
09 Jul 2025

ReCamMaster introduces a framework for camera-controlled generative video re-rendering, enabling the synthesis of new videos from a single input video with novel camera trajectories. The method leverages a novel "Frame Dimension Conditioning" mechanism and a large-scale synthetic dataset, achieving improved visual quality, camera accuracy, and view synchronization over prior approaches.
19 Sep 2025

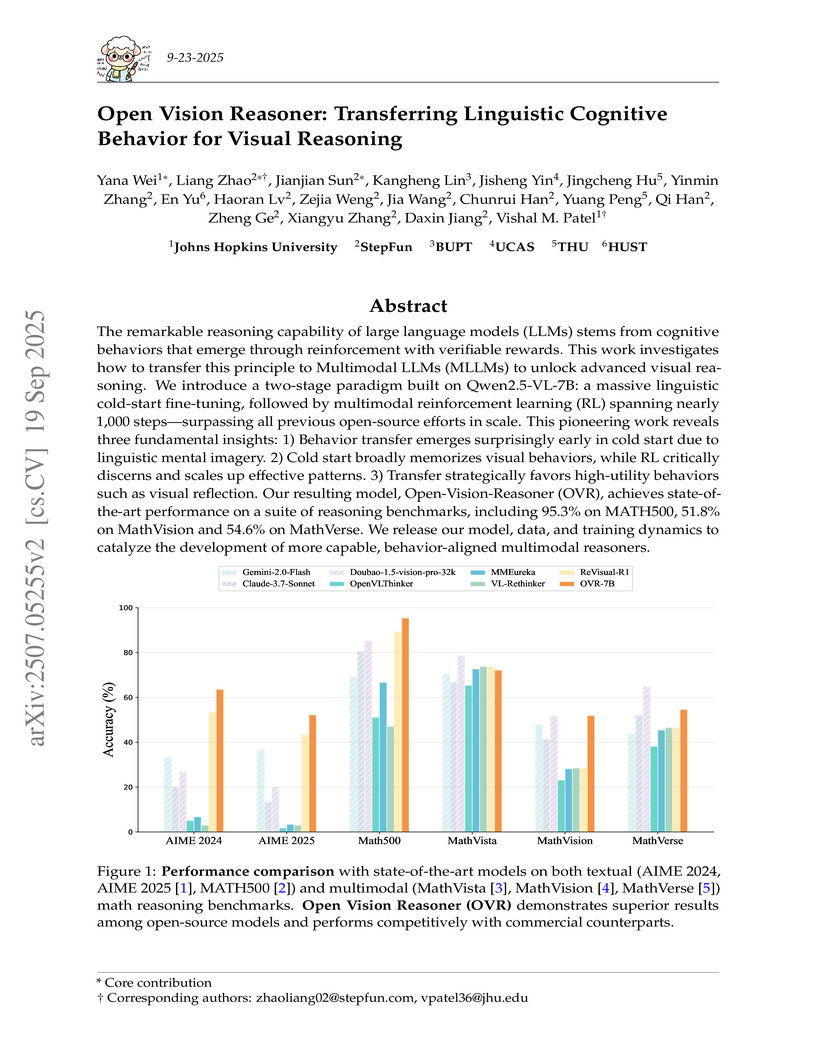
The remarkable reasoning capability of large language models (LLMs) stems from cognitive behaviors that emerge through reinforcement with verifiable rewards. This work investigates how to transfer this principle to Multimodal LLMs (MLLMs) to unlock advanced visual reasoning. We introduce a two-stage paradigm built on Qwen2.5-VL-7B: a massive linguistic cold-start fine-tuning, followed by multimodal reinforcement learning (RL) spanning nearly 1,000 steps, surpassing all previous open-source efforts in scale. This pioneering work reveals three fundamental insights: 1) Behavior transfer emerges surprisingly early in cold start due to linguistic mental imagery. 2) Cold start broadly memorizes visual behaviors, while RL critically discerns and scales up effective patterns. 3) Transfer strategically favors high-utility behaviors such as visual reflection. Our resulting model, Open-Vision-Reasoner (OVR), achieves state-of-the-art performance on a suite of reasoning benchmarks, including 95.3% on MATH500, 51.8% on MathVision and 54.6% on MathVerse. We release our model, data, and training dynamics to catalyze the development of more capable, behavior-aligned multimodal reasoners.

04 Dec 2025

Reward Forcing introduces EMA-Sink and Rewarded Distribution Matching Distillation (Re-DMD) to enable efficient, real-time streaming video generation. This framework achieves an overall VBench score of 84.13 and a generation speed of 23.1 FPS, while significantly enhancing motion dynamics and maintaining long-horizon consistency.

11 Jun 2025
Researchers from HKU, DAMO Academy (Alibaba Group), and HUST develop PlayerOne, the first egocentric realistic world simulator that enables users to actively explore dynamic environments through free human motion control, achieving superior performance with 67.8 DINO-Score vs 38.0-51.6 for state-of-the-art competitors through a diffusion transformer architecture featuring part-disentangled motion injection that categorizes human motion into body/feet, hands, and head components with dedicated encoders, joint scene-frame reconstruction using point maps for 4D consistency, and a coarse-to-fine training strategy combining large-scale egocentric text-video pre-training with fine-grained motion-video alignment on a curated dataset from EgoExo-4D and other sources, demonstrating real-time generation at 8 FPS while maintaining strict alignment between generated egocentric videos and real-scene human motion captured by exocentric cameras across diverse realistic scenarios.

24 Mar 2025




The ISG framework, ISG-BENCH, and ISG-AGENT are proposed to evaluate and improve interleaved text-and-image generation, revealing current unified models' limitations and showcasing the effectiveness of a compositional "Plan-Execute-Refine" strategy.

16 Oct 2024

Researchers from Tsinghua University, Shanghai Jiao Tong University, and Shanghai AI Lab present a comprehensive, efficiency-oriented survey of diffusion models (DMs), organizing advancements across principles, architecture, training, sampling, and deployment. The survey addresses the scalability challenges of DMs, providing a structured understanding of techniques that enhance their performance, cost-effectiveness, and real-world applicability across diverse generative tasks.

04 Dec 2025
LIGHT-X, developed by researchers from NTU, BAAI, and other institutions, introduces a generative framework for 4D videos that enables simultaneous control of camera trajectory and illumination from monocular inputs. The system achieves superior relighting quality and temporal consistency, outperforming combined baseline methods with a FID of 101.06 for joint control and 83.65 for video relighting.

12 Oct 2025
AdaViewPlanner introduces a two-stage paradigm to adapt pre-trained Text-to-Video (T2V) diffusion models for viewpoint planning in 4D scenes. This approach generates professional, plausible, and text-conditioned camera trajectories for human motion, outperforming existing baselines in qualitative assessments and user preferences.

11 Jun 2025

AnomalyAnything (AnomalyAny), developed by researchers from EPFL, ETH Zurich, and HUST, introduces a training-free framework that leverages pre-trained foundation models to generate realistic, diverse, and 'unseen' visual anomalies from a single normal image and text prompts. These synthetically generated anomalies significantly enhance the performance of downstream anomaly detection models, particularly in data-scarce, few-shot settings, outperforming existing methods on MVTec AD and VisA datasets.

15 Mar 2024


DREAMLLM is an MLLM that achieves synergistic multimodal comprehension and creation by directly modeling language and image posteriors through raw multimodal space sampling and interleaved generative pre-training. It establishes new state-of-the-art performance in various vision-language comprehension tasks and is the first to generate free-form interleaved documents with autonomously placed, high-quality images.

30 Sep 2025
 Shanghai Jiao Tong University
Shanghai Jiao Tong University Tsinghua University
Tsinghua University Zhejiang University
Zhejiang University ByteDanceThe Chinese University of Hong Kong, Shenzhen
ByteDanceThe Chinese University of Hong Kong, Shenzhen Nanyang Technological UniversityUniversity of RochesterHong Kong Polytechnic University
Nanyang Technological UniversityUniversity of RochesterHong Kong Polytechnic University Waseda UniversityHong Kong University of Science and Technology (Guangzhou)HUSTCASNational Univeristy of SingaporeBJTUQHUBNBU
Waseda UniversityHong Kong University of Science and Technology (Guangzhou)HUSTCASNational Univeristy of SingaporeBJTUQHUBNBU
Audio Large Language Models (ALLMs) have gained widespread adoption, yet their trustworthiness remains underexplored. Existing evaluation frameworks, designed primarily for text, fail to address unique vulnerabilities introduced by audio's acoustic properties. We identify significant trustworthiness risks in ALLMs arising from non-semantic acoustic cues, including timbre, accent, and background noise, which can manipulate model behavior. We propose AudioTrust, a comprehensive framework for systematic evaluation of ALLM trustworthiness across audio-specific risks. AudioTrust encompasses six key dimensions: fairness, hallucination, safety, privacy, robustness, and authentication. The framework implements 26 distinct sub-tasks using a curated dataset of over 4,420 audio samples from real-world scenarios, including daily conversations, emergency calls, and voice assistant interactions. We conduct comprehensive evaluations across 18 experimental configurations using human-validated automated pipelines. Our evaluation of 14 state-of-the-art open-source and closed-source ALLMs reveals significant limitations when confronted with diverse high-risk audio scenarios, providing insights for secure deployment of audio models. Code and data are available at this https URL.

03 Jul 2025
Shanghai Jiao Tong University Nanjing University
Nanjing University HuaweiSYSUShenzhen University
HuaweiSYSUShenzhen University Southern University of Science and Technology
Southern University of Science and Technology HKUSTTHUHorizon RoboticsSJTUNJUVIVOUESTCHUSTD-roboticsJingdong Technology Information Technology Co., LtdNEUBUAAAgileX RoboticsBJTUSangfor Technologies Inc.HKU MMLabSUSTSZUSWJTUDexmalUSSTSCUReconova Technologies Co.Huawei GermanyCAUCSHU
HKUSTTHUHorizon RoboticsSJTUNJUVIVOUESTCHUSTD-roboticsJingdong Technology Information Technology Co., LtdNEUBUAAAgileX RoboticsBJTUSangfor Technologies Inc.HKU MMLabSUSTSZUSWJTUDexmalUSSTSCUReconova Technologies Co.Huawei GermanyCAUCSHU

The RoboTwin Dual-Arm Collaboration Challenge established a comprehensive benchmark for generalizable bimanual manipulation, bridging simulation and real-world environments through progressively difficult tasks. It revealed that while advanced simulation techniques can lead to high performance, significant challenges remain in real-world deformable object handling and sim-to-real transfer, with top teams achieving only 26.4% success in the final complex real-world tasks.

24 Oct 2025
Multimodal Large Language Models (MLLMs) increasingly excel at perception, understanding, and reasoning. However, current benchmarks inadequately evaluate their ability to perform these tasks continuously in dynamic, real-world environments. To bridge this gap, we introduce RTV-Bench, a fine-grained benchmark for MLLM real-time video analysis. RTV-Bench uses three key principles: (1) Multi-Timestamp Question Answering (MTQA), where answers evolve with scene changes; (2) Hierarchical Question Structure, combining basic and advanced queries; and (3) Multi-dimensional Evaluation, assessing the ability of continuous perception, understanding, and reasoning. RTV-Bench contains 552 diverse videos (167.2 hours) and 4,631 high-quality QA pairs. We evaluated leading MLLMs, including proprietary (GPT-4o, Gemini 2.0), open-source offline (Qwen2.5-VL, VideoLLaMA3), and open-source real-time (VITA-1.5, InternLM-XComposer2.5-OmniLive) models. Experiment results show open-source real-time models largely outperform offline ones but still trail top proprietary models. Our analysis also reveals that larger model size or higher frame sampling rates do not significantly boost RTV-Bench performance, sometimes causing slight decreases. This underscores the need for better model architectures optimized for video stream processing and long sequences to advance real-time video analysis with MLLMs. Our benchmark toolkit is available at: this https URL.

02 Dec 2024

The application of language models (LMs) to molecular structure generation using line notations such as SMILES and SELFIES has been well-established in the field of cheminformatics. However, extending these models to generate 3D molecular structures presents significant challenges. Two primary obstacles emerge: (1) the difficulty in designing a 3D line notation that ensures SE(3)-invariant atomic coordinates, and (2) the non-trivial task of tokenizing continuous coordinates for use in LMs, which inherently require discrete inputs. To address these challenges, we propose Mol-StrucTok, a novel method for tokenizing 3D molecular structures. Our approach comprises two key innovations: (1) We design a line notation for 3D molecules by extracting local atomic coordinates in a spherical coordinate system. This notation builds upon existing 2D line notations and remains agnostic to their specific forms, ensuring compatibility with various molecular representation schemes. (2) We employ a Vector Quantized Variational Autoencoder (VQ-VAE) to tokenize these coordinates, treating them as generation descriptors. To further enhance the representation, we incorporate neighborhood bond lengths and bond angles as understanding descriptors. Leveraging this tokenization framework, we train a GPT-2 style model for 3D molecular generation tasks. Results demonstrate strong performance with significantly faster generation speeds and competitive chemical stability compared to previous methods. Further, by integrating our learned discrete representations into Graphormer model for property prediction on QM9 dataset, Mol-StrucTok reveals consistent improvements across various molecular properties, underscoring the versatility and robustness of our approach.

28 May 2025

VideoAnydoor is an end-to-end zero-shot framework for high-fidelity video object insertion that maintains object identity and provides precise motion control. It surpasses current methods in both identity preservation and motion consistency through novel components like an ID Extractor and a Pixel Warper, as demonstrated through quantitative metrics and user studies.

01 Dec 2025

In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.

13 Nov 2023


RCACopilot, developed by Microsoft and academic collaborators, automates root cause analysis for cloud incidents by combining automated multi-source diagnostic data collection with large language model-based prediction. The system achieved a Micro-F1 score of 0.766 for root cause category prediction and is deployed across over 30 Microsoft teams, demonstrating efficiency and practical utility.
25 Aug 2025
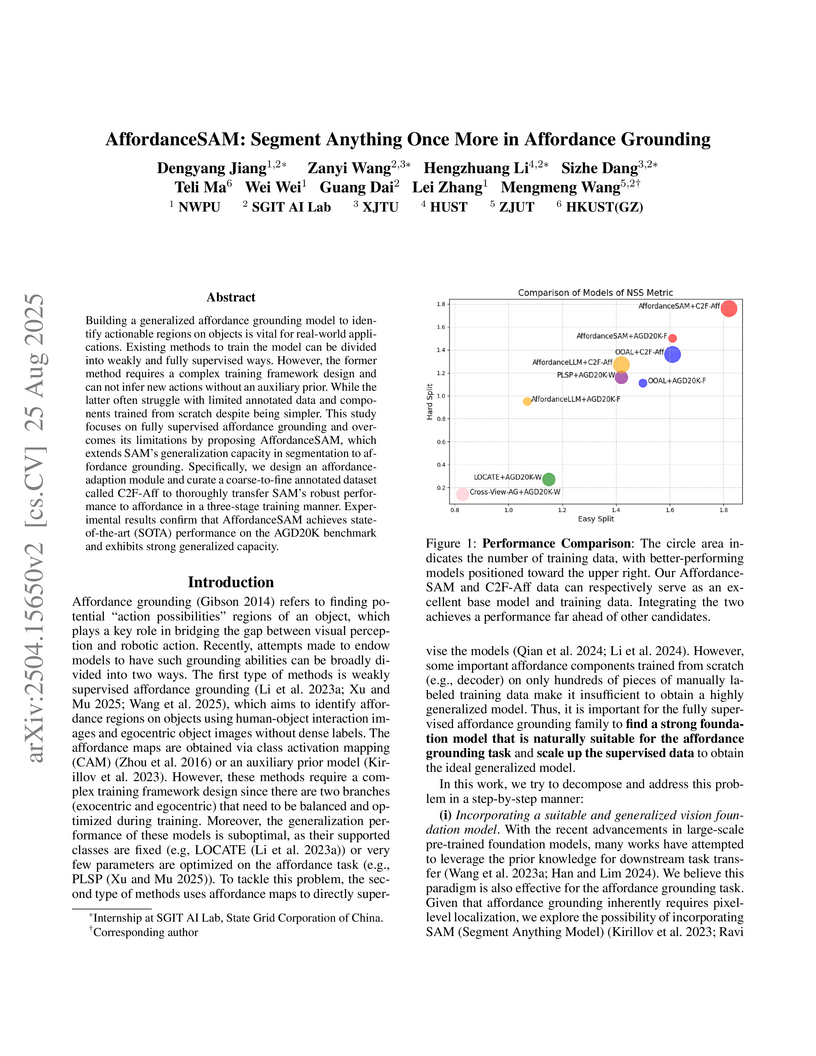
AffordanceSAM adapts the Segment Anything Model (SAM) for affordance grounding, integrating a specialized adaptation module and a coarse-to-fine training scheme. The framework achieves state-of-the-art performance on the AGD20K benchmark and demonstrates robust generalization to novel objects and actions.

23 Nov 2025
Multimodal Large Language Models (MLLMs) perform well in video understanding but degrade on long videos due to fixed-length context and weak long-term dependency modeling. Retrieval-Augmented Generation (RAG) can expand knowledge dynamically, yet existing video RAG schemes adopt fixed retrieval paradigms that ignore query difficulty. This uniform design causes redundant computation and latency for simple queries, while coarse retrieval for complex, multi-hop reasoning can miss key information. Such single-step retrieval severely limits the trade-off between efficiency and cognitive depth. We propose AdaVideoRAG, an adaptive RAG framework for long-video understanding. A lightweight intent classifier dynamically selects suitable retrieval schemes according to query complexity from the simplest to the most sophisticated. We design an Omni-Knowledge Indexing module that extracts and organizes multi-modal information into three databases: (1) a text base built from clip captions, ASR, and OCR; (2) a visual base; and (3) a knowledge graph for deep semantic understanding. This supports hierarchical knowledge access, from naive retrieval to graph-based retrieval, balancing resource cost and reasoning ability. To evaluate deep understanding, we further construct the HiVU benchmark. Experiments show that AdaVideoRAG significantly improves both efficiency and accuracy on long-video QA tasks and can be seamlessly plugged into existing MLLMs through lightweight APIs, establishing a new paradigm for adaptive retrieval-augmented video analysis.

02 Dec 2025

LumiX, developed by researchers at King Abdullah University of Science and Technology and Huazhong University of Science and Technology, presents a generative model that produces coherent sets of intrinsic maps (RGB, albedo, irradiance, depth, normal) directly from text prompts. It achieves superior cross-map structural consistency, with an alignment score of 8.30 (compared to baselines like 2.40), and demonstrates zero-shot intrinsic image decomposition capabilities.
There are no more papers matching your filters at the moment.
