
08 Dec 2025
This research disentangles the causal effects of pre-training, mid-training, and reinforcement learning (RL) on language model reasoning using a controlled synthetic task framework. It establishes that RL extends reasoning capabilities only under specific conditions of pre-training exposure and data calibration, with mid-training playing a crucial role in bridging training stages and improving generalization.

09 Dec 2025
The paper empirically investigates the performance of multi-agent LLM systems across diverse agentic tasks and architectures, revealing that benefits are highly contingent on task structure rather than universal. It establishes a quantitative scaling principle, achieving 87% accuracy in predicting optimal agent architectures for unseen tasks based on model capability, task properties, and measured coordination dynamics.

08 Dec 2025
The Native Parallel Reasoner (NPR) framework allows Large Language Models to autonomously acquire and deploy genuine parallel reasoning capabilities, without relying on external teacher models. Experiments show NPR improves accuracy by up to 24.5% over baselines and delivers up to 4.6 times faster inference, maintaining 100% parallel execution across various benchmarks.

08 Dec 2025

The DEMOCRITUS system establishes a new framework for building large causal models (LCMs) by extracting and structuring textual knowledge from Large Language Models (LLMs) across diverse domains. It leverages a Geometric Transformer to embed and organize vast causal claims into coherent, navigable manifolds, which, unlike raw LLM outputs, exhibit global causal coherence and interpretable local structures.

09 Dec 2025
This work presents a comprehensive engineering guide for designing and deploying production-grade agentic AI workflows, offering nine best practices demonstrated through a multimodal news-to-media generation case study. The approach improves system determinism, reliability, and responsible AI integration, reducing issues like hallucination and enabling scalable, maintainable deployments.

10 Dec 2025

UniUGP presents a unified framework for end-to-end autonomous driving, integrating scene understanding, future video generation, and trajectory planning through a hybrid expert architecture. This approach enhances interpretability with Chain-of-Thought reasoning and demonstrates state-of-the-art performance in challenging long-tail scenarios and multimodal capabilities across various benchmarks.

10 Dec 2025


Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM's reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning. Collectively, our results suggest that long, human-like CoT reasoning may not be necessary for general video reasoning, and that concise reasoning can be both effective and efficient. Our code will be released at this https URL.

09 Dec 2025
EcomBench introduces a comprehensive benchmark for evaluating foundation agents in e-commerce, drawing on genuine user demands and expert curation to assess real-world capabilities. The evaluation demonstrates that leading models achieve strong performance on basic tasks but struggle significantly with complex, multi-step e-commerce reasoning and integrating knowledge from various sources.

09 Dec 2025
Multimodal Large Language Models (MLLMs) exhibit substantial cross-modal inconsistency, producing different answers for semantically identical information presented across image, text, and mixed modalities. This problem persists even with perfect Optical Character Recognition (OCR), revealing an inherent reasoning challenge where text inputs generally achieve higher accuracy than image inputs.

07 Dec 2025



This research introduces PersonaMem-v2, a dataset designed for implicit user persona learning, and an agentic memory framework, enabling smaller LLMs to achieve state-of-the-art personalization performance. The agentic memory system processes long conversational histories into a compact 2k-token memory, resulting in a 16x efficiency improvement while outperforming frontier models like GPT-5 variants.

10 Dec 2025





Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.

08 Dec 2025
Researchers from the University of Technology Sydney and Zhejiang University developed VideoCoF, a unified video editing framework that introduces a "Chain of Frames" approach for explicit visual reasoning. This method achieves mask-free, fine-grained edits, demonstrating a 15.14% improvement in instruction following and an 18.6% higher success ratio on their VideoCoF-Bench, while also providing robust length extrapolation.

07 Dec 2025
An independent research team secured 1st place in the 2025 BEHAVIOR Challenge, achieving a 26% q-score by enhancing a Vision-Language-Action model (Pi0.5) with innovations like correlated noise for flow matching, "System 2" stage tracking, and practical inference-time heuristics. The approach demonstrated emergent recovery behaviors and addressed challenges in long-horizon, complex manipulation tasks.

07 Dec 2025
ProAgent introduces an end-to-end proactive LLM agent system leveraging on-demand multi-modal sensory contexts from AR glasses to anticipate user needs without explicit commands. It achieved a 33.4% higher proactive accuracy and 16.8% higher F1-score for tool calling compared to existing baselines, while operating efficiently on edge devices.

07 Dec 2025
Researchers from Peking University and Huawei Technologies developed a principled framework for adapting pre-trained autoregressive (AR) models into Block-Diffusion Language Models (DLMs). The adapted 7B-class model, NBDIFF-7B, achieved state-of-the-art performance among diffusion LLMs, with a macro average of 64.3 for its base version and 78.8 for its instruct version across diverse benchmarks.

05 Dec 2025
Edward Y. Chang from Stanford University proposes a "Substrate plus Coordination" framework for Artificial General Intelligence (AGI), arguing that Large Language Models (LLMs) provide a necessary System-1 pattern-matching substrate that requires a System-2 coordination layer to achieve reliable, goal-directed reasoning. This work formalizes semantic anchoring through the Unified Contextual Control Theory (UCCT) and introduces the Multi-Agent Collaborative Intelligence (MACI) architecture to implement this missing layer.

10 Dec 2025
Researchers from the University of Rochester, Purdue University, and Northeastern University developed VisualActBench, a benchmark designed to assess Vision-Language Models' (VLMs) ability to perform proactive, vision-centric action reasoning and align with human value systems. Their evaluation of 29 state-of-the-art VLMs demonstrated a substantial gap between current models and human-level performance, particularly in generating high-priority, initiative-driven actions based solely on visual input.
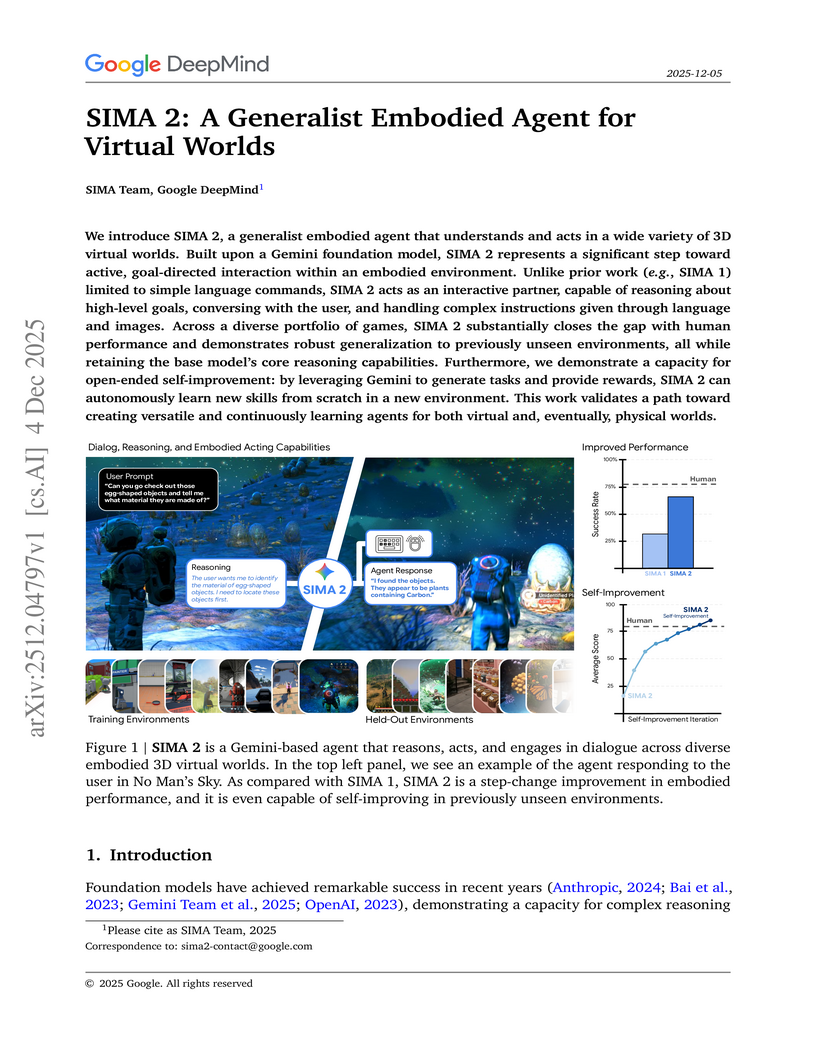
04 Dec 2025

Google DeepMind developed SIMA 2, a generalist embodied agent powered by a Gemini Flash-Lite model, capable of understanding and acting in diverse 3D virtual worlds. It substantially doubles the task success rate of its predecessor SIMA 1, generalizes to unseen commercial games and photorealistic environments, and demonstrates autonomous skill acquisition through a Gemini-based self-improvement mechanism.

10 Dec 2025
Researchers at Zhejiang University developed Video-QTR, a query-driven temporal reasoning framework for video understanding that dynamically allocates perceptual resources based on query intent. This system achieved state-of-the-art accuracy on long-video benchmarks while reducing input frame consumption by up to 73%.

09 Dec 2025
Foundation models (FMs) are increasingly assuming the role of the "brain" of AI agents. While recent efforts have begun to equip FMs with native single-agent abilities -- such as GUI interaction or integrated tool use -- we argue that the next frontier is endowing FMs with native multi-agent intelligence. We identify four core capabilities of FMs in multi-agent contexts: understanding, planning, efficient communication, and adaptation. Contrary to assumptions about the spontaneous emergence of such abilities, we provide extensive empirical evidence across 41 large language models showing that strong single-agent performance alone does not automatically yield robust multi-agent intelligence. To address this gap, we outline key research directions -- spanning dataset construction, evaluation, training paradigms, and safety considerations -- for building FMs with native multi-agent intelligence.
There are no more papers matching your filters at the moment.
