
18 Mar 2020


This survey provides a comprehensive review of Optimal Transport (OT) theory, with a focus on its computational methods and applications in data sciences. It highlights how entropic regularization, particularly through the Sinkhorn-Knopp algorithm, has made OT computationally feasible for large-scale problems, detailing various formulations and their use across machine learning, computer vision, and statistics.

09 Jun 2025

Many applications in machine learning involve data represented as probability
distributions. The emergence of such data requires radically novel techniques
to design tractable gradient flows on probability distributions over this type
of (infinite-dimensional) objects. For instance, being able to flow labeled
datasets is a core task for applications ranging from domain adaptation to
transfer learning or dataset distillation. In this setting, we propose to
represent each class by the associated conditional distribution of features,
and to model the dataset as a mixture distribution supported on these classes
(which are themselves probability distributions), meaning that labeled datasets
can be seen as probability distributions over probability distributions. We
endow this space with a metric structure from optimal transport, namely the
Wasserstein over Wasserstein (WoW) distance, derive a differential structure on
this space, and define WoW gradient flows. The latter enables to design
dynamics over this space that decrease a given objective functional. We apply
our framework to transfer learning and dataset distillation tasks, leveraging
our gradient flow construction as well as novel tractable functionals that take
the form of Maximum Mean Discrepancies with Sliced-Wasserstein based kernels
between probability distributions.

17 Oct 2025
Several emerging post-Bayesian methods target a probability distribution for which an entropy-regularised variational objective is minimised. This increased flexibility introduces a computational challenge, as one loses access to an explicit unnormalised density for the target. To mitigate this difficulty, we introduce a novel measure of suboptimality called 'gradient discrepancy', and in particular a 'kernel' gradient discrepancy (KGD) that can be explicitly computed. In the standard Bayesian context, KGD coincides with the kernel Stein discrepancy (KSD), and we obtain a novel characterisation of KSD as measuring the size of a variational gradient. Outside this familiar setting, KGD enables novel sampling algorithms to be developed and compared, even when unnormalised densities cannot be obtained. To illustrate this point several novel algorithms are proposed and studied, including a natural generalisation of Stein variational gradient descent, with applications to mean-field neural networks and predictively oriented posteriors presented. On the theoretical side, our principal contribution is to establish sufficient conditions for desirable properties of KGD, such as continuity and convergence control.

05 Mar 2025


We present a new algorithm to optimize distributions defined implicitly by
parameterized stochastic diffusions. Doing so allows us to modify the outcome
distribution of sampling processes by optimizing over their parameters. We
introduce a general framework for first-order optimization of these processes,
that performs jointly, in a single loop, optimization and sampling steps. This
approach is inspired by recent advances in bilevel optimization and automatic
implicit differentiation, leveraging the point of view of sampling as
optimization over the space of probability distributions. We provide
theoretical guarantees on the performance of our method, as well as
experimental results demonstrating its effectiveness. We apply it to training
energy-based models and finetuning denoising diffusions.

05 Oct 2025
Effective Uncertainty Quantification (UQ) represents a key aspect for reliable deployment of Large Language Models (LLMs) in automated decision-making and beyond. Yet, for LLM generation with multiple choice structure, the state-of-the-art in UQ is still dominated by the naive baseline given by the maximum softmax score. To address this shortcoming, we demonstrate that taking a principled approach via Bayesian statistics leads to improved performance despite leveraging the simplest possible model, namely linear regression. More precisely, we propose to train multiple Bayesian linear models, each predicting the output of a layer given the output of the previous one. Based on the obtained layer-level posterior distributions, we infer the global uncertainty level of the LLM by identifying a sparse combination of distributional features, leading to an efficient UQ scheme. Numerical experiments on various LLMs show consistent improvement over state-of-the-art baselines.

07 Apr 2025
Geometric tempering is a popular approach to sampling from challenging
multi-modal probability distributions by instead sampling from a sequence of
distributions which interpolate, using the geometric mean, between an easier
proposal distribution and the target distribution. In this paper, we
theoretically investigate the soundness of this approach when the sampling
algorithm is Langevin dynamics, proving both upper and lower bounds. Our upper
bounds are the first analysis in the literature under functional inequalities.
They assert the convergence of tempered Langevin in continuous and
discrete-time, and their minimization leads to closed-form optimal tempering
schedules for some pairs of proposal and target distributions. Our lower bounds
demonstrate a simple case where the geometric tempering takes exponential time,
and further reveal that the geometric tempering can suffer from poor functional
inequalities and slow convergence, even when the target distribution is
well-conditioned. Overall, our results indicate that geometric tempering may
not help, and can even be harmful for convergence.
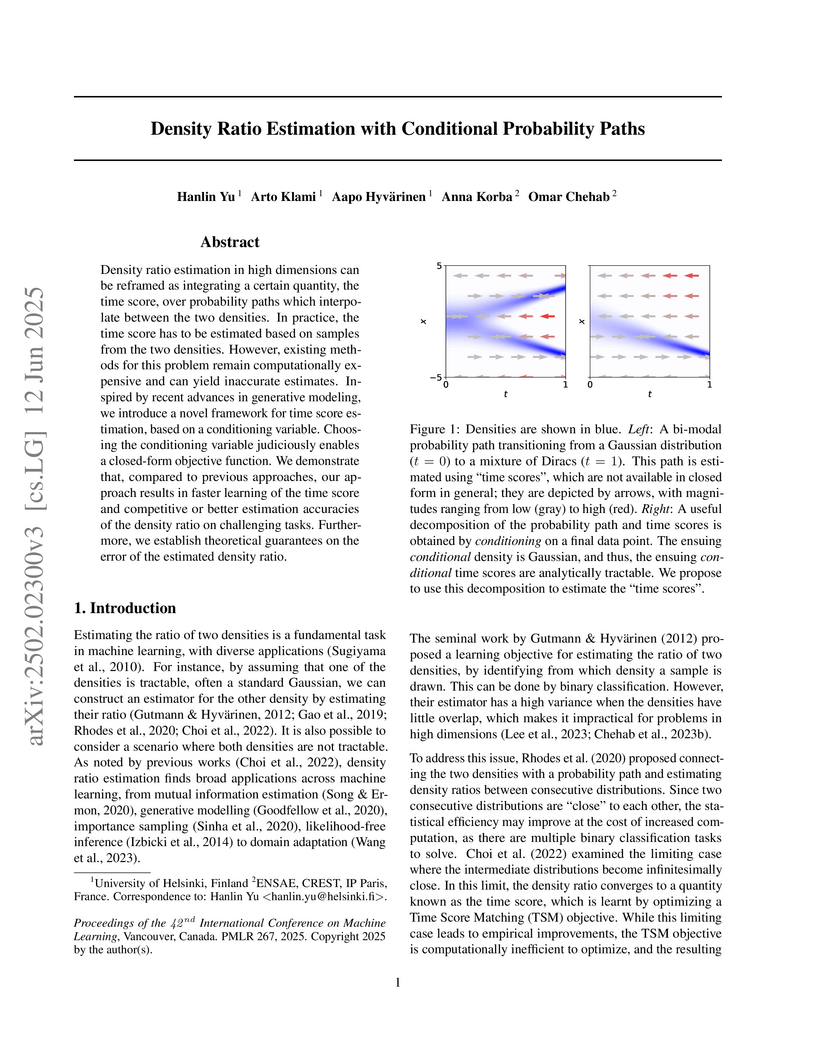
12 Jun 2025
Density ratio estimation in high dimensions can be reframed as integrating a
certain quantity, the time score, over probability paths which interpolate
between the two densities. In practice, the time score has to be estimated
based on samples from the two densities. However, existing methods for this
problem remain computationally expensive and can yield inaccurate estimates.
Inspired by recent advances in generative modeling, we introduce a novel
framework for time score estimation, based on a conditioning variable. Choosing
the conditioning variable judiciously enables a closed-form objective function.
We demonstrate that, compared to previous approaches, our approach results in
faster learning of the time score and competitive or better estimation
accuracies of the density ratio on challenging tasks. Furthermore, we establish
theoretical guarantees on the error of the estimated density ratio.

17 Nov 2025

Variational inference (VI) is a popular approach in Bayesian inference, that looks for the best approximation of the posterior distribution within a parametric family, minimizing a loss that is typically the (reverse) Kullback-Leibler (KL) divergence. In this paper, we focus on the following parametric family: mixtures of isotropic Gaussians (i.e., with diagonal covariance matrices proportional to the identity) and uniform weights. We develop a variational framework and provide efficient algorithms suited for this family. In contrast with mixtures of Gaussian with generic covariance matrices, this choice presents a balance between accurate approximations of multimodal Bayesian posteriors, while being memory and computationally efficient. Our algorithms implement gradient descent on the location of the mixture components (the modes of the Gaussians), and either (an entropic) Mirror or Bures descent on their variance parameters. We illustrate the performance of our algorithms on numerical experiments.

11 Jun 2025
The paper provides a foundational theoretical analysis of Denoising Diffusion Probabilistic Models (DDPMs), proving they achieve an optimal O(sqrt(D)/ε) convergence rate in Wasserstein-2 distance. It also establishes a rigorous explanation for their empirical robustness to noisy score function evaluations, showing that the impact of random perturbations diminishes with more sampling steps.

01 Sep 2025

Researchers from Oxford and CREST developed a gradient-free stochastic optimization algorithm for additive functions, demonstrating it achieves a minimax optimal convergence rate of d T^(-(β-1)/β). Their analysis reveals that the additive structure does not offer substantial accuracy gains in terms of dimension or query dependency compared to general smooth functions, a finding that challenges intuitions from nonparametric estimation.

22 Oct 2025
We study reinforcement learning (RL) with transition look-ahead, where the agent may observe which states would be visited upon playing any sequence of actions before deciding its course of action. While such predictive information can drastically improve the achievable performance, we show that using this information optimally comes at a potentially prohibitive computational cost. Specifically, we prove that optimal planning with one-step look-ahead () can be solved in polynomial time through a novel linear programming formulation. In contrast, for , the problem becomes NP-hard. Our results delineate a precise boundary between tractable and intractable cases for the problem of planning with transition look-ahead in reinforcement learning.

20 Mar 2024

Heart failure (HF) contributes to circa 200,000 annual hospitalizations in
France. With the increasing age of HF patients, elucidating the specific causes
of inpatient mortality became a public health problematic. We introduce a novel
methodological framework designed to identify prevalent health trajectories and
investigate their impact on death. The initial step involves applying
sequential pattern mining to characterize patients' trajectories, followed by
an unsupervised clustering algorithm based on a new metric for measuring the
distance between hospitalization diagnoses. Finally, a survival analysis is
conducted to assess survival outcomes. The application of this framework to HF
patients from a representative sample of the French population demonstrates its
methodological significance in enhancing the analysis of healthcare
trajectories.

18 Sep 2025
The log transformation is widely used in linear regression, mainly because coefficients are interpretable as proportional effects. Yet this practice has fundamental limitations, most notably that the log is undefined at zero, creating an identification problem. We propose a new estimator, iterated OLS (iOLS), which targets the normalized average treatment effect, preserving the percentage-change interpretation while addressing these limitations. Our procedure is the theoretically justified analogue of the ad-hoc log(1+Y) transformation and delivers a consistent and asymptotically normal estimator of the parameters of the exponential conditional mean model. iOLS is computationally efficient, globally convergent, and free of the incidental-parameter bias, while extending naturally to endogenous regressors through iterated 2SLS. We illustrate the methods with simulations and revisit three influential publications.

08 Oct 2024

We obtain upper bounds for the estimation error of Kernel Ridge Regression
(KRR) for all non-negative regularization parameters, offering a geometric
perspective on various phenomena in KRR. As applications: 1. We address the
multiple descent problem, unifying the proofs of arxiv:1908.10292 and
arxiv:1904.12191 for polynomial kernels and we establish multiple descent for
the upper bound of estimation error of KRR under sub-Gaussian design and
non-asymptotic regimes. 2. For a sub-Gaussian design vector and for
non-asymptotic scenario, we prove a one-sided isomorphic version of the
Gaussian Equivalent Conjecture. 3. We offer a novel perspective on the
linearization of kernel matrices of non-linear kernel, extending it to the
power regime for polynomial kernels. 4. Our theory is applicable to
data-dependent kernels, providing a convenient and accurate tool for the
feature learning regime in deep learning theory. 5. Our theory extends the
results in arxiv:2009.14286 under weak moment assumption.
Our proof is based on three mathematical tools developed in this paper that
can be of independent interest: 1. Dvoretzky-Milman theorem for ellipsoids
under (very) weak moment assumptions. 2. Restricted Isomorphic Property in
Reproducing Kernel Hilbert Spaces with embedding index conditions. 3. A
concentration inequality for finite-degree polynomial kernel functions.

08 Apr 2025
In interactive systems, actions are often correlated, presenting an
opportunity for more sample-efficient off-policy evaluation (OPE) and learning
(OPL) in large action spaces. We introduce a unified Bayesian framework to
capture these correlations through structured and informative priors. In this
framework, we propose sDM, a generic Bayesian approach for OPE and OPL,
grounded in both algorithmic and theoretical foundations. Notably, sDM
leverages action correlations without compromising computational efficiency.
Moreover, inspired by online Bayesian bandits, we introduce Bayesian metrics
that assess the average performance of algorithms across multiple problem
instances, deviating from the conventional worst-case assessments. We analyze
sDM in OPE and OPL, highlighting the benefits of leveraging action
correlations. Empirical evidence showcases the strong performance of sDM.

23 Mar 2025
Deep Equilibrium Models (DEQs) are a class of implicit neural networks that
solve for a fixed point of a neural network in their forward pass.
Traditionally, DEQs take sequences as inputs, but have since been applied to a
variety of data. In this work, we present Distributional Deep Equilibrium
Models (DDEQs), extending DEQs to discrete measure inputs, such as sets or
point clouds. We provide a theoretically grounded framework for DDEQs.
Leveraging Wasserstein gradient flows, we show how the forward pass of the DEQ
can be adapted to find fixed points of discrete measures under
permutation-invariance, and derive adequate network architectures for DDEQs. In
experiments, we show that they can compete with state-of-the-art models in
tasks such as point cloud classification and point cloud completion, while
being significantly more parameter-efficient.

02 Apr 2016

A non-parametric extension of control variates is presented. These leverage gradient information on the sampling density to achieve substantial variance reduction. It is not required that the sampling density be normalised. The novel contribution of this work is based on two important insights; (i) a trade-off between random sampling and deterministic approximation and (ii) a new gradient-based function space derived from Stein's identity. Unlike classical control variates, our estimators achieve super-root- convergence, often requiring orders of magnitude fewer simulations to achieve a fixed level of precision. Theoretical and empirical results are presented, the latter focusing on integration problems arising in hierarchical models and models based on non-linear ordinary differential equations.

18 Nov 2024
As the problem of minimizing functionals on the Wasserstein space encompasses
many applications in machine learning, different optimization algorithms on
have received their counterpart analog on the Wasserstein space.
We focus here on lifting two explicit algorithms: mirror descent and
preconditioned gradient descent. These algorithms have been introduced to
better capture the geometry of the function to minimize and are provably
convergent under appropriate (namely relative) smoothness and convexity
conditions. Adapting these notions to the Wasserstein space, we prove
guarantees of convergence of some Wasserstein-gradient-based discrete-time
schemes for new pairings of objective functionals and regularizers. The
difficulty here is to carefully select along which curves the functionals
should be smooth and convex. We illustrate the advantages of adapting the
geometry induced by the regularizer on ill-conditioned optimization tasks, and
showcase the improvement of choosing different discrepancies and geometries in
a computational biology task of aligning single-cells.

24 Oct 2025

Researchers from CREST, ENSAE, IP Paris, LSE, and Seoul National University developed two frameworks, AROQ and SROQ, which dramatically reduce the computational burden of oracle queries in combinatorial semi-bandits from a linear to a (doubly) logarithmic dependence on the time horizon T, while preserving near-optimal regret bounds across various reward models.

01 Mar 2023


Sampling from a target measure whose density is only known up to a normalization constant is a fundamental problem in computational statistics and machine learning. In this paper, we present a new optimization-based method for sampling called mollified interaction energy descent (MIED). MIED minimizes a new class of energies on probability measures called mollified interaction energies (MIEs). These energies rely on mollifier functions -- smooth approximations of the Dirac delta originated from PDE theory. We show that as the mollifier approaches the Dirac delta, the MIE converges to the chi-square divergence with respect to the target measure and the gradient flow of the MIE agrees with that of the chi-square divergence. Optimizing this energy with proper discretization yields a practical first-order particle-based algorithm for sampling in both unconstrained and constrained domains. We show experimentally that for unconstrained sampling problems our algorithm performs on par with existing particle-based algorithms like SVGD, while for constrained sampling problems our method readily incorporates constrained optimization techniques to handle more flexible constraints with strong performance compared to alternatives.
There are no more papers matching your filters at the moment.
