
09 Dec 2025
SAM-Body4D introduces a training-free framework for 4D human body mesh recovery from videos, synergistically combining promptable video object segmentation and image-based human mesh recovery models with an occlusion-aware mask refinement module. The system produces temporally consistent and robust mesh trajectories, effectively handling occlusions and maintaining identity across frames.

10 Dec 2025

Recent advances in diffusion models have greatly improved image generation and editing, yet generating or reconstructing layered PSD files with transparent alpha channels remains highly challenging. We propose OmniPSD, a unified diffusion framework built upon the Flux ecosystem that enables both text-to-PSD generation and image-to-PSD decomposition through in-context learning. For text-to-PSD generation, OmniPSD arranges multiple target layers spatially into a single canvas and learns their compositional relationships through spatial attention, producing semantically coherent and hierarchically structured layers. For image-to-PSD decomposition, it performs iterative in-context editing, progressively extracting and erasing textual and foreground components to reconstruct editable PSD layers from a single flattened image. An RGBA-VAE is employed as an auxiliary representation module to preserve transparency without affecting structure learning. Extensive experiments on our new RGBA-layered dataset demonstrate that OmniPSD achieves high-fidelity generation, structural consistency, and transparency awareness, offering a new paradigm for layered design generation and decomposition with diffusion transformers.
10 Dec 2025

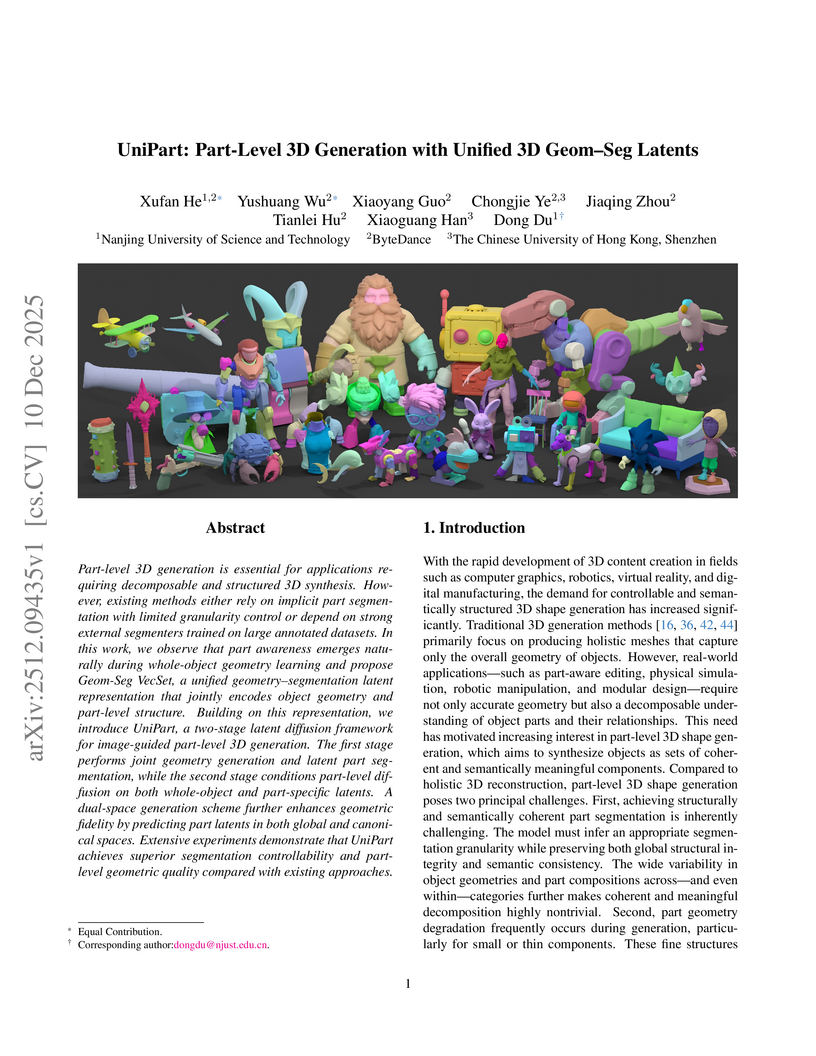
Part-level 3D generation is essential for applications requiring decomposable and structured 3D synthesis. However, existing methods either rely on implicit part segmentation with limited granularity control or depend on strong external segmenters trained on large annotated datasets. In this work, we observe that part awareness emerges naturally during whole-object geometry learning and propose Geom-Seg VecSet, a unified geometry-segmentation latent representation that jointly encodes object geometry and part-level structure. Building on this representation, we introduce UniPart, a two-stage latent diffusion framework for image-guided part-level 3D generation. The first stage performs joint geometry generation and latent part segmentation, while the second stage conditions part-level diffusion on both whole-object and part-specific latents. A dual-space generation scheme further enhances geometric fidelity by predicting part latents in both global and canonical spaces. Extensive experiments demonstrate that UniPart achieves superior segmentation controllability and part-level geometric quality compared with existing approaches.

10 Dec 2025
Synthesizing realistic human-object interactions (HOI) in video is challenging due to the complex, instance-specific interaction dynamics of both humans and objects. Incorporating controllability in video generation further adds to the complexity. Existing controllable video generation approaches face a trade-off: sparse controls like keypoint trajectories are easy to specify but lack instance-awareness, while dense signals such as optical flow, depths or 3D meshes are informative but costly to obtain. We propose VHOI, a two-stage framework that first densifies sparse trajectories into HOI mask sequences, and then fine-tunes a video diffusion model conditioned on these dense masks. We introduce a novel HOI-aware motion representation that uses color encodings to distinguish not only human and object motion, but also body-part-specific dynamics. This design incorporates a human prior into the conditioning signal and strengthens the model's ability to understand and generate realistic HOI dynamics. Experiments demonstrate state-of-the-art results in controllable HOI video generation. VHOI is not limited to interaction-only scenarios and can also generate full human navigation leading up to object interactions in an end-to-end manner. Project page: this https URL.

10 Dec 2025
We present NordFKB, a fine-grained benchmark dataset for geospatial AI in Norway, derived from the authoritative, highly accurate, national Felles KartdataBase (FKB). The dataset contains high-resolution orthophotos paired with detailed annotations for 36 semantic classes, including both per-class binary segmentation masks in GeoTIFF format and COCO-style bounding box annotations. Data is collected from seven geographically diverse areas, ensuring variation in climate, topography, and urbanization. Only tiles containing at least one annotated object are included, and training/validation splits are created through random sampling across areas to ensure representative class and context distributions. Human expert review and quality control ensures high annotation accuracy. Alongside the dataset, we release a benchmarking repository with standardized evaluation protocols and tools for semantic segmentation and object detection, enabling reproducible and comparable research. NordFKB provides a robust foundation for advancing AI methods in mapping, land administration, and spatial planning, and paves the way for future expansions in coverage, temporal scope, and data modalities.

09 Dec 2025
SegEarth-OV3 introduces a training-free adaptation of the Segment Anything Model 3 (SAM 3) for open-vocabulary semantic segmentation in remote sensing images. The method establishes a new state-of-the-art for training-free approaches, achieving a 53.4% average mIoU across eight remote sensing benchmarks, an improvement of 12.7% mIoU over previous methods.

09 Dec 2025
Simultaneous Localization and Mapping (SLAM) is a foundational component in robotics, AR/VR, and autonomous systems. With the rising focus on spatial AI in recent years, combining SLAM with semantic understanding has become increasingly important for enabling intelligent perception and interaction. Recent efforts have explored this integration, but they often rely on depth sensors or closed-set semantic models, limiting their scalability and adaptability in open-world environments. In this work, we present OpenMonoGS-SLAM, the first monocular SLAM framework that unifies 3D Gaussian Splatting (3DGS) with open-set semantic understanding. To achieve our goal, we leverage recent advances in Visual Foundation Models (VFMs), including MASt3R for visual geometry and SAM and CLIP for open-vocabulary semantics. These models provide robust generalization across diverse tasks, enabling accurate monocular camera tracking and mapping, as well as a rich understanding of semantics in open-world environments. Our method operates without any depth input or 3D semantic ground truth, relying solely on self-supervised learning objectives. Furthermore, we propose a memory mechanism specifically designed to manage high-dimensional semantic features, which effectively constructs Gaussian semantic feature maps, leading to strong overall performance. Experimental results demonstrate that our approach achieves performance comparable to or surpassing existing baselines in both closed-set and open-set segmentation tasks, all without relying on supplementary sensors such as depth maps or semantic annotations.

07 Dec 2025
This paper proposes a novel self-supervised learning method for semantic segmentation using selective masking image reconstruction as the pretraining task. Our proposed method replaces the random masking augmentation used in most masked image modelling pretraining methods. The proposed selective masking method selectively masks image patches with the highest reconstruction loss by breaking the image reconstruction pretraining into iterative steps to leverage the trained model's knowledge. We show on two general datasets (Pascal VOC and Cityscapes) and two weed segmentation datasets (Nassar 2020 and Sugarbeets 2016) that our proposed selective masking method outperforms the traditional random masking method and supervised ImageNet pretraining on downstream segmentation accuracy by 2.9% for general datasets and 2.5% for weed segmentation datasets. Furthermore, we found that our selective masking method significantly improves accuracy for the lowest-performing classes. Lastly, we show that using the same pretraining and downstream dataset yields the best result for low-budget self-supervised pretraining. Our proposed Selective Masking Image Reconstruction method provides an effective and practical solution to improve end-to-end semantic segmentation workflows, especially for scenarios that require limited model capacity to meet inference speed and computational resource requirements.

09 Dec 2025


Zero-Splat TeleAssist introduces a zero-shot pose estimation framework for semantic teleoperation that utilizes commodity CCTV streams and advanced AI models to provide real-time 6-DoF robot poses. This system reduces operator cognitive load by 27% and task completion time by 32% in human-robot interaction tasks.

04 Dec 2025
This paper investigates the fundamental discontinuity between the latest two Segment Anything Models: SAM2 and SAM3. We explain why the expertise in prompt-based segmentation of SAM2 does not transfer to the multimodal concept-driven paradigm of SAM3. SAM2 operates through spatial prompts points, boxes, and masks yielding purely geometric and temporal segmentation. In contrast, SAM3 introduces a unified vision-language architecture capable of open-vocabulary reasoning, semantic grounding, contrastive alignment, and exemplar-based concept understanding. We structure this analysis through five core components: (1) a Conceptual Break Between Prompt-Based and Concept-Based Segmentation, contrasting spatial prompt semantics of SAM2 with multimodal fusion and text-conditioned mask generation of SAM3; (2) Architectural Divergence, detailing pure vision-temporal design of SAM2 versus integration of vision-language encoders, geometry and exemplar encoders, fusion modules, DETR-style decoders, object queries, and ambiguity-handling via Mixture-of-Experts in SAM3; (3) Dataset and Annotation Differences, contrasting SA-V video masks with multimodal concept-annotated corpora of SAM3; (4) Training and Hyperparameter Distinctions, showing why SAM2 optimization knowledge does not apply to SAM3; and (5) Evaluation, Metrics, and Failure Modes, outlining the transition from geometric IoU metrics to semantic, open-vocabulary evaluation. Together, these analyses establish SAM3 as a new class of segmentation foundation model and chart future directions for the emerging concept-driven segmentation era.

05 Dec 2025
Recently, Vision Large Language Models (VLMs) have demonstrated high potential in computer-aided diagnosis and decision-support. However, current VLMs show deficits in domain specific surgical scene understanding, such as identifying and explaining anatomical landmarks during Complete Mesocolic Excision. Additionally, there is a need for locally deployable models to avoid patient data leakage to large VLMs, hosted outside the clinic. We propose a privacy-preserving framework to distill knowledge from large, general-purpose LLMs into an efficient, local VLM. We generate an expert-supervised dataset by prompting a teacher LLM without sensitive images, using only textual context and binary segmentation masks for spatial information. This dataset is used for Supervised Fine-Tuning (SFT) and subsequent Direct Preference Optimization (DPO) of the locally deployable VLM. Our evaluation confirms that finetuning VLMs with our generated datasets increases surgical domain knowledge compared to its base VLM by a large margin. Overall, this work validates a data-efficient and privacy-conforming way to train a surgical domain optimized, locally deployable VLM for surgical scene understanding.

05 Dec 2025
Cross-Domain Few-Shot Semantic Segmentation (CD-FSS) seeks to segment unknown classes in unseen domains using only a few annotated examples. This setting is inherently challenging: source and target domains exhibit substantial distribution shifts, label spaces are disjoint, and support images are scarce--making standard episodic methods unreliable and computationally demanding at test time. To address these constraints, we propose DistillFSS, a framework that embeds support-set knowledge directly into a model's parameters through a teacher--student distillation process. By internalizing few-shot reasoning into a dedicated layer within the student network, DistillFSS eliminates the need for support images at test time, enabling fast, lightweight inference, while allowing efficient extension to novel classes in unseen domains through rapid teacher-driven specialization. Combined with fine-tuning, the approach scales efficiently to large support sets and significantly reduces computational overhead. To evaluate the framework under realistic conditions, we introduce a new CD-FSS benchmark spanning medical imaging, industrial inspection, and remote sensing, with disjoint label spaces and variable support sizes. Experiments show that DistillFSS matches or surpasses state-of-the-art baselines, particularly in multi-class and multi-shot scenarios, while offering substantial efficiency gains. The code is available at this https URL.

04 Dec 2025



A new Transformer-based architecture introduces the first feed-forward unified framework for 4D language grounding, enabling open-vocabulary querying in dynamic environments without per-scene optimization. This approach achieves state-of-the-art performance on HyperNeRF and Neu3D datasets, demonstrating up to a 3% mIoU improvement and strong generalization capabilities for both time-agnostic and time-sensitive queries.

01 Dec 2025
Researchers from Tsinghua University and Alibaba Group introduced ViT^3, a Vision Transformer framework that leverages Test-Time Training (TTT) to overcome the quadratic computational complexity of traditional attention mechanisms. This approach achieves linear complexity while consistently matching or outperforming other efficient models across image classification, object detection, semantic segmentation, and image generation benchmarks.

03 Dec 2025
Motion4D introduces a framework that integrates 2D foundation model priors into a dynamic 3D Gaussian Splatting representation to achieve 3D-consistent motion and semantic understanding for 4D scenes from monocular videos. This approach establishes new state-of-the-art results across video object segmentation, 2D/3D point tracking, and novel view synthesis tasks.
02 Dec 2025
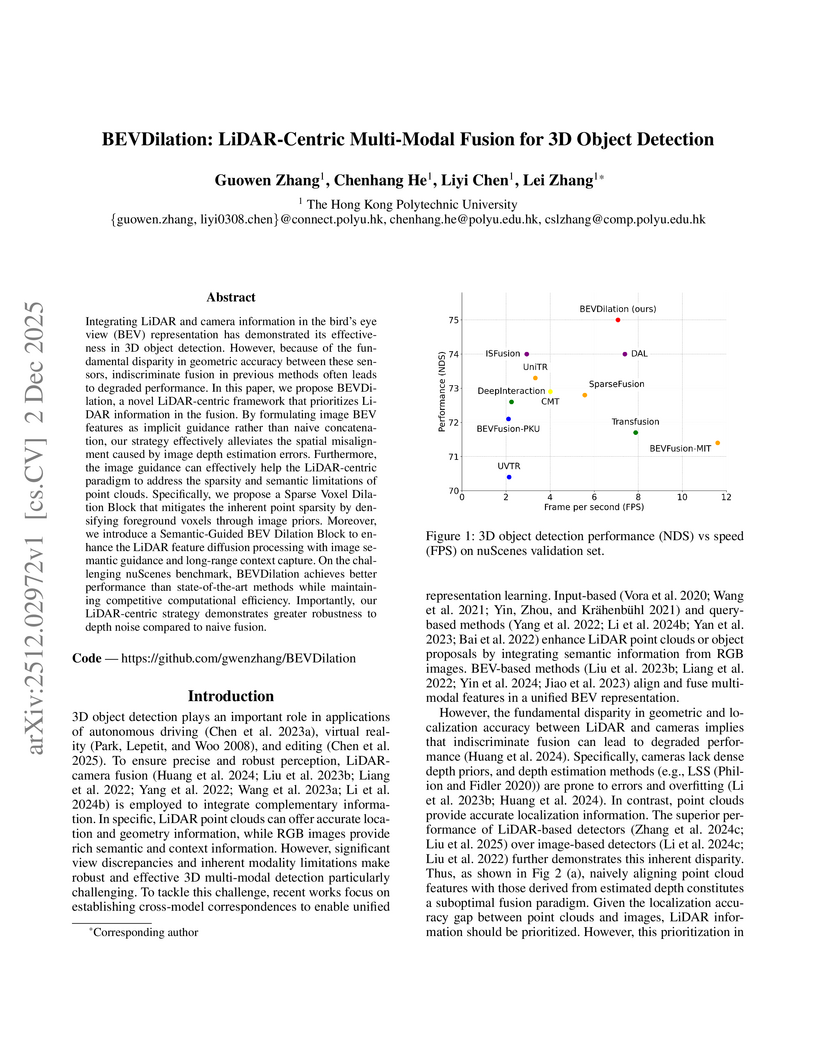
Integrating LiDAR and camera information in the bird's eye view (BEV) representation has demonstrated its effectiveness in 3D object detection. However, because of the fundamental disparity in geometric accuracy between these sensors, indiscriminate fusion in previous methods often leads to degraded performance. In this paper, we propose BEVDilation, a novel LiDAR-centric framework that prioritizes LiDAR information in the fusion. By formulating image BEV features as implicit guidance rather than naive concatenation, our strategy effectively alleviates the spatial misalignment caused by image depth estimation errors. Furthermore, the image guidance can effectively help the LiDAR-centric paradigm to address the sparsity and semantic limitations of point clouds. Specifically, we propose a Sparse Voxel Dilation Block that mitigates the inherent point sparsity by densifying foreground voxels through image priors. Moreover, we introduce a Semantic-Guided BEV Dilation Block to enhance the LiDAR feature diffusion processing with image semantic guidance and long-range context capture. On the challenging nuScenes benchmark, BEVDilation achieves better performance than state-of-the-art methods while maintaining competitive computational efficiency. Importantly, our LiDAR-centric strategy demonstrates greater robustness to depth noise compared to naive fusion. The source code is available at this https URL.

29 Nov 2025

We present the first geometric deep learning framework based on point cloud representation for 3D four-chamber cardiac reconstruction from cine MRI data. This work addresses a long-standing limitation in conventional cine MRI, which typically provides only 2D slice images of the heart, thereby restricting a comprehensive understanding of cardiac morphology and physiological mechanisms in both healthy and pathological conditions. To overcome this, we propose \textbf{HeartFormer}, a novel point cloud completion network that extends traditional single-class point cloud completion to the multi-class. HeartFormer consists of two key components: a Semantic-Aware Dual-Structure Transformer Network (SA-DSTNet) and a Semantic-Aware Geometry Feature Refinement Transformer Network (SA-GFRTNet). SA-DSTNet generates an initial coarse point cloud with both global geometry features and substructure geometry features. Guided by these semantic-geometry representations, SA-GFRTNet progressively refines the coarse output, effectively leveraging both global and substructure geometric priors to produce high-fidelity and geometrically consistent reconstructions. We further construct \textbf{HeartCompv1}, the first publicly available large-scale dataset with 17,000 high-resolution 3D multi-class cardiac meshes and point-clouds, to establish a general benchmark for this emerging research direction. Extensive cross-domain experiments on HeartCompv1 and UK Biobank demonstrate that HeartFormer achieves robust, accurate, and generalizable performance, consistently surpassing state-of-the-art (SOTA) methods. Code and dataset will be released upon acceptance at: this https URL.

30 Nov 2025
OmniFD introduces a unified model for face forgery detection, concurrently addressing image and video classification, alongside spatial and temporal localization within a single framework. The model establishes state-of-the-art performance across diverse benchmarks, while reducing parameters by up to 63% and improving inference latency by 48% compared to specialized models.
29 Nov 2025

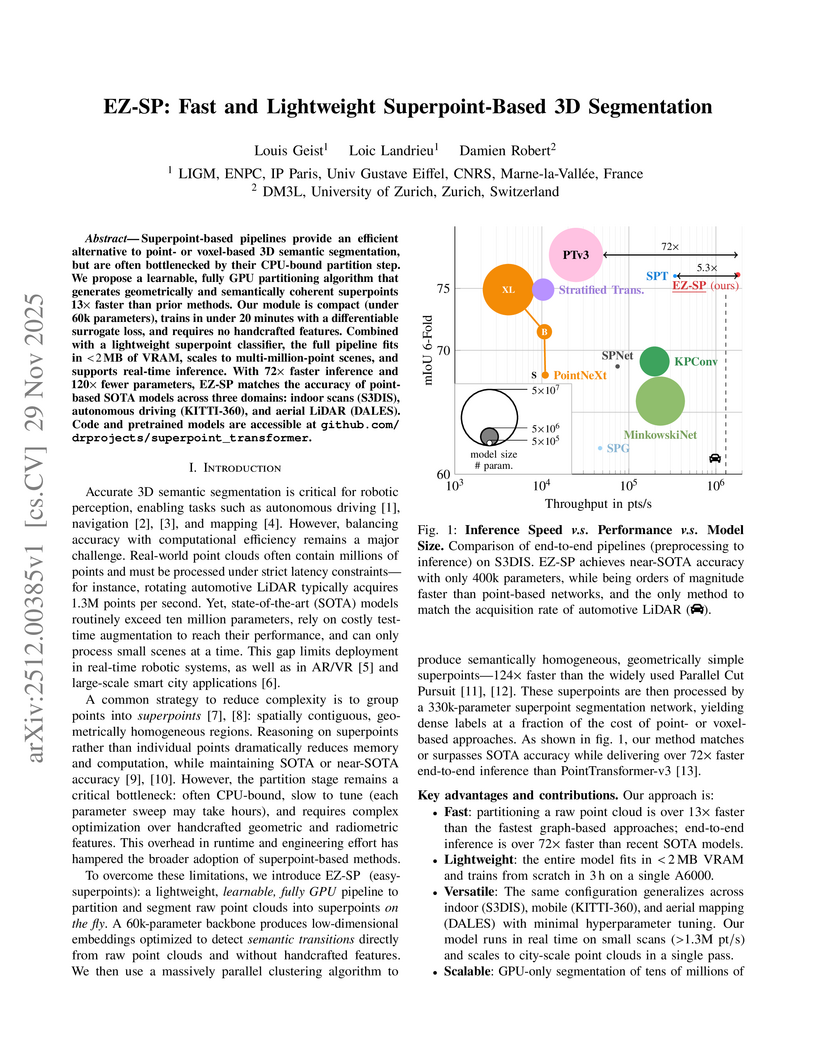
Superpoint-based pipelines provide an efficient alternative to point- or voxel-based 3D semantic segmentation, but are often bottlenecked by their CPU-bound partition step. We propose a learnable, fully GPU partitioning algorithm that generates geometrically and semantically coherent superpoints 13 faster than prior methods. Our module is compact (under 60k parameters), trains in under 20 minutes with a differentiable surrogate loss, and requires no handcrafted features. Combine with a lightweight superpoint classifier, the full pipeline fits in <2 MB of VRAM, scales to multi-million-point scenes, and supports real-time inference. With 72 faster inference and 120 fewer parameters, EZ-SP matches the accuracy of point-based SOTA models across three domains: indoor scans (S3DIS), autonomous driving (KITTI-360), and aerial LiDAR (DALES). Code and pretrained models are accessible at this http URL.

24 Nov 2025



Researchers from KAIST, MIT, and Microsoft developed "Upsample Anything," a training-free framework that efficiently restores low-resolution Vision Foundation Model features to high resolution using a novel Gaussian Splatting Joint Bilateral Upsampling (GSJBU) method. This approach achieves state-of-the-art performance on semantic segmentation and depth estimation benchmarks, operating in 0.419 seconds per 224x224 image, significantly faster than prior test-time optimization methods.
There are no more papers matching your filters at the moment.
