in an increasing number of online video understanding applications. While recent efforts extensively explore advancing VLMs' reasoning power in these cases, deployment constraints are overlooked, leading to overwhelming system overhead in real-world deployments. To address that, we propose Venus, an on-device memory-and-retrieval system for efficient online video understanding. Venus proposes an edge-cloud disaggregated architecture that sinks memory construction and keyframe retrieval from cloud to edge, operating in two stages. In the ingestion stage, Venus continuously processes streaming edge videos via scene segmentation and clustering, where the selected keyframes are embedded with a multimodal embedding model to build a hierarchical memory for efficient storage and retrieval. In the querying stage, Venus indexes incoming queries from memory, and employs a threshold-based progressive sampling algorithm for keyframe selection that enhances diversity and adaptively balances system cost and reasoning accuracy. Our extensive evaluation shows that Venus achieves a 15x-131x speedup in total response latency compared to state-of-the-art methods, enabling real-time responses within seconds while maintaining comparable or even superior reasoning accuracy.

09 Dec 2025

The MVP framework introduces a training-free, two-stage approach that significantly improves the reliability and accuracy of GUI grounding models by addressing coordinate prediction instability. It achieves this by aggregating predictions from multiple attention-guided, enlarged views, leading to new state-of-the-art performance on challenging benchmarks like ScreenSpot-Pro and UI-Vision.

09 Dec 2025
Kernel density estimation is a key component of a wide variety of algorithms in machine learning, Bayesian inference, stochastic dynamics and signal processing. However, the unsupervised density estimation technique requires tuning a crucial hyperparameter: the kernel bandwidth. The choice of bandwidth is critical as it controls the bias-variance trade-off by over- or under-smoothing the topological features. Topological data analysis provides methods to mathematically quantify topological characteristics, such as connected components, loops, voids et cetera, even in high dimensions where visualization of density estimates is impossible. In this paper, we propose an unsupervised learning approach using a topology-based loss function for the automated and unsupervised selection of the optimal bandwidth and benchmark it against classical techniques -- demonstrating its potential across different dimensions.
08 Dec 2025
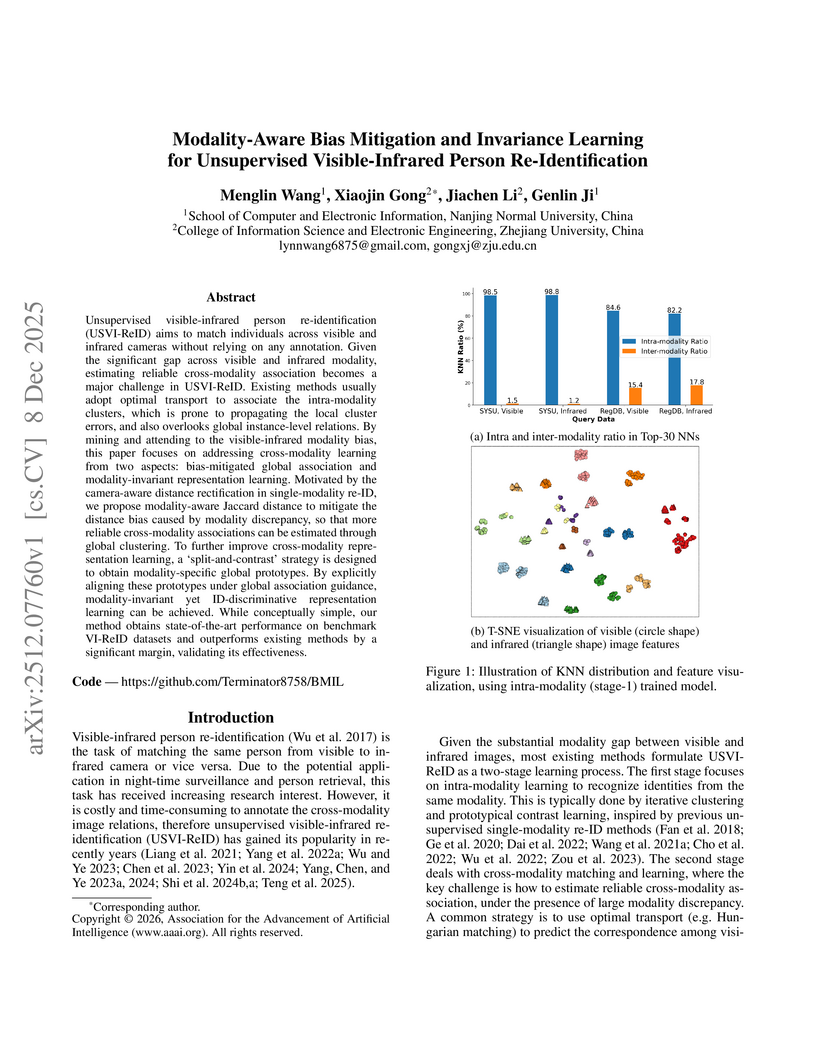
Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match individuals across visible and infrared cameras without relying on any annotation. Given the significant gap across visible and infrared modality, estimating reliable cross-modality association becomes a major challenge in USVI-ReID. Existing methods usually adopt optimal transport to associate the intra-modality clusters, which is prone to propagating the local cluster errors, and also overlooks global instance-level relations. By mining and attending to the visible-infrared modality bias, this paper focuses on addressing cross-modality learning from two aspects: bias-mitigated global association and modality-invariant representation learning. Motivated by the camera-aware distance rectification in single-modality re-ID, we propose modality-aware Jaccard distance to mitigate the distance bias caused by modality discrepancy, so that more reliable cross-modality associations can be estimated through global clustering. To further improve cross-modality representation learning, a `split-and-contrast' strategy is designed to obtain modality-specific global prototypes. By explicitly aligning these prototypes under global association guidance, modality-invariant yet ID-discriminative representation learning can be achieved. While conceptually simple, our method obtains state-of-the-art performance on benchmark VI-ReID datasets and outperforms existing methods by a significant margin, validating its effectiveness.

09 Dec 2025
Time delays in communication channels present significant challenges for bilateral teleoperation systems, affecting both transparency and stability. Although traditional wave variable-based methods for a four-channel architecture ensure stability via passivity, they remain vulnerable to wave reflections and disturbances like variable delays and environmental noise. This article presents a data-driven hybrid framework that replaces the conventional wave-variable transform with an ensemble of three advanced sequence models, each optimized separately via the state-of-the-art Optuna optimizer, and combined through a stacking meta-learner. The base predictors include an LSTM augmented with Prophet for trend correction, an LSTM-based feature extractor paired with clustering and a random forest for improved regression, and a CNN-LSTM model for localized and long-term dynamics. Experimental validation was performed in Python using data generated from the baseline system implemented in MATLAB/Simulink. The results show that our optimized ensemble achieves a transparency comparable to the baseline wave-variable system under varying delays and noise, while ensuring stability through passivity constraints.

08 Dec 2025
Traditional sea exploration faces significant challenges due to extreme conditions, limited visibility, and high costs, resulting in vast unexplored ocean regions. This paper presents an innovative AI-powered Autonomous Underwater Vehicle (AUV) system designed to overcome these limitations by automating underwater object detection, analysis, and reporting. The system integrates YOLOv12 Nano for real-time object detection, a Convolutional Neural Network (CNN) (ResNet50) for feature extraction, Principal Component Analysis (PCA) for dimensionality reduction, and K-Means++ clustering for grouping marine objects based on visual characteristics. Furthermore, a Large Language Model (LLM) (GPT-4o Mini) is employed to generate structured reports and summaries of underwater findings, enhancing data interpretation. The system was trained and evaluated on a combined dataset of over 55,000 images from the DeepFish and OzFish datasets, capturing diverse Australian marine environments. Experimental results demonstrate the system's capability to detect marine objects with a mAP@0.5 of 0.512, a precision of 0.535, and a recall of 0.438. The integration of PCA effectively reduced feature dimensionality while preserving 98% variance, facilitating K-Means clustering which successfully grouped detected objects based on visual similarities. The LLM integration proved effective in generating insightful summaries of detections and clusters, supported by location data. This integrated approach significantly reduces the risks associated with human diving, increases mission efficiency, and enhances the speed and depth of underwater data analysis, paving the way for more effective scientific research and discovery in challenging marine environments.

08 Dec 2025

Image tile-based approaches are popular in many image processing applications such as denoising (e.g., non-local means). A key step in their use is grouping the images into clusters, which usually proceeds iteratively splitting the images into clusters and fitting a model for the images in each cluster. Linear subspaces have emerged as a suitable model for tile clusters; however, they are not well matched to images patches given that images are non-negative and thus not distributed around the origin in the tile vector space. We study the use of affine subspace models for the clusters to better match the geometric structure of the image tile vector space. We also present a simple denoising algorithm that relies on the affine subspace clustering model using least squares projection. We review several algorithmic approaches to solve the affine subspace clustering problem and show experimental results that highlight the performance improvements in clustering and denoising.

06 Dec 2025
We develop a novel characterization of extremal dependence between two cortical regions of the brain when its signals display extremely large amplitudes. We show that connectivity in the tails of the distribution reveals unique features of extreme events (e.g., seizures) that can help to identify their occurrence. Numerous studies have established that connectivity-based features are effective for discriminating brain states. Here, we demonstrate the advantage of the proposed approach: that tail connectivity provides additional discriminatory power, enabling more accurate identification of extreme-related events and improved seizure risk management. Common approaches in tail dependence modeling use pairwise summary measures or parametric models. However, these approaches do not identify channels that drive the maximal tail dependence between two groups of signals -- an information that is useful when analyzing electroencephalography of epileptic patients where specific channels are responsible for seizure occurrences. A familiar approach in traditional signal processing is canonical correlation, which we extend to the tails to develop a visualization of extremal channel-contributions. Through the tail pairwise dependence matrix (TPDM), we develop a computationally-efficient estimator for our canonical tail dependence measure. Our method is then used for accurate frequency-based soft clustering of neonates, distinguishing those with seizures from those without.

03 Dec 2025
Recent foundation models have demonstrated strong performance in medical image representation learning, yet their comparative behaviour across datasets remains underexplored. This work benchmarks two large-scale chest X-ray (CXR) embedding models (CXR-Foundation (ELIXR v2.0) and MedImagelnsight) on public MIMIC-CR and NIH ChestX-ray14 datasets. Each model was evaluated using a unified preprocessing pipeline and fixed downstream classifiers to ensure reproducible comparison. We extracted embeddings directly from pre-trained encoders, trained lightweight LightGBM classifiers on multiple disease labels, and reported mean AUROC, and F1-score with 95% confidence intervals. MedImageInsight achieved slightly higher performance across most tasks, while CXR-Foundation exhibited strong cross-dataset stability. Unsupervised clustering of MedImageIn-sight embeddings further revealed a coherent disease-specific structure consistent with quantitative results. The results highlight the need for standardised evaluation of medical foundation models and establish reproducible baselines for future multimodal and clinical integration studies.

05 Dec 2025
We consider the fundamental problem of balanced -means clustering. In particular, we introduce an optimal transport approach to alternating minimization called BalLOT, and we show that it delivers a fast and effective solution to this problem. We establish this with a variety of numerical experiments before proving several theoretical guarantees. First, we prove that for generic data, BalLOT produces integral couplings at each step. Next, we perform a landscape analysis to provide theoretical guarantees for both exact and partial recoveries of planted clusters under the stochastic ball model. Finally, we propose initialization schemes that achieve one-step recovery of planted clusters.

04 Dec 2025


Text clustering is a fundamental task in natural language processing, yet traditional clustering algorithms with pre-trained embeddings often struggle in domain-specific contexts without costly fine-tuning. Large language models (LLMs) provide strong contextual reasoning, yet prior work mainly uses them as auxiliary modules to refine embeddings or adjust cluster boundaries. We propose ClusterFusion, a hybrid framework that instead treats the LLM as the clustering core, guided by lightweight embedding methods. The framework proceeds in three stages: embedding-guided subset partition, LLM-driven topic summarization, and LLM-based topic assignment. This design enables direct incorporation of domain knowledge and user preferences, fully leveraging the contextual adaptability of LLMs. Experiments on three public benchmarks and two new domain-specific datasets demonstrate that ClusterFusion not only achieves state-of-the-art performance on standard tasks but also delivers substantial gains in specialized domains. To support future work, we release our newly constructed dataset and results on all benchmarks.

05 Dec 2025
The main objective of this study is to propose an optimal transport based semi-supervised approach to learn from scarce labelled image data using deep convolutional networks. The principle lies in implicit graph-based transductive semi-supervised learning where the similarity metric between image samples is the Wasserstein distance. This metric is used in the label propagation mechanism during learning. We apply and demonstrate the effectiveness of the method on a GNSS real life application. More specifically, we address the problem of multi-path interference detection. Experiments are conducted under various signal conditions. The results show that for specific choices of hyperparameters controlling the amount of semi-supervision and the level of sensitivity to the metric, the classification accuracy can be significantly improved over the fully supervised training method.

01 Dec 2025
Researchers at MIT rigorously analyze the mean-field dynamics of Transformer attention, framing it as an interacting particle system that leads to eventual representation collapse but also exhibits long-lived metastable multi-cluster states. The work quantitatively explains the benefits of Pre-Layer Normalization in delaying collapse and identifies a phase transition in long-context attention with logarithmic scaling.

02 Dec 2025
Wastewater-based genomic surveillance has emerged as a powerful tool for population-level viral monitoring, offering comprehensive insights into circulating viral variants across entire communities. However, this approach faces significant computational challenges stemming from high sequencing noise, low viral coverage, fragmented reads, and the complete absence of labeled variant annotations. Traditional reference-based variant calling pipelines struggle with novel mutations and require extensive computational resources. We present a comprehensive framework for unsupervised viral variant detection using Vector-Quantized Variational Autoencoders (VQ-VAE) that learns discrete codebooks of genomic patterns from k-mer tokenized sequences without requiring reference genomes or variant labels. Our approach extends the base VQ-VAE architecture with masked reconstruction pretraining for robustness to missing data and contrastive learning for highly discriminative embeddings. Evaluated on SARS-CoV-2 wastewater sequencing data comprising approximately 100,000 reads, our VQ-VAE achieves 99.52% mean token-level accuracy and 56.33% exact sequence match rate while maintaining 19.73% codebook utilization (101 of 512 codes active), demonstrating efficient discrete representation learning. Contrastive fine-tuning with different projection dimensions yields substantial clustering improvements: 64-dimensional embeddings achieve +35% Silhouette score improvement (0.31 to 0.42), while 128-dimensional embeddings achieve +42% improvement (0.31 to 0.44), clearly demonstrating the impact of embedding dimensionality on variant discrimination capability. Our reference-free framework provides a scalable, interpretable approach to genomic surveillance with direct applications to public health monitoring.

02 Dec 2025
Accurate prediction of the Remaining Useful Life (RUL) in machinery can significantly diminish maintenance costs, enhance equipment up-time, and mitigate adverse outcomes. Data-driven RUL prediction techniques have demonstrated commendable performance. However, their efficacy often relies on the assumption that training and testing data are drawn from the same distribution or domain, which does not hold in real industrial settings. To mitigate this domain discrepancy issue, prior adversarial domain adaptation methods focused on deriving domain-invariant features. Nevertheless, they overlook target-specific information and inconsistency characteristics pertinent to the degradation stages, resulting in suboptimal performance. To tackle these issues, we propose a novel domain adaptation approach for cross-domain RUL prediction named TACDA. Specifically, we propose a target domain reconstruction strategy within the adversarial adaptation process, thereby retaining target-specific information while learning domain-invariant features. Furthermore, we develop a novel clustering and pairing strategy for consistent alignment between similar degradation stages. Through extensive experiments, our results demonstrate the remarkable performance of our proposed TACDA method, surpassing state-of-the-art approaches with regard to two different evaluation metrics. Our code is available at this https URL.

28 Nov 2025
In open-world scenarios, Generalized Category Discovery (GCD) requires identifying both known and novel categories within unlabeled data. However, existing methods often suffer from prototype confusion caused by shortcut learning, which undermines generalization and leads to forgetting of known classes. We propose ClearGCD, a framework designed to mitigate reliance on non-semantic cues through two complementary mechanisms. First, Semantic View Alignment (SVA) generates strong augmentations via cross-class patch replacement and enforces semantic consistency using weak augmentations. Second, Shortcut Suppression Regularization (SSR) maintains an adaptive prototype bank that aligns known classes while encouraging separation of potential novel ones. ClearGCD can be seamlessly integrated into parametric GCD approaches and consistently outperforms state-of-the-art methods across multiple benchmarks.

01 Dec 2025
This paper introduces a comprehensive unified framework for constructing multi-view diffusion geometries through intertwined multi-view diffusion trajectories (MDTs), a class of inhomogeneous diffusion processes that iteratively combine the random walk operators of multiple data views. Each MDT defines a trajectory-dependent diffusion operator with a clear probabilistic and geometric interpretation, capturing over time the interplay between data views. Our formulation encompasses existing multi-view diffusion models, while providing new degrees of freedom for view interaction and fusion. We establish theoretical properties under mild assumptions, including ergodicity of both the point-wise operator and the process in itself. We also derive MDT-based diffusion distances, and associated embeddings via singular value decompositions. Finally, we propose various strategies for learning MDT operators within the defined operator space, guided by internal quality measures. Beyond enabling flexible model design, MDTs also offer a neutral baseline for evaluating diffusion-based approaches through comparison with randomly selected MDTs. Experiments show the practical impact of the MDT operators in a manifold learning and data clustering context.

01 Dec 2025
Influence maximization in social networks plays a vital role in applications such as viral marketing, epidemiology, product recommendation, opinion mining, and counter-terrorism. A common approach identifies seed nodes by first detecting disjoint communities and subsequently selecting representative nodes from these communities. However, whether the quality of detected communities consistently affects the spread of influence under the Independent Cascade model remains unclear. This paper addresses this question by extending a previously proposed disjoint community detection method, termed -Hierarchical Clustering, to the influence maximization problem under the Independent Cascade model. The proposed method is compared with an alternative approach that employs the same seed selection criteria but relies on communities of lower quality obtained through standard Hierarchical Clustering. The former is referred to as Hierarchical Clustering-based Influence Maximization, while the latter, which leverages higher-quality community structures to guide seed selection, is termed -Hierarchical Clustering-based Influence Maximization. Extensive experiments are performed on multiple real-world datasets to assess the effectiveness of both methods. The results demonstrate that higher-quality community structures substantially improve information diffusion under the Independent Cascade model, particularly when the propagation probability is low. These findings underscore the critical importance of community quality in guiding effective seed selection for influence maximization in complex networks.
24 Nov 2025
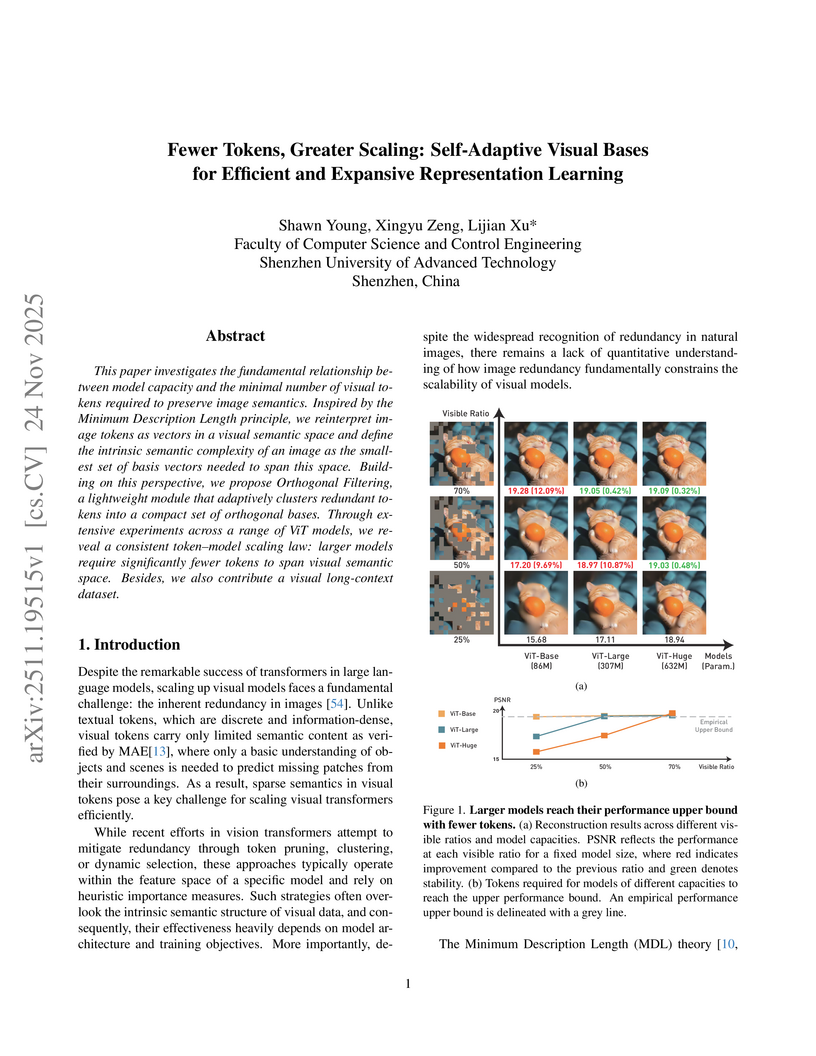
This paper investigates the fundamental relationship between model capacity and the minimal number of visual tokens required to preserve image semantics. Inspired by the Minimum Description Length principle, we reinterpret image tokens as vectors in a visual semantic space and define the intrinsic semantic complexity of an image as the smallest set of basis vectors needed to span this space. Building on this perspective, we propose Orthogonal Filtering, a lightweight module that adaptively clusters redundant tokens into a compact set of orthogonal bases. Through extensive experiments across a range of ViT models, we reveal a consistent token, model scaling law: larger models require significantly fewer tokens to span visual semantic space. Besides, we also contribute a visual long-context dataset.

27 Nov 2025

We curate the DeXposure dataset, the first large-scale dataset for inter-protocol credit exposure in decentralized financial networks, covering global markets of 43.7 million entries across 4.3 thousand protocols, 602 blockchains, and 24.3 thousand tokens, from 2020 to 2025. A new measure, value-linked credit exposure between protocols, is defined as the inferred financial dependency relationships derived from changes in Total Value Locked (TVL). We develop a token-to-protocol model using DefiLlama metadata to infer inter-protocol credit exposure from the token's stock dynamics, as reported by the protocols. Based on the curated dataset, we develop three benchmarks for machine learning research with financial applications: (1) graph clustering for global network measurement, tracking the structural evolution of credit exposure networks, (2) vector autoregression for sector-level credit exposure dynamics during major shocks (Terra and FTX), and (3) temporal graph neural networks for dynamic link prediction on temporal graphs. From the analysis, we observe (1) a rapid growth of network volume, (2) a trend of concentration to key protocols, (3) a decline of network density (the ratio of actual connections to possible connections), and (4) distinct shock propagation across sectors, such as lending platforms, trading exchanges, and asset management protocols. The DeXposure dataset and code have been released publicly. We envision they will help with research and practice in machine learning as well as financial risk monitoring, policy analysis, DeFi market modeling, amongst others. The dataset also contributes to machine learning research by offering benchmarks for graph clustering, vector autoregression, and temporal graph analysis.
There are no more papers matching your filters at the moment.
