
10 Dec 2025

Pedestrian routing choices play a crucial role in shaping collective crowd dynamics, yet the influence of interactions among unfamiliar individuals remains poorly understood. In this study, we analyze real-world pedestrian behavior at a route split within a busy train station using high-resolution trajectory data collected over a three-year time frame. We disclose a striking tendency for individuals to follow the same path as the person directly in front of them, even in the absence of social ties and even when such a choice leads to a longer travel time. This tendency leads to bursty dynamics, where sequences of pedestrians make identical decisions in succession, leading to strong patterns in collective movement. We employ a stochastic model that includes route costs, randomness, and social imitation to accurately reproduce the observed behavior, highlighting that local imitation behavior is the dominant driver of collective routing choices. These findings highlight how brief, low-level interactions between strangers can scale up to influence large-scale pedestrian movement, with strong implications for crowd management, urban design, and the broader understanding of social behavior in public spaces.

10 Dec 2025
Quantitative low-energy electron diffraction [LEED ] is a powerful method for surface-structure determination, based on a direct comparison of experimentally observed data with computations for a structure model. As the diffraction intensities are highly sensitive to subtle structural changes, local structure optimization is essential for assessing the validity of a structure model and finding the best-fit structure. The calculation of diffraction intensities is well established, but the large number of evaluations required for reliable structural optimization renders it computationally demanding. The computational effort is mitigated by the tensor-LEED approximation, which accelerates optimization by applying a perturbative treatment of small deviations from a reference structure. Nevertheless, optimization of complex structures is a tedious process.
Here, the problem of surface-structure optimization is reformulated using a tree-based data structure, which helps to avoid redundant function evaluations. In the new tensor-LEED implementation presented in this work, intensities are computed on the fly, eliminating limitations of previous algorithms that are limited to precomputed values at a grid of search parameters. It also enables the use of state-of-the-art optimization algorithms. Implemented in \textsc{Python} with the JAX library, the method provides access to gradients of the factor and supports execution on graphics processing units (GPUs). Based on these developments, the computing time can be reduced by more than an order of magnitude.

05 Dec 2025
We develop a theoretical framework that explains how gating mechanisms determine the learnability window of recurrent neural networks, defined as the largest temporal horizon over which gradient information remains statistically recoverable. While classical analyses emphasize numerical stability of Jacobian products, we show that stability alone is insufficient: learnability is governed instead by the \emph{effective learning rates} , per-lag and per-neuron quantities obtained from first-order expansions of gate-induced Jacobian products in Backpropagation Through Time. These effective learning rates act as multiplicative filters that control both the magnitude and anisotropy of gradient transport. Under heavy-tailed (-stable) gradient noise, we prove that the minimal sample size required to detect a dependency at lag~ satisfies , where is the effective learning rate envelope. This leads to an explicit formula for and closed-form scaling laws for logarithmic, polynomial, and exponential decay of . The theory predicts that broader or more heterogeneous gate spectra produce slower decay of and hence larger learnability windows, whereas heavier-tailed noise compresses by slowing statistical concentration. By linking gate-induced time-scale structure, gradient noise, and sample complexity, the framework identifies the effective learning rates as the fundamental quantities that govern when -- and for how long -- gated recurrent networks can learn long-range temporal dependencies.

06 Dec 2025
Correlations in complex systems are often obscured by nonstationarity, long-range memory, and heavy-tailed fluctuations, which limit the usefulness of traditional covariance-based analyses. To address these challenges, we construct scale and fluctuation-dependent correlation matrices using the multifractal detrended cross-correlation coefficient that selectively emphasizes fluctuations of different amplitudes. We examine the spectral properties of these detrended correlation matrices and compare them to the spectral properties of the matrices calculated in the same way from synthetic Gaussian and Gaussian signals. Our results show that detrending, heavy tails, and the fluctuation-order parameter jointly produce spectra, which substantially depart from the random case even under absence of cross-correlations in time series. Applying this framework to one-minute returns of 140 major cryptocurrencies from 2021-2024 reveals robust collective modes, including a dominant market factor and several sectoral components whose strength depends on the analyzed scale and fluctuation order. After filtering out the market mode, the empirical eigenvalue bulk aligns closely with the limit of random detrended cross-correlations, enabling clear identification of structurally significant outliers. Overall, the study provides a refined spectral baseline for detrended cross-correlations and offers a promising tool for distinguishing genuine interdependencies from noise in complex, nonstationary, heavy-tailed systems.

28 Nov 2025
Inferring the number of distinct components contributing to an observation, while simultaneously estimating their parameters, remains a long-standing challenge across signal processing, astrophysics, and neuroscience. Classical trans-dimensional Bayesian methods such as Reversible Jump Markov Chain Monte Carlo (RJMCMC) provide asymptotically exact inference but can be computationally expensive. Instead, modern deep learning provides a faster alternative to inference but typically assume fixed component counts, sidestepping the core challenge of trans-dimensionality. To address this, we introduce SlotFlow, a deep learning architecture for trans-dimensional amortized inference. The architecture processes time-series observations, which we represent jointly in the frequency and time domains through parallel encoders. A classifier produces a distribution over component counts K, and its MAP estimate specifies the number of slots instantiated. Each slot is parameterized by a shared conditional normalizing flow trained via permutation-invariant Hungarian matching. On sinusoidal decomposition with up to 10 overlapping components and Gaussian noise, SlotFlow achieves 99.85% cardinality accuracy and well-calibrated parameter posteriors, with systematic biases well below one posterior standard deviation. Direct comparison with RJMCMC shows close agreement in amplitude and phase, with Wasserstein distances W_2 < 0.01 and < 0.03, indicating that shared global context captures inter-component structure despite a factorized posterior. Frequency posteriors remain centered but exhibit 2-3x broader intervals, consistent with an encoder bottleneck in retaining long-baseline phase coherence. The method delivers a speedup over RJMCMC, suggesting applicability to time-critical workflows in gravitational-wave astronomy, neural spike sorting, and object-centric vision.

21 Nov 2025
Kenric Nelson from Photrek, Inc. rigorously proves the coupled entropy uniquely serves as a robust measure of uncertainty for nonlinear systems by demonstrating its equivalence to the negative logarithm of density at the informational scale. This advancement resolves limitations of existing generalized entropies for heavy-tailed distributions, enabling more accurate modeling of complex system behaviors and improving variational inference for extreme heavy-tailed data in AI applications.

04 Nov 2025
Buried pipelines transporting oil and gas across geohazard-prone regions are exposed to potential ground movement, leading to the risk of significant strain demand and structural failure. Reliability analysis, which determines the probability of failure after accounting for pertinent uncertainties, is essential for ensuring the safety of pipeline systems. However, traditional reliability analysis methods involving computationally intensive numerical models, such as finite element simulations of pipeline subjected to ground movement, have limited applications; this is partly because stochastic sampling approaches require repeated simulations over a large number of samples for the uncertain variables when estimating low probabilities. This study introduces Physics-Informed Neural Network for Reliability Analysis (PINN-RA) for buried pipelines subjected to ground movement, which integrates PINN-based surrogate model with Monte Carlo Simulation (MCS) to achieve efficient reliability assessment. To enable its application under uncertain variables associated with soil properties and ground movement, the PINN-based surrogate model is extended to solve a parametric differential equation system, namely the governing equation of pipelines embedded in soil with different properties. The findings demonstrate that PINN-RA significantly reduces the computational effort required and thus accelerates reliability analysis. By eliminating the need for repetitive numerical evaluations of pipeline subjected to permanent ground movement, the proposed approach provides an efficient and scalable tool for pipeline reliability assessment, enabling rapid decision-making in geohazard-prone regions.

19 Sep 2025



Implicit neural representations (INRs) have emerged as a compact and parametric alternative to discrete array-based data representations, encoding information directly in neural network weights to enable resolution-independent representation and memory efficiency. However, existing INR approaches, when constrained to compact network sizes, struggle to faithfully represent the multi-scale structures, high-frequency information, and fine textures that characterize the majority of scientific datasets. To address this limitation, we propose WIEN-INR, a wavelet-informed implicit neural representation that distributes modeling across different resolution scales and employs a specialized kernel network at the finest scale to recover subtle details. This multi-scale architecture allows for the use of smaller networks to retain the full spectrum of information while preserving the training efficiency and reducing storage cost. Through extensive experiments on diverse scientific datasets spanning different scales and structural complexities, WIEN-INR achieves superior reconstruction fidelity while maintaining a compact model size. These results demonstrate WIEN-INR as a practical neural representation framework for high-fidelity scientific data encoding, extending the applicability of INRs to domains where efficient preservation of fine detail is essential.

22 Aug 2025

Covariance localization is a critical component of ensemble-based data assimilation (DA) and many current localization schemes simply dampen correlations as a function of distance. Increases in computational resources, broadening scope of application for DA, and advances in general statistical methodology raise the question as to whether alternative localization methods may improve ensemble DA relative to current schemes. We carefully explore this issue by comparing distance based localization with alternative covariance localization techniques, partially those taken from the statistical literature. The comparison is done on test problems that we designed to challenge distance-based localization, including joint state-parameter estimation in a modified Lorenz '96 model and state estimation in a two-layer quasi-geostrophic model. Across all sets of experiments, we find that while localization of any kind (with rare exceptions) can lead to significant reductions in error, traditional, distance-based localization generally leads to the largest error reduction. More general localization schemes can sometimes lead to greater error reduction, though the impacts may only be marginal and may require more tuning and/or prior information.

30 May 2025
Objective: The aim of this study was to evaluate the efficacy of alendronate
therapy in improving bone density distribution in skull bones and corresponding
ultrasound permeability in patients who had previously experienced unsuccessful
transcranial MR-guided focused ultrasound (MRgFUS) ablation. The ability of
alendronate treatment to modify skull bone characteristics and enhance the
success rate of repeat MRgFUS procedures was assessed.
Methods: Five patients with initially unsuccessful MRgFUS ablations underwent
a 6-12 month regimen of alendronate to improve bone density. Repeat MRgFUS
procedures were performed, and changes in skull density ratio (SDR) and peak
focal temperatures were evaluated statistically using CT and MR imaging.
Histograms of skull bone density were introduced and analysed as an additional
metric.
Results: After therapy, SDR increased in four out of five patients (from
0.3780.037 to 0.4240.045, p>0.05). All repeated procedures were
successful. The maximum focal temperature, averaged over sonications, increased
from 53.64.0{\deg}C to 55.74.1{\deg}C (p=0.018), while the maximum
temperature per patient rose from 57.02.4{\deg}C to 60.21.8{\deg}C
(p=0.031). Histograms of CT scans showed a reduction in low-density voxels,
indicating trabecular bone densification. 3D CT scan registration revealed
local density changes, defect filling, and void reduction.
Conclusions: Alendronate therapy enhanced skull bone density distribution and
thus ultrasound permeability, which has facilitated successful repeat MRgFUS.
By visually analysing CT changes, healthcare professionals can better inform
their decision-making regarding repeat surgeries. This method broadens the pool
of patients with low SDR eligible for MRgFUS treatment and underscores the
potential benefits of alendronate in improving treatment outcomes.

15 May 2025
This research formulates Neural Thermodynamic Laws (NTL) to provide a mechanistic understanding of large language model (LLM) training dynamics. The work demonstrates that the learning rate functions as an effective temperature and derives an optimal 1/(t+t_h) decay schedule, linking training phenomena to classical thermodynamic principles such as the Equipartition Theorem and the Laws of Thermodynamics.

26 May 2025




This position paper argues that simplified layerwise linear models can explain complex deep neural network phenomena through a 'dynamical feedback principle'. It demonstrates how concepts like emergence, neural collapse, lazy/rich regimes, and grokking arise from the solvable dynamics of these models, redirecting focus to the fundamental role of layered architectures.

03 Nov 2025
In recent years, spatio-temporal graph neural networks (GNNs) have attracted considerable interest in the field of time series analysis, due to their ability to capture, at once, dependencies among variables and across time points. The objective of this systematic literature review is hence to provide a comprehensive overview of the various modeling approaches and application domains of GNNs for time series classification and forecasting. A database search was conducted, and 366 papers were selected for a detailed examination of the current state-of-the-art in the field. This examination is intended to offer to the reader a comprehensive review of proposed models, links to related source code, available datasets, benchmark models, and fitting results. All this information is hoped to assist researchers in their studies. To the best of our knowledge, this is the first and broadest systematic literature review presenting a detailed comparison of results from current spatio-temporal GNN models applied to different domains. In its final part, this review discusses current limitations and challenges in the application of spatio-temporal GNNs, such as comparability, reproducibility, explainability, poor information capacity, and scalability. This paper is complemented by a GitHub repository at this https URL providing additional interactive tools to further explore the presented findings.

08 Nov 2024


We introduce an approach for analyzing the responses of dynamical systems to external perturbations that combines score-based generative modeling with the Generalized Fluctuation-Dissipation Theorem (GFDT). The methodology enables accurate estimation of system responses, including those with non-Gaussian statistics. We numerically validate our approach using time-series data from three different stochastic partial differential equations of increasing complexity: an Ornstein-Uhlenbeck process with spatially correlated noise, a modified stochastic Allen-Cahn equation, and the 2D Navier-Stokes equations. We demonstrate the improved accuracy of the methodology over conventional methods and discuss its potential as a versatile tool for predicting the statistical behavior of complex dynamical systems.

21 May 2025
Energy-Based Models have emerged as a powerful framework in the realm of
generative modeling, offering a unique perspective that aligns closely with
principles of statistical mechanics. This review aims to provide physicists
with a comprehensive understanding of EBMs, delineating their connection to
other generative models such as Generative Adversarial Networks, Variational
Autoencoders, and Normalizing Flows. We explore the sampling techniques crucial
for EBMs, including Markov Chain Monte Carlo (MCMC) methods, and draw parallels
between EBM concepts and statistical mechanics, highlighting the significance
of energy functions and partition functions. Furthermore, we delve into recent
training methodologies for EBMs, covering recent advancements and their
implications for enhanced model performance and efficiency. This review is
designed to clarify the often complex interconnections between these models,
which can be challenging due to the diverse communities working on the topic.

13 Jun 2024
The demand for novel detector mediums such as Water-based Liquid Scintillator (WbLS) has increased over the last few decades due to their capability for both low energy particle interactions and higher light yield. Recently, the usage of machine learning (ML) methods in high-energy physics has also been increasing. The ML and AI methods are used in many physics projects in the field since they provide effective and sensitive results. In this study, we aimed to develop a comprehensive analysis of water Cherenkov detectors and perform physics analyses to efficiently separate Cherenkov and scintillation photons with ML algorithms using the data from the WbLS detector environment. The main goal of this study was to produce more precise solutions to physics problems, such as signal classification, by applying ML techniques to the simulation and experimental data. Here, we trained more than 20 ML models, and our results revealed that three machine learning models, XGBoost, Light GBM, and Random Forest models, and their ensemble model gave us more than 95\% accuracy for separating Cherenkov and scintillation photons with balanced and unbalanced datasets. This is a significant increase in efficiency as compared with the results of the classical method by applying simple time cuts.

21 May 2024





The search for heavy resonances beyond the Standard Model (BSM) is a key
objective at the LHC. While the recent use of advanced deep neural networks for
boosted-jet tagging significantly enhances the sensitivity of dedicated
searches, it is limited to specific final states, leaving vast potential BSM
phase space underexplored. We introduce a novel experimental method,
Signature-Oriented Pre-training for Heavy-resonance ObservatioN (Sophon), which
leverages deep learning to cover an extensive number of boosted final states.
Pre-trained on the comprehensive JetClass-II dataset, the Sophon model learns
intricate jet signatures, ensuring the optimal constructions of various jet
tagging discriminates and enabling high-performance transfer learning
capabilities. We show that the method can not only push widespread
model-specific searches to their sensitivity frontier, but also greatly improve
model-agnostic approaches, accelerating LHC resonance searches in a broad
sense.

11 Apr 2024

Physics-Informed Neural Networks (PINNs), which incorporate PDEs as soft
constraints, train with a composite loss function that contains multiple
training point types: different types of collocation points chosen during
training to enforce each PDE and initial/boundary conditions, and experimental
points which are usually costly to obtain via experiments or simulations.
Training PINNs using this loss function is challenging as it typically requires
selecting large numbers of points of different types, each with different
training dynamics. Unlike past works that focused on the selection of either
collocation or experimental points, this work introduces PINN Adaptive
ColLocation and Experimental points selection (PINNACLE), the first algorithm
that jointly optimizes the selection of all training point types, while
automatically adjusting the proportion of collocation point types as training
progresses. PINNACLE uses information on the interaction among training point
types, which had not been considered before, based on an analysis of PINN
training dynamics via the Neural Tangent Kernel (NTK). We theoretically show
that the criterion used by PINNACLE is related to the PINN generalization
error, and empirically demonstrate that PINNACLE is able to outperform existing
point selection methods for forward, inverse, and transfer learning problems.

26 Jun 2025



Researchers from multiple US institutions and the Exa.TrkX collaboration introduced NuGraph2, a Graph Neural Network for low-level particle reconstruction in Liquid Argon Time Projection Chambers. It achieved 98.0% recall and 97.9% precision for background filtering and 94.9% overall recall and precision for semantic labeling, while ensuring 94.8% 3D consistency across detector planes.
29 Jan 2024
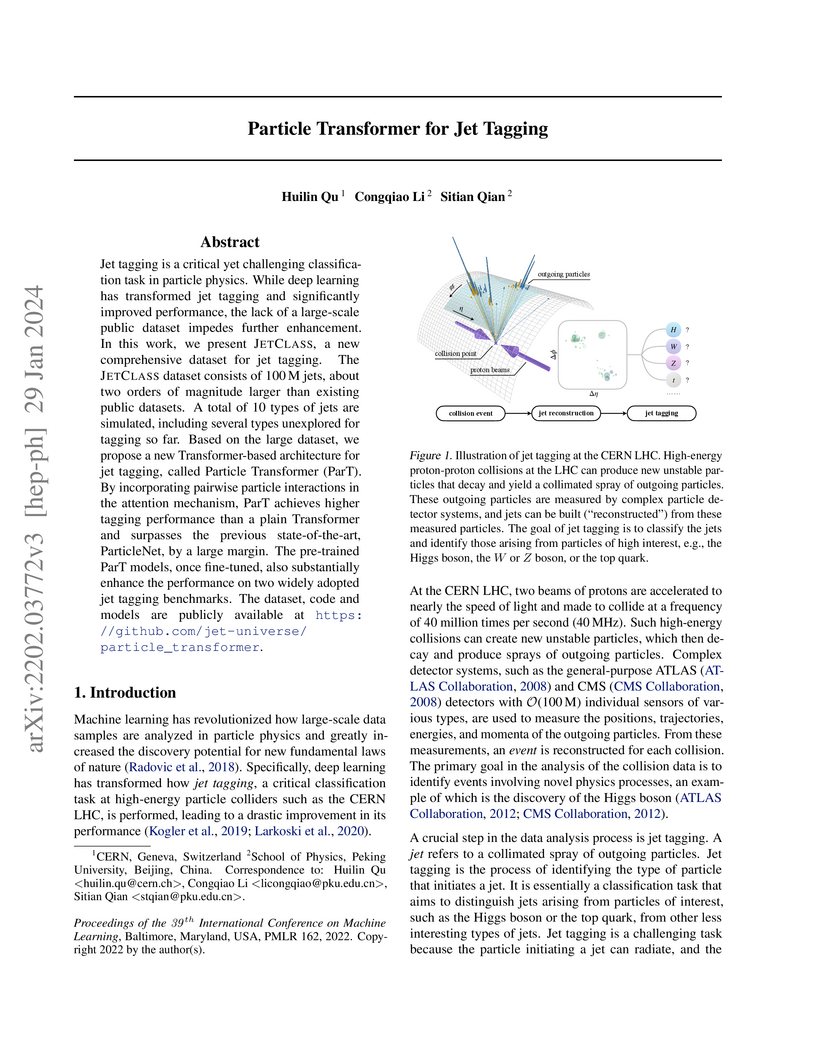
Jet tagging is a critical yet challenging classification task in particle physics. While deep learning has transformed jet tagging and significantly improved performance, the lack of a large-scale public dataset impedes further enhancement. In this work, we present JetClass, a new comprehensive dataset for jet tagging. The JetClass dataset consists of 100 M jets, about two orders of magnitude larger than existing public datasets. A total of 10 types of jets are simulated, including several types unexplored for tagging so far. Based on the large dataset, we propose a new Transformer-based architecture for jet tagging, called Particle Transformer (ParT). By incorporating pairwise particle interactions in the attention mechanism, ParT achieves higher tagging performance than a plain Transformer and surpasses the previous state-of-the-art, ParticleNet, by a large margin. The pre-trained ParT models, once fine-tuned, also substantially enhance the performance on two widely adopted jet tagging benchmarks. The dataset, code and models are publicly available at this https URL.
There are no more papers matching your filters at the moment.
