
08 Mar 2012
A wavelet scattering network computes a translation invariant image representation, which is stable to deformations and preserves high frequency information for classification. It cascades wavelet transform convolutions with non-linear modulus and averaging operators. The first network layer outputs SIFT-type descriptors whereas the next layers provide complementary invariant information which improves classification. The mathematical analysis of wavelet scattering networks explains important properties of deep convolution networks for classification.
A scattering representation of stationary processes incorporates higher order moments and can thus discriminate textures having the same Fourier power spectrum. State of the art classification results are obtained for handwritten digits and texture discrimination, using a Gaussian kernel SVM and a generative PCA classifier.

21 Mar 2024

In many application settings, the data have missing entries which make analysis challenging. An abundant literature addresses missing values in an inferential framework: estimating parameters and their variance from incomplete tables. Here, we consider supervised-learning settings: predicting a target when missing values appear in both training and testing data. We show the consistency of two approaches in prediction. A striking result is that the widely-used method of imputing with a constant, such as the mean prior to learning is consistent when missing values are not informative. This contrasts with inferential settings where mean imputation is pointed at for distorting the distribution of the data. That such a simple approach can be consistent is important in practice. We also show that a predictor suited for complete observations can predict optimally on incomplete data, through multiple imputation. Finally, to compare imputation with learning directly with a model that accounts for missing values, we analyze further decision trees. These can naturally tackle empirical risk minimization with missing values, due to their ability to handle the half-discrete nature of incomplete variables. After comparing theoretically and empirically different missing values strategies in trees, we recommend using the "missing incorporated in attribute" method as it can handle both non-informative and informative missing values.

15 Jul 2025

We consider an optimal control problem inspired by neuroscience, where the dynamics is driven by a Poisson process with a controlled stochastic intensity and an uncertain parameter. Given a prior distribution for the unknown parameter, we describe its evolution according to Bayes' rule. We reformulate the optimization problem using Girsanov's theorem and establish a dynamic programming principle. Finally, we characterize the value function as the unique viscosity solution to a finite-dimensional Hamilton-Jacobi-Bellman equation, which can be solved numerically.

18 Feb 2024
Transport maps can ease the sampling of distributions with non-trivial geometries by transforming them into distributions that are easier to handle. The potential of this approach has risen with the development of Normalizing Flows (NF) which are maps parameterized with deep neural networks trained to push a reference distribution towards a target. NF-enhanced samplers recently proposed blend (Markov chain) Monte Carlo methods with either (i) proposal draws from the flow or (ii) a flow-based reparametrization. In both cases, the quality of the learned transport conditions performance. The present work clarifies for the first time the relative strengths and weaknesses of these two approaches. Our study concludes that multimodal targets can be reliably handled with flow-based proposals up to moderately high dimensions. In contrast, methods relying on reparametrization struggle with multimodality but are more robust otherwise in high-dimensional settings and under poor training. To further illustrate the influence of target-proposal adequacy, we also derive a new quantitative bound for the mixing time of the Independent Metropolis-Hastings sampler.

14 Jan 2013

We propose a randomized block-coordinate variant of the classic Frank-Wolfe
algorithm for convex optimization with block-separable constraints. Despite its
lower iteration cost, we show that it achieves a similar convergence rate in
duality gap as the full Frank-Wolfe algorithm. We also show that, when applied
to the dual structural support vector machine (SVM) objective, this yields an
online algorithm that has the same low iteration complexity as primal
stochastic subgradient methods. However, unlike stochastic subgradient methods,
the block-coordinate Frank-Wolfe algorithm allows us to compute the optimal
step-size and yields a computable duality gap guarantee. Our experiments
indicate that this simple algorithm outperforms competing structural SVM
solvers.

13 Nov 2025

We study certificates of positivity for univariate polynomials with rational coefficients that are positive over (an interval of)~, given as weighted sums of squares (SOS) of rational polynomials. We build on the algorithm of Chevillard, Harrison, Joldes, and Lauter~\cite{chml-usos-alg-11}, which we call \usos. For a polynomial of degree~ and coefficient bitsize~, we show that a rational weighted SOS representation can be computed in bit operations, and the certificate has bitsize . This improves the best-known bounds by a factor~ and completes previous analyses. We also extend the method to positivity over arbitrary rational intervals, again saving a factor~. For univariate rational polynomials we further introduce \emph{perturbed SOS certificates}. These consist of a sum of two rational squares approximating the input polynomial so that nonnegativity of the approximation implies that of the original. Their computation has the same bit complexity and certificate size as in the weighted SOS case. We also investigate structural properties of these SOS decompositions. Using the classical fact that any nonnegative univariate real polynomial is a sum of two real squares, we prove that the summands form an interlacing pair. Their real roots correspond to the Karlin points of the original polynomial, linking our construction to the T-systems of Karlin~\cite{Karlin-repr-pos-63}. This enables explicit computation of such decompositions, whereas only existential results were previously known. We obtain analogous results for positivity over and thus over arbitrary real intervals. Finally, we present an open-source Maple implementation of \usos and report experiments on diverse inputs that demonstrate its efficiency.

20 May 2021
Among dissimilarities between probability distributions, the Kernel Stein Discrepancy (KSD) has received much interest recently. We investigate the properties of its Wasserstein gradient flow to approximate a target probability distribution on , known up to a normalization constant. This leads to a straightforwardly implementable, deterministic score-based method to sample from , named KSD Descent, which uses a set of particles to approximate . Remarkably, owing to a tractable loss function, KSD Descent can leverage robust parameter-free optimization schemes such as L-BFGS; this contrasts with other popular particle-based schemes such as the Stein Variational Gradient Descent algorithm. We study the convergence properties of KSD Descent and demonstrate its practical relevance. However, we also highlight failure cases by showing that the algorithm can get stuck in spurious local minima.

10 Oct 2025
We present two methods to obtain local propagation of chaos bounds for diffusive particles in mean field interaction. This extends the recent finding of Lacker [Probab. Math. Phys., 4(2):377-432, 2023] to the case of singular interactions. The first method is based on a hierarchy of relative entropies and Fisher informations, and applies to the 2D viscous vortex model in the high temperature regime. Time-uniform local chaos bounds are also shown in this case. In the second method, we work on a hierarchy of distances and Dirichlet energies, and derive the desired sharp estimates for the same model in short time without restrictions on the temperature.

06 Aug 2018
We present single imputation method for missing values which borrows the idea of data depth---a measure of centrality defined for an arbitrary point of a space with respect to a probability distribution or data cloud. This consists in iterative maximization of the depth of each observation with missing values, and can be employed with any properly defined statistical depth function. For each single iteration, imputation reverts to optimization of quadratic, linear, or quasiconcave functions that are solved analytically by linear programming or the Nelder-Mead method. As it accounts for the underlying data topology, the procedure is distribution free, allows imputation close to the data geometry, can make prediction in situations where local imputation (k-nearest neighbors, random forest) cannot, and has attractive robustness and asymptotic properties under elliptical symmetry. It is shown that a special case---when using the Mahalanobis depth---has direct connection to well-known methods for the multivariate normal model, such as iterated regression and regularized PCA. The methodology is extended to multiple imputation for data stemming from an elliptically symmetric distribution. Simulation and real data studies show good results compared with existing popular alternatives. The method has been implemented as an R-package. Supplementary materials for the article are available online.
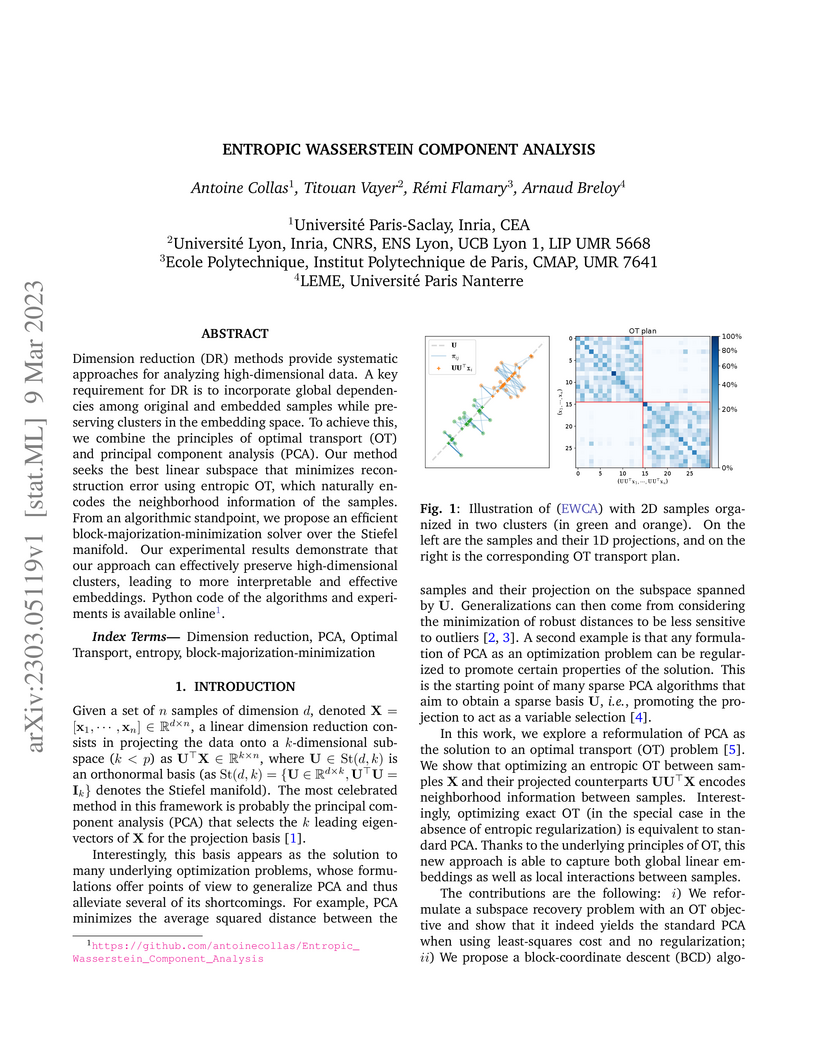
09 Mar 2023

Dimension reduction (DR) methods provide systematic approaches for analyzing high-dimensional data. A key requirement for DR is to incorporate global dependencies among original and embedded samples while preserving clusters in the embedding space. To achieve this, we combine the principles of optimal transport (OT) and principal component analysis (PCA). Our method seeks the best linear subspace that minimizes reconstruction error using entropic OT, which naturally encodes the neighborhood information of the samples. From an algorithmic standpoint, we propose an efficient block-majorization-minimization solver over the Stiefel manifold. Our experimental results demonstrate that our approach can effectively preserve high-dimensional clusters, leading to more interpretable and effective embeddings. Python code of the algorithms and experiments is available online.

06 Oct 2025
The Busemann function has recently found much interest in a variety of geometric machine learning problems, as it naturally defines projections onto geodesic rays of Riemannian manifolds and generalizes the notion of hyperplanes. As several sources of data can be conveniently modeled as probability distributions, it is natural to study this function in the Wasserstein space, which carries a rich formal Riemannian structure induced by Optimal Transport metrics. In this work, we investigate the existence and computation of Busemann functions in Wasserstein space, which admits geodesic rays. We establish closed-form expressions in two important cases: one-dimensional distributions and Gaussian measures. These results enable explicit projection schemes for probability distributions on , which in turn allow us to define novel Sliced-Wasserstein distances over Gaussian mixtures and labeled datasets. We demonstrate the efficiency of those original schemes on synthetic datasets as well as transfer learning problems.

08 Nov 2020
Classical nonlinear random waves can exhibit a process of condensation. It originates in the singularity of the Rayleigh-Jeans equilibrium distribution and it is characterized by the macroscopic population of the fundamental mode of the system. Several recent experiments revealed a phenomenon of spatial beam cleaning of an optical field that propagates through a graded-index multimode optical fiber (MMF). Our aim in this article is to provide physical insight into the mechanism underlying optical beam self-cleaning through the analysis of wave condensation in the presence of structural disorder inherent to MMFs. We consider experiments of beam cleaning where long pulses are injected in the and populate many modes of a 10-20 m MMF, for which the dominant contribution of disorder originates from polarization random fluctuations (weak disorder). On the basis of the wave turbulence theory, we derive nonequilibrium kinetic equations describing the random waves in a regime where disorder dominates nonlinear effects. The theory reveals that the presence of a conservative weak disorder introduces an effective dissipation in the system, which is shown to inhibit wave condensation in the usual continuous wave turbulence approach. On the other hand, the experiments of beam cleaning are described by a discrete wave turbulence approach, where the effective dissipation induced by disorder modifies the regularization of wave resonances, which leads to an acceleration of condensation that can explain the effect of beam self-cleaning. The simulations are in quantitative agreement with the theory. The analysis also reveals that the effect of beam cleaning is characterized by a repolarization as a natural consequence of the condensation process. In addition, the discrete wave turbulence approach explains why optical beam self-cleaning has not been observed in step-index multimode fibers.

08 Jul 2025
A famous result by Hammersley and Versik-Kerov states that the length of the longest increasing subsequence among iid continuous random variables grows like . We investigate here the asymptotic behavior of for distributions with atoms. For purely discrete random variables, we characterize the asymptotic order of through a variational problem and provide explicit estimates for classical distributions. The proofs rely on a coupling with an inhomogeneous version of the discrete-time continuous-space Hammersley process. This reveals that, in contrast to the continuous case, the discrete setting exhibits a wide range of growth rates between and , depending on the tail behavior of the distribution. We can then easily deduce the asymptotics of for a completely arbitrary distribution.

18 Jul 2025
We investigate the properties of positive definite and positive semi-definite symmetric matrices within the framework of symmetrized tropical algebra, an extension of tropical algebra adapted to ordered valued fields.
We focus on the eigenvalues and eigenvectors of these matrices. We
prove that the eigenvalues of a positive (semi)-definite matrix in the tropical symmetrized setting coincide with its diagonal entries. Then, we show that the images by the valuation of the eigenvalues of a positive definite matrix over a valued nonarchimedean ordered field coincide with the eigenvalues of an associated matrix in the symmetrized tropical algebra. Moreover, under a genericity condition, we characterize the images of the eigenvectors under the map keeping track both of the nonarchimedean valuation and sign, showing that they coincide with tropical eigenvectors in the symmetrized algebra. These results offer new insights into the spectral theory of matrices over tropical semirings, and provide combinatorial formulæ for log-limits of eigenvalues and eigenvectors of parametric families of real positive definite matrices.

12 Feb 2024
We investigate the quadratic Schrödinger bridge problem, a.k.a. Entropic Optimal Transport problem, and obtain weak semiconvexity and semiconcavity bounds on Schrödinger potentials under mild assumptions on the marginals that are substantially weaker than log-concavity. We deduce from these estimates that Schrödinger bridges satisfy a logarithmic Sobolev inequality on the product space. Our proof strategy is based on a second order analysis of coupling by reflection on the characteristics of the Hamilton-Jacobi-Bellman equation that reveals the existence of new classes of invariant functions for the corresponding flow.

24 Jul 2025

We study bihomogeneous systems defining, non-zero dimensional, biprojective varieties for which the projection onto the first group of variables results in a finite set of points. To compute (with) the 0-dimensional projection and the corresponding quotient ring, we introduce linear maps that greatly extend the classical multiplication maps for zero-dimensional systems, but are not those associated to the elimination ideal; we also call them multiplication maps. We construct them using linear algebra on the restriction of the ideal to a carefully chosen bidegree or, if available, from an arbitrary Gröbner bases. The multiplication maps allow us to compute the elimination ideal of the projection, by generalizing FGLM algorithm to bihomogenous, non-zero dimensional, varieties. We also study their properties, like their minimal polynomials and the multiplicities of their eigenvalues, and show that we can use the eigenvalues to compute numerical approximations of the zero-dimensional projection. Finally, we establish a single exponential complexity bound for computing multiplication maps and Gröbner bases, that we express in terms of the bidegrees of the generators of the corresponding bihomogeneous ideal.

16 Jun 2025
We consider a transfer operator where two interacting cells carrying non-negative traits transfer a random fraction of their trait to each other. These transfers can lead to population having singular distributions in trait. We extend the definition of the transfer operator to non-negative measures with a finite second moment, and we discuss the regularity of the fixed distributions of that transfer operator. Finally, we consider a dynamic transfer model where an initial population distribution is affected by a transfer operator: we prove the existence and uniqueness of mild measure-valued solutions for that Cauchy problem.

05 Sep 2023
Classical nonlinear waves exhibit, as a general rule, an irreversible process
of thermalization toward the Rayleigh-Jeans equilibrium distribution. On the
other hand, several recent experiments revealed a remarkable effect of spatial
organization of an optical beam that propagates through a graded-index
multimode optical fiber (MMF), a phenomenon termed beam self-cleaning. Our aim
here is to evidence the qualitative impact of disorder (weak random mode
coupling) on the process of Rayleigh-Jeans thermalization by considering two
different experimental configurations. In a first experiment, we launch speckle
beams in a relatively long MMF. Our results report a clear and definite
experimental demonstration of Rayleigh-Jeans thermalization through light
propagation in MMFs, over a broad range of kinetic energy (i.e., degree of
spatial coherence) of the injected speckle beam. In particular, the property of
energy equipartition among the modes is clearly observed in the condensed
regime. The experimental results also evidence the double turbulence cascade
process: while the power flows toward the fundamental mode (inverse cascade),
the energy flows toward the higher-order modes (direct cascade). In a 2nd
experiment, a coherent laser beam is launched into a relatively short MMF
length. It reveals an effect of beam cleaning driven by an incipient process of
Rayleigh-Jeans thermalization. As discussed through numerical simulations, the
fast process of Rayleigh-Jeans thermalization observed in the 1st experiment
can be attributed due to a random phase dynamics among the modes, which is
favoured by the injection of a speckle beam and the increased impact of
disorder in the long fiber system.

20 Jul 2021
We show that the multistage linear problem (MSLP) with an arbitrary cost distribution is equivalent to a MSLP on a finite scenario tree. We establish this exact quantization result by analyzing the polyhedral structure of MSLPs. In particular, we show that the expected cost-to-go functions are polyhedral and affine on the cells of a chamber complex, which is independent of the cost distribution. This leads to new complexity results, showing that MSLP is fixed-parameter tractable.

20 Jun 2025
The convergence of the GMRES linear solver is notoriously hard to predict. A particularly enlightening result by [Greenbaum, Pták, Strakoš, 1996] is that, given any convergence curve, one can build a linear system for which GMRES realizes that convergence curve. What is even more extraordinary is that the eigenvalues of the problem matrix can be chosen arbitrarily. We build upon this idea to derive novel results about weighted GMRES. We prove that for any linear system and any prescribed convergence curve, there exists a weight matrix M for which weighted GMRES (i.e., GMRES in the inner product induced by M) realizes that convergence curve, and we characterize the form of M. Additionally, we exhibit a necessary and sufficient condition on M for the simultaneous prescription of two convergence curves, one realized by GMRES in the Euclidean inner product, and the other in the inner product induced by M. These results are then applied to infer some properties of preconditioned GMRES when the preconditioner is applied either on the left or on the right. For instance, we show that any two convergence curves are simultaneously possible for left and right preconditioned GMRES.
There are no more papers matching your filters at the moment.
