
13 Nov 2018

Despite showing state-of-the-art performance, deep learning for speech
recognition remains challenging to deploy in on-device edge scenarios such as
mobile and other consumer devices. Recently, there have been greater efforts in
the design of small, low-footprint deep neural networks (DNNs) that are more
appropriate for edge devices, with much of the focus on design principles for
hand-crafting efficient network architectures. In this study, we explore a
human-machine collaborative design strategy for building low-footprint DNN
architectures for speech recognition through a marriage of human-driven
principled network design prototyping and machine-driven design exploration.
The efficacy of this design strategy is demonstrated through the design of a
family of highly-efficient DNNs (nicknamed EdgeSpeechNets) for
limited-vocabulary speech recognition. Experimental results using the Google
Speech Commands dataset for limited-vocabulary speech recognition showed that
EdgeSpeechNets have higher accuracies than state-of-the-art DNNs (with the best
EdgeSpeechNet achieving ~97% accuracy), while achieving significantly smaller
network sizes (as much as 7.8x smaller) and lower computational cost (as much
as 36x fewer multiply-add operations, 10x lower prediction latency, and 16x
smaller memory footprint on a Motorola Moto E phone), making them very
well-suited for on-device edge voice interface applications.

03 Apr 2021
A critical step to building trustworthy deep neural networks is trust quantification, where we ask the question: How much can we trust a deep neural network? In this study, we take a step towards simple, interpretable metrics for trust quantification by introducing a suite of metrics for assessing the overall trustworthiness of deep neural networks based on their behaviour when answering a set of questions. We conduct a thought experiment and explore two key questions about trust in relation to confidence: 1) How much trust do we have in actors who give wrong answers with great confidence? and 2) How much trust do we have in actors who give right answers hesitantly? Based on insights gained, we introduce the concept of question-answer trust to quantify trustworthiness of an individual answer based on confident behaviour under correct and incorrect answer scenarios, and the concept of trust density to characterize the distribution of overall trust for an individual answer scenario. We further introduce the concept of trust spectrum for representing overall trust with respect to the spectrum of possible answer scenarios across correctly and incorrectly answered questions. Finally, we introduce NetTrustScore, a scalar metric summarizing overall trustworthiness. The suite of metrics aligns with past social psychology studies that study the relationship between trust and confidence. Leveraging these metrics, we quantify the trustworthiness of several well-known deep neural network architectures for image recognition to get a deeper understanding of where trust breaks down. The proposed metrics are by no means perfect, but the hope is to push the conversation towards better metrics to help guide practitioners and regulators in producing, deploying, and certifying deep learning solutions that can be trusted to operate in real-world, mission-critical scenarios.
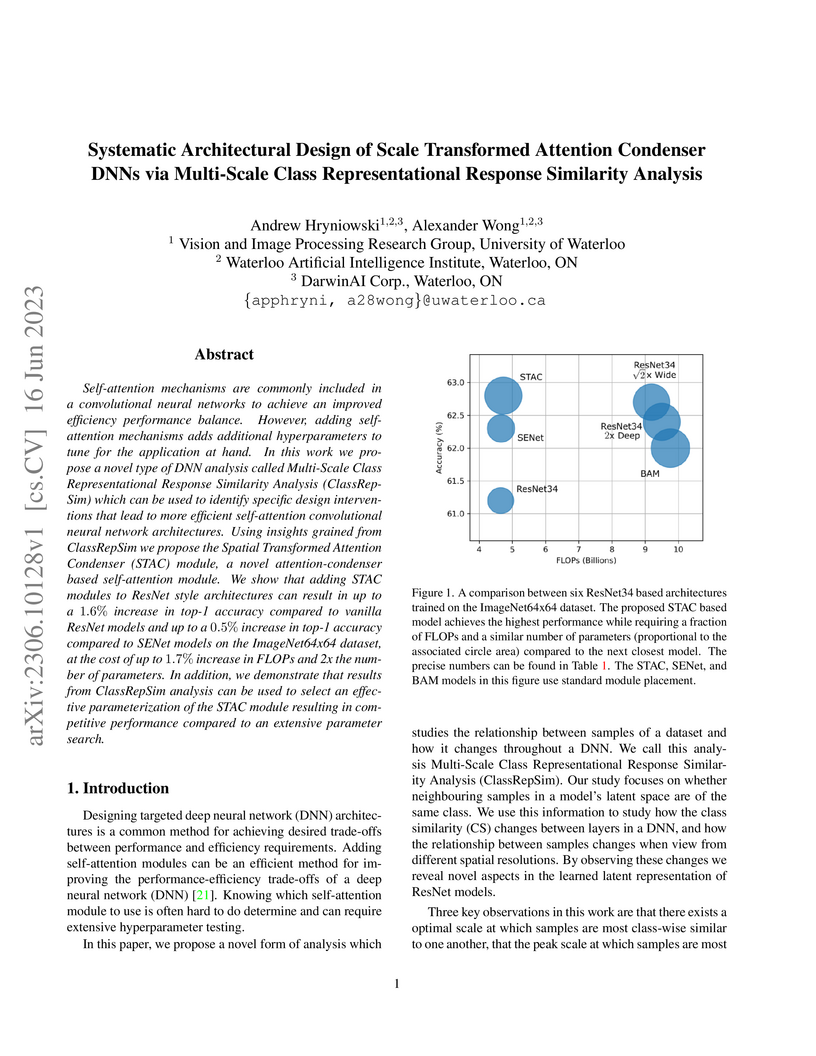
16 Jun 2023
Self-attention mechanisms are commonly included in a convolutional neural networks to achieve an improved efficiency performance balance. However, adding self-attention mechanisms adds additional hyperparameters to tune for the application at hand. In this work we propose a novel type of DNN analysis called Multi-Scale Class Representational Response Similarity Analysis (ClassRepSim) which can be used to identify specific design interventions that lead to more efficient self-attention convolutional neural network architectures. Using insights grained from ClassRepSim we propose the Spatial Transformed Attention Condenser (STAC) module, a novel attention-condenser based self-attention module. We show that adding STAC modules to ResNet style architectures can result in up to a 1.6% increase in top-1 accuracy compared to vanilla ResNet models and up to a 0.5% increase in top-1 accuracy compared to SENet models on the ImageNet64x64 dataset, at the cost of up to 1.7% increase in FLOPs and 2x the number of parameters. In addition, we demonstrate that results from ClassRepSim analysis can be used to select an effective parameterization of the STAC module resulting in competitive performance compared to an extensive parameter search.

26 Jan 2021
The COVID-19 pandemic continues to rage on, with multiple waves causing substantial harm to health and economies around the world. Motivated by the use of CT imaging at clinical institutes around the world as an effective complementary screening method to RT-PCR testing, we introduced COVID-Net CT, a neural network tailored for detection of COVID-19 cases from chest CT images as part of the open source COVID-Net initiative. However, one potential limiting factor is restricted quantity and diversity given the single nation patient cohort used. In this study, we introduce COVID-Net CT-2, enhanced deep neural networks for COVID-19 detection from chest CT images trained on the largest quantity and diversity of multinational patient cases in research literature. We introduce two new CT benchmark datasets, the largest comprising a multinational cohort of 4,501 patients from at least 15 countries. We leverage explainability to investigate the decision-making behaviour of COVID-Net CT-2, with the results for select cases reviewed and reported on by two board-certified radiologists with over 10 and 30 years of experience, respectively. The COVID-Net CT-2 neural networks achieved accuracy, COVID-19 sensitivity, PPV, specificity, and NPV of 98.1%/96.2%/96.7%/99%/98.8% and 97.9%/95.7%/96.4%/98.9%/98.7%, respectively. Explainability-driven performance validation shows that COVID-Net CT-2's decision-making behaviour is consistent with radiologist interpretation by leveraging correct, clinically relevant critical factors. The results are promising and suggest the strong potential of deep neural networks as an effective tool for computer-aided COVID-19 assessment. While not a production-ready solution, we hope the open-source, open-access release of COVID-Net CT-2 and benchmark datasets will continue to enable researchers, clinicians, and citizen data scientists alike to build upon them.

11 Dec 2023

Neural radiance fields (NeRFs) enable high-quality novel view synthesis, but their high computational complexity limits deployability. While existing neural-based solutions strive for efficiency, they use one-size-fits-all architectures regardless of scene complexity. The same architecture may be unnecessarily large for simple scenes but insufficient for complex ones. Thus, there is a need to dynamically optimize the neural network component of NeRFs to achieve a balance between computational complexity and specific targets for synthesis quality. We introduce NAS-NeRF, a generative neural architecture search strategy that generates compact, scene-specialized NeRF architectures by balancing architecture complexity and target synthesis quality metrics. Our method incorporates constraints on target metrics and budgets to guide the search towards architectures tailored for each scene. Experiments on the Blender synthetic dataset show the proposed NAS-NeRF can generate architectures up to 5.74 smaller, with 4.19 fewer FLOPs, and 1.93 faster on a GPU than baseline NeRFs, without suffering a drop in SSIM. Furthermore, we illustrate that NAS-NeRF can also achieve architectures up to 23 smaller, with 22 fewer FLOPs, and 4.7 faster than baseline NeRFs with only a 5.3% average SSIM drop. Our source code is also made publicly available at this https URL.

12 Oct 2020
Advances in deep learning have led to state-of-the-art performance across a
multitude of speech recognition tasks. Nevertheless, the widespread deployment
of deep neural networks for on-device speech recognition remains a challenge,
particularly in edge scenarios where the memory and computing resources are
highly constrained (e.g., low-power embedded devices) or where the memory and
computing budget dedicated to speech recognition is low (e.g., mobile devices
performing numerous tasks besides speech recognition). In this study, we
introduce the concept of attention condensers for building low-footprint,
highly-efficient deep neural networks for on-device speech recognition on the
edge. An attention condenser is a self-attention mechanism that learns and
produces a condensed embedding characterizing joint local and cross-channel
activation relationships, and performs selective attention accordingly. To
illustrate its efficacy, we introduce TinySpeech, low-precision deep neural
networks comprising largely of attention condensers tailored for on-device
speech recognition using a machine-driven design exploration strategy, with one
tailored specifically with microcontroller operation constraints. Experimental
results on the Google Speech Commands benchmark dataset for limited-vocabulary
speech recognition showed that TinySpeech networks achieved significantly lower
architectural complexity (as much as fewer parameters), lower
computational complexity (as much as fewer multiply-add operations),
and lower storage requirements (as much as lower weight memory
requirements) when compared to previous work. These results not only
demonstrate the efficacy of attention condensers for building highly efficient
networks for on-device speech recognition, but also illuminate its potential
for accelerating deep learning on the edge and empowering TinyML applications.

13 Nov 2018
The tremendous potential exhibited by deep learning is often offset by
architectural and computational complexity, making widespread deployment a
challenge for edge scenarios such as mobile and other consumer devices. To
tackle this challenge, we explore the following idea: Can we learn generative
machines to automatically generate deep neural networks with efficient network
architectures? In this study, we introduce the idea of generative synthesis,
which is premised on the intricate interplay between a generator-inquisitor
pair that work in tandem to garner insights and learn to generate highly
efficient deep neural networks that best satisfies operational requirements.
What is most interesting is that, once a generator has been learned through
generative synthesis, it can be used to generate not just one but a large
variety of different, unique highly efficient deep neural networks that satisfy
operational requirements. Experimental results for image classification,
semantic segmentation, and object detection tasks illustrate the efficacy of
generative synthesis in producing generators that automatically generate highly
efficient deep neural networks (which we nickname FermiNets) with higher model
efficiency and lower computational costs (reaching >10x more efficient and
fewer multiply-accumulate operations than several tested state-of-the-art
networks), as well as higher energy efficiency (reaching >4x improvements in
image inferences per joule consumed on a Nvidia Tegra X2 mobile processor). As
such, generative synthesis can be a powerful, generalized approach for
accelerating and improving the building of deep neural networks for on-device
edge scenarios.

03 Nov 2020
The success of deep learning in recent years have led to a significant
increase in interest and prevalence for its adoption to tackle financial
services tasks. One particular question that often arises as a barrier to
adopting deep learning for financial services is whether the developed
financial deep learning models are fair in their predictions, particularly in
light of strong governance and regulatory compliance requirements in the
financial services industry. A fundamental aspect of fairness that has not been
explored in financial deep learning is the concept of trust, whose variations
may point to an egocentric view of fairness and thus provide insights into the
fairness of models. In this study we explore the feasibility and utility of a
multi-scale trust quantification strategy to gain insights into the fairness of
a financial deep learning model, particularly under different scenarios at
different scales. More specifically, we conduct multi-scale trust
quantification on a deep neural network for the purpose of credit card default
prediction to study: 1) the overall trustworthiness of the model 2) the trust
level under all possible prediction-truth relationships, 3) the trust level
across the spectrum of possible predictions, 4) the trust level across
different demographic groups (e.g., age, gender, and education), and 5)
distribution of overall trust for an individual prediction scenario. The
insights for this proof-of-concept study demonstrate that such a multi-scale
trust quantification strategy may be helpful for data scientists and regulators
in financial services as part of the verification and certification of
financial deep learning solutions to gain insights into fairness and trust of
these solutions.

18 Nov 2022
Researchers from the University of Waterloo, DarwinAI, and Moog Inc. developed SolderNet, an explainable AI system for automated solder joint inspection. This system accurately classifies solder joints as defective or non-defective while providing visual explanations for its decisions, aiming to enhance transparency and trustworthiness in electronics manufacturing quality control. The Attend-NeXt Large model achieved 91.1% accuracy with a 5.0% overkill rate and low escape rates (0.6-2.3%).

16 Apr 2021
Background: A critical step in effective care and treatment planning for
severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), the cause of the
COVID-19 pandemic, is the assessment of the severity of disease progression.
Chest x-rays (CXRs) are often used to assess SARS-CoV-2 severity, with two
important assessment metrics being extent of lung involvement and degree of
opacity. In this proof-of-concept study, we assess the feasibility of
computer-aided scoring of CXRs of SARS-CoV-2 lung disease severity using a deep
learning system.
Materials and Methods: Data consisted of 396 CXRs from SARS-CoV-2 positive
patient cases. Geographic extent and opacity extent were scored by two
board-certified expert chest radiologists (with 20+ years of experience) and a
2nd-year radiology resident. The deep neural networks used in this study, which
we name COVID-Net S, are based on a COVID-Net network architecture. 100
versions of the network were independently learned (50 to perform geographic
extent scoring and 50 to perform opacity extent scoring) using random subsets
of CXRs from the study, and we evaluated the networks using stratified Monte
Carlo cross-validation experiments.
Findings: The COVID-Net S deep neural networks yielded R of 0.664
0.032 and 0.635 0.044 between predicted scores and radiologist scores for
geographic extent and opacity extent, respectively, in stratified Monte Carlo
cross-validation experiments. The best performing networks achieved R of
0.739 and 0.741 between predicted scores and radiologist scores for geographic
extent and opacity extent, respectively.
Interpretation: The results are promising and suggest that the use of deep
neural networks on CXRs could be an effective tool for computer-aided
assessment of SARS-CoV-2 lung disease severity, although additional studies are
needed before adoption for routine clinical use.

23 May 2024
The tremendous recent advances in generative artificial intelligence techniques have led to significant successes and promise in a wide range of different applications ranging from conversational agents and textual content generation to voice and visual synthesis. Amid the rise in generative AI and its increasing widespread adoption, there has been significant growing concern over the use of generative AI for malicious purposes. In the realm of visual content synthesis using generative AI, key areas of significant concern has been image forgery (e.g., generation of images containing or derived from copyright content), and data poisoning (i.e., generation of adversarially contaminated images). Motivated to address these key concerns to encourage responsible generative AI, we introduce the DeepfakeArt Challenge, a large-scale challenge benchmark dataset designed specifically to aid in the building of machine learning algorithms for generative AI art forgery and data poisoning detection. Comprising of over 32,000 records across a variety of generative forgery and data poisoning techniques, each entry consists of a pair of images that are either forgeries / adversarially contaminated or not. Each of the generated images in the DeepfakeArt Challenge benchmark dataset \footnote{The link to the dataset: http://anon\_for\this http URL} has been quality checked in a comprehensive manner.

11 May 2019
While deep neural networks extract rich features from the input data, the
current trade-off between depth and computational cost makes it difficult to
adopt deep neural networks for many industrial applications, especially when
computing power is limited. Here, we are inspired by the idea that, while
deeper embeddings are needed to discriminate difficult samples (i.e.,
fine-grained discrimination), a large number of samples can be well
discriminated via much shallower embeddings (i.e., coarse-grained
discrimination). In this study, we introduce the simple yet effective concept
of decision gates (d-gate), modules trained to decide whether a sample needs to
be projected into a deeper embedding or if an early prediction can be made at
the d-gate, thus enabling the computation of dynamic representations at
different depths. The proposed d-gate modules can be integrated with any deep
neural network and reduces the average computational cost of the deep neural
networks while maintaining modeling accuracy. The proposed d-gate framework is
examined via different network architectures and datasets, with experimental
results showing that leveraging the proposed d-gate modules led to a ~43%
speed-up and 44% FLOPs reduction on ResNet-101 and 55% speed-up and 39% FLOPs
reduction on DenseNet-201 trained on the CIFAR10 dataset with only ~2% drop in
accuracy. Furthermore, experiments where d-gate modules are integrated into
ResNet-101 trained on the ImageNet dataset demonstrate that it is possible to
reduce the computational cost of the network by 1.5 GFLOPs without any drop in
the modeling accuracy.

21 Nov 2019
From fully connected neural networks to convolutional neural networks, the learned parameters within a neural network have been primarily relegated to the linear parameters (e.g., convolutional filters). The non-linear functions (e.g., activation functions) have largely remained, with few exceptions in recent years, parameter-less, static throughout training, and seen limited variation in design. Largely ignored by the deep learning community, radial basis function (RBF) networks provide an interesting mechanism for learning more complex non-linear activation functions in addition to the linear parameters in a network. However, the interest in RBF networks has waned over time due to the difficulty of integrating RBFs into more complex deep neural network architectures in a tractable and stable manner. In this work, we present a novel approach that enables end-to-end learning of deep RBF networks with fully learnable activation basis functions in an automatic and tractable manner. We demonstrate that our approach for enabling the use of learnable activation basis functions in deep neural networks, which we will refer to as DeepLABNet, is an effective tool for automated activation function learning within complex network architectures.

26 May 2019
Researchers are actively trying to gain better insights into the
representational properties of convolutional neural networks for guiding better
network designs and for interpreting a network's computational nature. Gaining
such insights can be an arduous task due to the number of parameters in a
network and the complexity of a network's architecture. Current approaches of
neural network interpretation include Bayesian probabilistic interpretations
and information theoretic interpretations. In this study, we take a different
approach to studying convolutional neural networks by proposing an abstract
algebraic interpretation using finite transformation semigroup theory.
Specifically, convolutional layers are broken up and mapped to a finite space.
The state space of the proposed finite transformation semigroup is then defined
as a single element within the convolutional layer, with the acting elements
defined by surrounding state elements combined with convolution kernel
elements. Generators of the finite transformation semigroup are defined to
complete the interpretation. We leverage this approach to analyze the basic
properties of the resulting finite transformation semigroup to gain insights on
the representational properties of convolutional neural networks, including
insights into quantized network representation. Such a finite transformation
semigroup interpretation can also enable better understanding outside of the
confines of fixed lattice data structures, thus useful for handling data that
lie on irregular lattices. Furthermore, the proposed abstract algebraic
interpretation is shown to be viable for interpreting convolutional operations
within a variety of convolutional neural network architectures.

30 Sep 2020
AttendNets: Tiny Deep Image Recognition Neural Networks for the Edge via Visual Attention Condensers
AttendNets: Tiny Deep Image Recognition Neural Networks for the Edge via Visual Attention Condensers
While significant advances in deep learning has resulted in state-of-the-art
performance across a large number of complex visual perception tasks, the
widespread deployment of deep neural networks for TinyML applications involving
on-device, low-power image recognition remains a big challenge given the
complexity of deep neural networks. In this study, we introduce AttendNets,
low-precision, highly compact deep neural networks tailored for on-device image
recognition. More specifically, AttendNets possess deep self-attention
architectures based on visual attention condensers, which extends on the
recently introduced stand-alone attention condensers to improve spatial-channel
selective attention. Furthermore, AttendNets have unique machine-designed
macroarchitecture and microarchitecture designs achieved via a machine-driven
design exploration strategy. Experimental results on ImageNet benchmark
dataset for the task of on-device image recognition showed that AttendNets have
significantly lower architectural and computational complexity when compared to
several deep neural networks in research literature designed for efficiency
while achieving highest accuracies (with the smallest AttendNet achieving
7.2% higher accuracy, while requiring 3 fewer multiply-add
operations, 4.17 fewer parameters, and 16.7 lower
weight memory requirements than MobileNet-V1). Based on these promising
results, AttendNets illustrate the effectiveness of visual attention condensers
as building blocks for enabling various on-device visual perception tasks for
TinyML applications.

08 Sep 2020
The coronavirus disease 2019 (COVID-19) pandemic continues to have a
tremendous impact on patients and healthcare systems around the world. In the
fight against this novel disease, there is a pressing need for rapid and
effective screening tools to identify patients infected with COVID-19, and to
this end CT imaging has been proposed as one of the key screening methods which
may be used as a complement to RT-PCR testing, particularly in situations where
patients undergo routine CT scans for non-COVID-19 related reasons, patients
with worsening respiratory status or developing complications that require
expedited care, and patients suspected to be COVID-19-positive but have
negative RT-PCR test results. Motivated by this, in this study we introduce
COVIDNet-CT, a deep convolutional neural network architecture that is tailored
for detection of COVID-19 cases from chest CT images via a machine-driven
design exploration approach. Additionally, we introduce COVIDx-CT, a benchmark
CT image dataset derived from CT imaging data collected by the China National
Center for Bioinformation comprising 104,009 images across 1,489 patient cases.
Furthermore, in the interest of reliability and transparency, we leverage an
explainability-driven performance validation strategy to investigate the
decision-making behaviour of COVIDNet-CT, and in doing so ensure that
COVIDNet-CT makes predictions based on relevant indicators in CT images. Both
COVIDNet-CT and the COVIDx-CT dataset are available to the general public in an
open-source and open access manner as part of the COVID-Net initiative. While
COVIDNet-CT is not yet a production-ready screening solution, we hope that
releasing the model and dataset will encourage researchers, clinicians, and
citizen data scientists alike to leverage and build upon them.

14 Jun 2023
Explainability plays a crucial role in providing a more comprehensive
understanding of deep learning models' behaviour. This allows for thorough
validation of the model's performance, ensuring that its decisions are based on
relevant visual indicators and not biased toward irrelevant patterns existing
in training data. However, existing methods provide only instance-level
explainability, which requires manual analysis of each sample. Such manual
review is time-consuming and prone to human biases. To address this issue, the
concept of second-order explainable AI (SOXAI) was recently proposed to extend
explainable AI (XAI) from the instance level to the dataset level. SOXAI
automates the analysis of the connections between quantitative explanations and
dataset biases by identifying prevalent concepts. In this work, we explore the
use of this higher-level interpretation of a deep neural network's behaviour to
allows us to "explain the explainability" for actionable insights.
Specifically, we demonstrate for the first time, via example classification and
segmentation cases, that eliminating irrelevant concepts from the training set
based on actionable insights from SOXAI can enhance a model's performance.

24 Sep 2023
Graph Hypernetworks (GHN) can predict the parameters of varying unseen CNN
architectures with surprisingly good accuracy at a fraction of the cost of
iterative optimization. Following these successes, preliminary research has
explored the use of GHNs to predict quantization-robust parameters for 8-bit
and 4-bit quantized CNNs. However, this early work leveraged full-precision
float32 training and only quantized for testing. We explore the impact of
quantization-aware training and/or other quantization-based training strategies
on quantized robustness and performance of GHN predicted parameters for
low-precision CNNs. We show that quantization-aware training can significantly
improve quantized accuracy for GHN predicted parameters of 4-bit quantized CNNs
and even lead to greater-than-random accuracy for 2-bit quantized CNNs. These
promising results open the door for future explorations such as investigating
the use of GHN predicted parameters as initialization for further quantized
training of individual CNNs, further exploration of "extreme bitwidth"
quantization, and mixed precision quantization schemes.

10 Nov 2018
Automated deep neural network architecture design has received a significant amount of recent attention. However, this attention has not been equally shared by one of the fundamental building blocks of a deep neural network, the neurons. In this study, we propose PolyNeuron, a novel automatic neuron discovery approach based on learned polyharmonic spline activations. More specifically, PolyNeuron revolves around learning polyharmonic splines, characterized by a set of control points, that represent the activation functions of the neurons in a deep neural network. A relaxed variant of PolyNeuron, which we term PolyNeuron-R, loosens the constraints imposed by PolyNeuron to reduce the computational complexity for discovering the neuron activation functions in an automated manner. Experiments show both PolyNeuron and PolyNeuron-R lead to networks that have improved or comparable performance on multiple network architectures (LeNet-5 and ResNet-20) using different datasets (MNIST and CIFAR10). As such, automatic neuron discovery approaches such as PolyNeuron is a worthy direction to explore.

01 May 2021
The world is still struggling in controlling and containing the spread of the
COVID-19 pandemic caused by the SARS-CoV-2 virus. The medical conditions
associated with SARS-CoV-2 infections have resulted in a surge in the number of
patients at clinics and hospitals, leading to a significantly increased strain
on healthcare resources. As such, an important part of managing and handling
patients with SARS-CoV-2 infections within the clinical workflow is severity
assessment, which is often conducted with the use of chest x-ray (CXR) images.
In this work, we introduce COVID-Net CXR-S, a convolutional neural network for
predicting the airspace severity of a SARS-CoV-2 positive patient based on a
CXR image of the patient's chest. More specifically, we leveraged transfer
learning to transfer representational knowledge gained from over 16,000 CXR
images from a multinational cohort of over 15,000 patient cases into a custom
network architecture for severity assessment. Experimental results with a
multi-national patient cohort curated by the Radiological Society of North
America (RSNA) RICORD initiative showed that the proposed COVID-Net CXR-S has
potential to be a powerful tool for computer-aided severity assessment of CXR
images of COVID-19 positive patients. Furthermore, radiologist validation on
select cases by two board-certified radiologists with over 10 and 19 years of
experience, respectively, showed consistency between radiologist interpretation
and critical factors leveraged by COVID-Net CXR-S for severity assessment.
While not a production-ready solution, the ultimate goal for the open source
release of COVID-Net CXR-S is to act as a catalyst for clinical scientists,
machine learning researchers, as well as citizen scientists to develop
innovative new clinical decision support solutions for helping clinicians
around the world manage the continuing pandemic.
There are no more papers matching your filters at the moment.
