
08 Dec 2025


Vision-language models (VLMs) have demonstrated impressive multimodal comprehension capabilities and are being deployed in an increasing number of online video understanding applications. While recent efforts extensively explore advancing VLMs' reasoning power in these cases, deployment constraints are overlooked, leading to overwhelming system overhead in real-world deployments. To address that, we propose Venus, an on-device memory-and-retrieval system for efficient online video understanding. Venus proposes an edge-cloud disaggregated architecture that sinks memory construction and keyframe retrieval from cloud to edge, operating in two stages. In the ingestion stage, Venus continuously processes streaming edge videos via scene segmentation and clustering, where the selected keyframes are embedded with a multimodal embedding model to build a hierarchical memory for efficient storage and retrieval. In the querying stage, Venus indexes incoming queries from memory, and employs a threshold-based progressive sampling algorithm for keyframe selection that enhances diversity and adaptively balances system cost and reasoning accuracy. Our extensive evaluation shows that Venus achieves a 15x-131x speedup in total response latency compared to state-of-the-art methods, enabling real-time responses within seconds while maintaining comparable or even superior reasoning accuracy.

10 Dec 2025

Vector search underpins modern information-retrieval systems, including retrieval-augmented generation (RAG) pipelines and search engines over unstructured text and images. As datasets scale to billions of vectors, disk-based vector search has emerged as a practical solution. However, looking to the future, we need to anticipate datasets too large for any single server. We present BatANN, a distributed disk-based approximate nearest neighbor (ANN) system that retains the logarithmic search efficiency of a single global graph while achieving near-linear throughput scaling in the number of servers. Our core innovation is that when accessing a neighborhood which is stored on another machine, we send the full state of the query to the other machine to continue executing there for improved locality. On 100M- and 1B-point datasets at 0.95 recall using 10 servers, BatANN achieves 6.21-6.49x and 2.5-5.10x the throughput of the scatter-gather baseline, respectively, while maintaining mean latency below 6 ms. Moreover, we get these results on standard TCP. To our knowledge, BatANN is the first open-source distributed disk-based vector search system to operate over a single global graph.

09 Dec 2025
Training large language models (LLMs) efficiently requires a deep understanding of how modern GPU systems behave under real-world distributed training workloads. While prior work has focused primarily on kernel-level performance or single-GPU microbenchmarks, the complex interaction between communication, computation, memory behavior, and power management in multi-GPU LLM training remains poorly characterized. In this work, we introduce Chopper, a profiling and analysis framework that collects, aligns, and visualizes GPU kernel traces and hardware performance counters across multiple granularities (i.e., from individual kernels to operations, layers, phases, iterations, and GPUs). Using Chopper, we perform a comprehensive end-to-end characterization of Llama 3 8B training under fully sharded data parallelism (FSDP) on an eight-GPU AMD InstinctTM MI300X node. Our analysis reveals several previously underexplored bottlenecks and behaviors, such as memory determinism enabling higher, more stable GPU and memory frequencies. We identify several sources of inefficiencies, with frequency overhead (DVFS effects) being the single largest contributor to the gap between theoretical and observed performance, exceeding the impact of MFMA utilization loss, communication/computation overlap, and kernel launch overheads. Overall, Chopper provides the first holistic, multi-granularity characterization of LLM training on AMD InstinctTM MI300X GPUs, yielding actionable insights for optimizing training frameworks, improving power-management strategies, and guiding future GPU architecture and system design.

08 Dec 2025
The rapid adoption of large language models (LLMs) is pushing AI accelerators toward increasingly powerful and specialized designs. Instead of further complicating software development with deeply hierarchical scratchpad memories (SPMs) and their asynchronous management, we investigate the opposite point of the design spectrum: a multi-core AI accelerator equipped with a shared system-level cache and application-aware management policies, which keeps the programming effort modest. Our approach exploits dataflow information available in the software stack to guide cache replacement (including dead-block prediction), in concert with bypass decisions and mechanisms that alleviate cache thrashing.
We assess the proposal using a cycle-accurate simulator and observe substantial performance gains (up to 1.80x speedup) compared with conventional cache architectures. In addition, we build and validate an analytical model that takes into account the actual overlapping behaviors to extend the measurement results of our policies to real-world larger-scale workloads. Experiment results show that when functioning together, our bypassing and thrashing mitigation strategies can handle scenarios both with and without inter-core data sharing and achieve remarkable speedups.
Finally, we implement the design in RTL and the area of our design is with 15nm process, which can run at 2 GHz clock frequency. Our findings explore the potential of the shared cache design to assist the development of future AI accelerator systems.

09 Dec 2025
This research extends the Ozaki-II scheme for high-precision matrix multiplication to complex numbers, utilizing INT8 matrix engines for single and double-precision complex GEMM emulation. The framework achieves up to 6.5 times speedup on NVIDIA B200 GPUs and up to 30 times speedup on NVIDIA RTX 5080 GPUs for complex operations, while maintaining accuracy comparable to native routines.

06 Dec 2025
Decoupled loss has been a successful reinforcement learning (RL) algorithm to deal with the high data staleness under the asynchronous RL setting. Decoupled loss improves coupled-loss style of algorithms' (e.g., PPO, GRPO) learning stability by introducing a proximal policy to decouple the off-policy corrections (importance weight) from the controlling policy updates (trust region). However, the proximal policy requires an extra forward pass through the network at each training step, creating a computational bottleneck for large language models. We observe that since the proximal policy only serves as a trust region anchor between the behavior and target policies, we can approximate it through simple interpolation without explicit computation. We call this approach A-3PO (APproximated Proximal Policy Optimization). A-3PO eliminates this overhead, reducing training time by 18% while maintaining comparable performance. Code & off-the-shelf example are available at: this https URL

09 Dec 2025
Traditionally, multithreaded data structures have been designed for access by the threads of Operating Systems (OS). However, implementations for access by programmable alternatives known as lightweight threads (also referred to as asynchronous calls or coroutines) have not been thoroughly studied. The main advantage of lightweight threads is their significantly lower overhead during launch and context switching. However, this comes at a cost: to achieve proper parallelism, context switches must be manually invoked in the code; without these switches, new lightweight threads will never be executed.
In this paper, we focus on the simplest multithreaded data structure: a mutex (also known as a lock). We demonstrate that original implementations for OS threads cannot be used effectively in this new context due to the potential for deadlocks. Furthermore, correctness is not the only concern. In certain languages, such as C++, there are various lightweight thread libraries, each with different implementations and interfaces, which necessitate distinct lock implementations.
In this work, we present a modification of TTAS and MCS locks for the use from lightweight threads and demonstrate that the two context switch mechanisms of lightweight threads, yielding and sleeping, are crucial. However, the performance of TTAS and MCS may differ significantly depending on the settings. If one wants to have a lock that works well for any library, we suggest using the cohort lock, which strikes a balance between MCS and TTAS by utilizing several MCS queues with a common TTAS.

10 Dec 2025
Backpressure (BP) routing and scheduling is an established resource allocation method for wireless multi-hop networks, noted for its fully distributed operation and maximum queue stability. Recent advances in shortest path-biased BP routing (SP-BP) mitigate shortcomings such as slow startup and random walks, yet exclusive link-level commodity selection still causes last-packet problem and bandwidth underutilization. By revisiting the Lyapunov drift theory underlying BP, we show that the legacy exclusive commodity selection is unnecessary, and propose a Maximum Utility (MaxU) link-sharing method to expand its performance envelope without increasing control message overhead. Numerical results show that MaxU SP-BP substantially mitigates the last-packet problem and slightly expands the network capacity region.
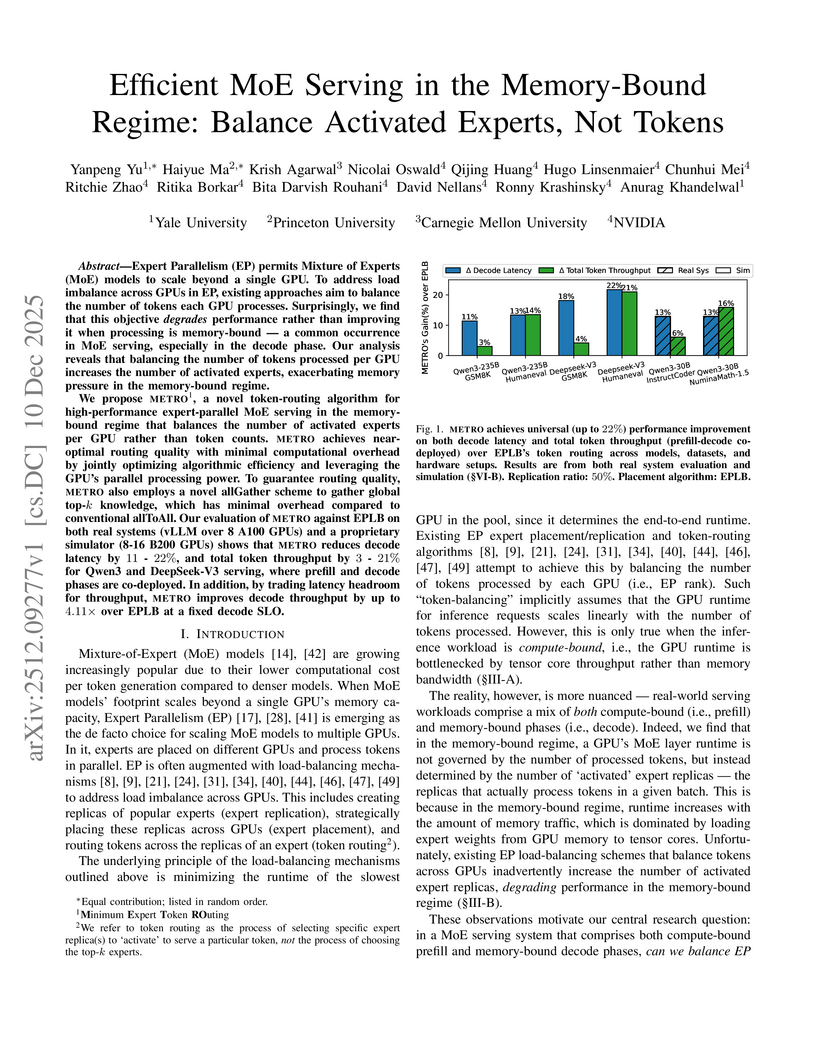
10 Dec 2025
Expert Parallelism (EP) permits Mixture of Experts (MoE) models to scale beyond a single GPU. To address load imbalance across GPUs in EP, existing approaches aim to balance the number of tokens each GPU processes. Surprisingly, we find that this objective degrades performance rather than improving it when processing is memory-bound - a common occurrence in MoE serving, especially in the decode phase. Our analysis reveals that balancing the number of tokens processed per GPU increases the number of activated experts, exacerbating memory pressure in the memory-bound regime.
We propose Minimum Expert Token ROuting, a novel token-routing algorithm for high-performance expert-parallel MoE serving in the memory-bound regime that balances the number of activated experts per GPU rather than token counts. METRO achieves near-optimal routing quality with minimal computational overhead by jointly optimizing algorithmic efficiency and leveraging the GPU's parallel processing power. To guarantee routing quality, METRO also employs a novel allGather scheme to gather global top-k knowledge, which has minimal overhead compared to conventional allToAll. Our evaluation of METRO against EPLB on both real systems (vLLM over 8 A100 GPUs) and a proprietary simulator (8-16 B200 GPUs) shows that METRO reduces decode latency by 11 - 22%, and total token throughput by 3 - 21% for Qwen3 and DeepSeek-V3 serving, where prefill and decode phases are co-deployed. In addition, by trading latency headroom for throughput, METRO improves decode throughput by up to 4.11x over EPLB at a fixed decode SLO.

10 Dec 2025
We describe SynthPix, a synthetic image generator for Particle Image Velocimetry (PIV) with a focus on performance and parallelism on accelerators, implemented in JAX. SynthPix supports the same configuration parameters as existing tools but achieves a throughput several orders of magnitude higher in image-pair generation per second. SynthPix was developed to enable the training of data-hungry reinforcement learning methods for flow estimation and for reducing the iteration times during the development of fast flow estimation methods used in recent active fluids control studies with real-time PIV feedback. We believe SynthPix to be useful for the fluid dynamics community, and in this paper we describe the main ideas behind this software package.

10 Dec 2025
Task scheduling is a critical research challenge in cloud computing, a transformative technology widely adopted across industries. Although numerous scheduling solutions exist, they predominantly optimize singular or limited metrics such as execution time or resource utilization often neglecting the need for comprehensive multi-objective optimization. To bridge this gap, this paper proposes the Pareto-based Hybrid Whale-Seagull Optimization Algorithm (PHWSOA). This algorithm synergistically combines the strengths of the Whale Optimization Algorithm (WOA) and the Seagull Optimization Algorithm (SOA), specifically mitigating WOA's limitations in local exploitation and SOA's constraints in global exploration. Leveraging Pareto dominance principles, PHWSOA simultaneously optimizes three key objectives: makespan, virtual machine (VM) load balancing, and economic cost. Key enhancements include: Halton sequence initialization for superior population diversity, a Pareto-guided mutation mechanism to avert premature convergence, and parallel processing for accelerated convergence. Furthermore, a dynamic VM load redistribution mechanism is integrated to improve load balancing during task execution. Extensive experiments conducted on the CloudSim simulator, utilizing real-world workload traces from NASA-iPSC and HPC2N, demonstrate that PHWSOA delivers substantial performance gains. Specifically, it achieves up to a 72.1% reduction in makespan, a 36.8% improvement in VM load balancing, and 23.5% cost savings. These results substantially outperform baseline methods including WOA, GA, PEWOA, and GCWOA underscoring PHWSOA's strong potential for enabling efficient resource management in practical cloud environments.

10 Dec 2025
Diverse scientific and engineering research areas deal with discrete, time-stamped changes in large systems of interacting delay differential equations. Simulating such complex systems at scale on high-performance computing clusters demands efficient management of communication and memory. Inspired by the human cerebral cortex -- a sparsely connected network of neurons, each forming -- synapses and communicating via short electrical pulses called spikes -- we study the simulation of large-scale spiking neural networks for computational neuroscience research. This work presents a novel network construction method for multi-GPU clusters and upcoming exascale supercomputers using the Message Passing Interface (MPI), where each process builds its local connectivity and prepares the data structures for efficient spike exchange across the cluster during state propagation. We demonstrate scaling performance of two cortical models using point-to-point and collective communication, respectively.

29 Nov 2025

A method from Peking University introduces InvarDiff, a training-free caching scheme for Transformer-based diffusion models (DiT-family) that exploits cross-scale feature invariance. It achieves up to 3.31x end-to-end acceleration on FLUX.1-dev and 2.86x on DiT-XL/2, while maintaining or even enhancing visual quality metrics like LPIPS and SSIM.

04 Dec 2025

CXL-based Computational Memory (CCM) enables near-memory processing within expanded remote memory, presenting opportunities to address data movement costs associated with disaggregated memory systems and to accelerate overall performance. However, existing operation offloading mechanisms are not capable of leveraging the trade-offs of different models based on different CXL protocols. This work first examines these tradeoffs and demonstrates their impact on end-to-end performance and system efficiency for workloads with diverse data and processing requirements. We propose a novel 'Asynchronous Back-Streaming' protocol by carefully layering data and control transfer operations on top of the underlying CXL protocols. We design KAI, a system that realizes the asynchronous back-streaming model that supports asynchronous data movement and lightweight pipelining in host-CCM interactions. Overall, KAI reduces end-to-end runtime by up to 50.4%, and CCM and host idle times by average 22.11x and 3.85x, respectively.

27 Nov 2025
LLM serving is increasingly dominated by decode attention, which is a memory-bound operation due to massive KV cache loading from global memory. Meanwhile, real-world workloads exhibit substantial, hierarchical shared prefixes across requests (e.g., system prompts, tools/templates, RAG). Existing attention implementations fail to fully exploit prefix sharing: *one-query-per-CTA* execution repeatedly loads shared prefix KV cache, while *one-size-fits-all* tiling leaves on-chip resources idle and exacerbates bubbles for uneven KV lengths. These choices amplify memory bandwidth pressure and stall memory-bound decode attention.
This paper introduces PAT, a prefix-aware attention kernel implementation for LLM decoding that organizes execution with a pack-forward-merge paradigm. PAT packs queries by shared prefix to reduce repeated memory accesses, runs a customized multi-tile kernel to achieve high resource efficiency. It further applies practical multi-stream forwarding and KV splitting to reduce resource bubbles. The final merge performs online softmax with negligible overhead. We implement PAT as an off-the-shelf plugin for vLLM. Evaluation on both real-world and synthetic workloads shows that PAT reduces attention latency by 67.4% on average and TPOT by 13.6-83.4% under the same configurations against state-of-the-art attention kernels.

28 Nov 2025


To meet strict Service-Level Objectives (SLOs),contemporary Large Language Models (LLMs) decouple the prefill and decoding stages and place them on separate GPUs to mitigate the distinct bottlenecks inherent to each phase. However, the heterogeneity of LLM workloads causes producerconsumer imbalance between the two instance types in such disaggregated architecture. To address this problem, we propose DOPD (Dynamic Optimal Prefill/Decoding), a dynamic LLM inference system that adjusts instance allocations to achieve an optimal prefill-to-decoding (P/D) ratio based on real-time load monitoring. Combined with an appropriate request-scheduling policy, DOPD effectively resolves imbalances between prefill and decoding instances and mitigates resource allocation mismatches due to mixed-length requests under high concurrency. Experimental evaluations show that, compared with vLLM and DistServe (representative aggregation-based and disaggregationbased approaches), DOPD improves overall system goodput by up to 1.5X, decreases P90 time-to-first-token (TTFT) by up to 67.5%, and decreases P90 time-per-output-token (TPOT) by up to 22.8%. Furthermore, our dynamic P/D adjustment technique performs proactive reconfiguration based on historical load, achieving over 99% SLOs attainment while using less additional resources.

27 Nov 2025
Large Language Models drive a wide range of modern AI applications but impose substantial challenges on large-scale serving systems due to intensive computation, strict latency constraints, and throughput bottlenecks. We introduce OmniInfer, a unified system-level acceleration framework designed to maximize end-to-end serving efficiency through fine-grained optimization of expert placement, cache compression, and scheduling. OmniInfer integrates three complementary components: OmniPlacement for load-aware Mixture-of-Experts scheduling, OmniAttn for sparse attention acceleration, and OmniProxy for disaggregation-aware request scheduling. Built atop vLLM, OmniInfer delivers system-wide performance gains through adaptive resource disaggregation, efficient sparsity exploitation, and global coordination across prefill and decode phases. Evaluated on DeepSeek-R1 within a 10-node Ascend 910C cluster, OmniInfer achieves 616 QPM, where the unified framework reduces TPOT by 36\%, and the superimposition of OmniProxy further slashes TTFT by 38\%. The project is open-sourced at [this https URL](this https URL).

26 Nov 2025
Large Language Models (LLMs) are increasingly deployed in both latency-sensitive online services and cost-sensitive offline workloads. Co-locating these workloads on shared serving instances can improve resource utilization, but directly applying this approach to Prefill/Decode (P/D) disaggregated systems introduces severe load imbalance, as fluctuating request mixes alter the intrinsic P/D ratio. Existing dynamic adjustment techniques cannot keep up with the bursty traffic patterns of online services.
We propose a latency-constraint disaggregated architecture, which separates cluster resources into latency-strict and latency-relaxed pools based on task latency requirements. This design enables flexible placement of offline decode tasks, mitigating P/D imbalance while preserving online performance. To fully exploit this flexibility, we propose (1) a bottleneck-based scheduler guided by a Roofline-based performance model for performance bottleneck based scheduling, and (2) a fast preemption mechanism that strictly enforces Service Level Objectives (SLOs) for online requests.
Experiments on real-world traces show that compared to existing offline system approaches, our method improves offline throughput by up to 3x, while maintaining online request SLOs.

03 Dec 2025
We present tritonBLAS, a fast and deterministic analytical model that uses architectural parameters like the cache hierarchy, and relative code and data placement to generate performant GPU GEMM kernels. tritonBLAS explicitly models the relationship between architectural topology, matrix shapes, and algorithmic blocking behavior to predict near-optimal configurations without runtime autotuning. Based on this model, we developed and implemented a lightweight GEMM framework entirely within Triton. We evaluate the performance of tritonBLAS across a diverse set of GEMM problem sizes on modern GPUs. tritonBLAS achieves over 95% of the performance of autotuning solutions, while reducing autotuning time to zero. This makes tritonBLAS a practical drop-in replacement for empirical tuning in production HPC and ML workloads.

03 Dec 2025
This paper discusses the challenges encountered when analyzing the energy efficiency of synthetic benchmarks and the Gromacs package on the Fritz and Alex HPC clusters. Experiments were conducted using MPI parallelism on full sockets of Intel Ice Lake and Sapphire Rapids CPUs, as well as Nvidia A40 and A100 GPUs. The metrics and measurements obtained with the Likwid and Nvidia profiling tools are presented, along with the results. The challenges and pitfalls encountered during experimentation and analysis are revealed and discussed. Best practices for future energy efficiency analysis studies are suggested.
There are no more papers matching your filters at the moment.
