
22 Oct 2025


Researchers from Google Quantum AI and academic collaborators developed Decoded Quantum Interferometry (DQI), a quantum algorithm that leverages the Quantum Fourier Transform to reduce optimization problems to decoding. DQI demonstrated a superpolynomial speedup for the Optimal Polynomial Intersection problem and showed empirical competitiveness against general classical heuristics for sparse Max-XORSAT.

26 Sep 2024
Google Quantum AI developed "magic state cultivation," a technique that prepares high-fidelity T states for quantum computation by leveraging physical operations within a surface code patch. This approach achieves logical error rates as low as 2710chci9 with 10chci3 physical noise, requiring an order of magnitude fewer qubit-rounds than prior methods.

21 May 2025
This work by Craig Gidney at Google Quantum AI demonstrates that a 2048-bit RSA integer could be factored using less than a million noisy physical qubits and in under a week, representing a 20-fold reduction in estimated qubit count compared to prior analyses. It achieves these resource estimates by integrating recent algorithmic advancements, such as optimized approximate modular arithmetic and Ekerå-Håstad period finding, with efficient fault-tolerance techniques like yoked surface codes and magic state cultivation.

05 Dec 2025
The promise of fault-tolerant quantum computing is challenged by environmental drift that relentlessly degrades the quality of quantum operations. The contemporary solution, halting the entire quantum computation for recalibration, is unsustainable for the long runtimes of the future algorithms. We address this challenge by unifying calibration with computation, granting the quantum error correction process a dual role: its error detection events are not only used to correct the logical quantum state, but are also repurposed as a learning signal, teaching a reinforcement learning agent to continuously steer the physical control parameters and stabilize the quantum system during the computation. We experimentally demonstrate this framework on a superconducting processor, improving the logical error rate stability of the surface code 3.5-fold against injected drift and pushing the performance beyond what is achievable with state-of-the-art traditional calibration and human-expert tuning. Simulations of surface codes up to distance-15 confirm the scalability of our method, revealing an optimization speed that is independent of the system size. This work thus enables a new paradigm: a quantum computer that learns to self-improve directly from its errors and never stops computing.

13 Aug 2025

The quest to identify quantum advantages lies at the heart of quantum technology. While quantum devices promise extraordinary capabilities, from exponential computational speedups to unprecedented measurement precision, distinguishing genuine advantages from mere illusions remains a formidable challenge. In this endeavor, quantum theorists are like prophets attempting to foretell the future, yet the boundary between visionary insight and unfounded fantasy is perilously thin. In this perspective, we examine our mathematical tools for navigating the vast world of quantum advantages across computation, learning, sensing, and communication. We explore five keystone properties: predictability, typicality, robustness, verifiability, and usefulness that define an ideal quantum advantage, and envision what new quantum advantages could arise in a future with ubiquitous quantum technology. We prove that some quantum advantages are inherently unpredictable using classical resources alone, suggesting a landscape far richer than what we can currently foresee. While mathematical rigor remains our indispensable guide, the ultimate power of quantum technologies may emerge from advantages we cannot yet conceive.

08 Oct 2025


Prior work of Beverland et al. has shown that any exact Clifford+ implementation of the -qubit Toffoli gate must use at least gates. Here we show how to get away with exponentially fewer gates, at the cost of incurring a tiny error that can be neglected in most practical situations. More precisely, the -qubit Toffoli gate can be implemented to within error in the diamond distance by a randomly chosen Clifford+ circuit with at most gates. We also give a matching lower bound that establishes optimality, and we show that any purely unitary implementation achieving even constant error must use gates. We also extend our sampling technique to implement other Boolean functions. Finally, we describe upper and lower bounds on the -count of Boolean functions in terms of non-adaptive parity decision tree complexity and its randomized analogue.

22 Oct 2025
This research note defines a simplified version of the quantum OTOC problem, derived from a recent Google Quantum AI experiment, presenting a function computation task efficiently solvable by quantum computers but conjectured to be classically intractable on average. The work aims to provide a verifiable benchmark for quantum advantage demonstrations and stimulate further theoretical analysis.

11 May 2025
In the rapidly evolving field of quantum computing, tensor networks serve as
an important tool due to their multifaceted utility. In this paper, we review
the diverse applications of tensor networks and show that they are an important
instrument for quantum computing. Specifically, we summarize the application of
tensor networks in various domains of quantum computing, including simulation
of quantum computation, quantum circuit synthesis, quantum error correction and
mitigation, and quantum machine learning. Finally, we provide an outlook on the
opportunities and the challenges of the tensor-network techniques.

12 Sep 2025
We present a quantum algorithm for simulating the time evolution generated by any bounded, time-dependent operator with non-positive logarithmic norm, thereby serving as a natural generalization of the Hamiltonian simulation problem. Our method generalizes the recent Linear-Combination-of-Hamiltonian-Simulation (LCHS) framework. In instances where is time-independent, we provide a block-encoding of the evolution operator with queries to the block-encoding oracle for . We also show how the normalized evolved state can be prepared with queries to the oracle that prepares the normalized initial state . These complexities are optimal in all parameters and improve the error scaling over prior results. Furthermore, we show that any improvement of our approach exceeding a constant factor of approximately 3 is infeasible. For general time-dependent operators , we also prove that a uniform trapezoidal rule on our LCHS construction yields exponential convergence, leading to simplified quantum circuits with improved gate complexity compared to prior nonuniform-quadrature methods.

24 Aug 2024

Google Quantum AI demonstrates a surface code quantum memory operating below the threshold, achieving exponential suppression of logical errors by a factor of 2.14±0.02 when increasing code distance from d=5 to d=7, and extending logical qubit lifetime beyond that of physical qubits.

29 Sep 2025

The operator wavefunction provides a fine-grained description of quantum chaos and of the irreversible growth of simple operators into increasingly complex ones. Remarkably, at finite temperature this wavefunction can acquire a phase that increases linearly with the size of operator, a phenomenon called . Although size winding occurs naturally in a holographic setting, the emergence of a coherent phase in a scrambled operator remains mysterious from the standpoint of a thermalizing quantum many-body system. In this work, we elucidate this phenomenon by introducing the related concept of , whereby the operator wavefunction has a phase which winds linearly with the Krylov index. We argue that Krylov winding is a generic feature of quantum chaotic systems. It gives rise to size winding under two additional conditions: (i) a low-rank mapping between the Krylov and size bases, which ensures phase alignment among operators of the same size, and (ii) the saturation of the ``chaos-operator growth'' bound (with the Lyapunov exponent and the growth rate), which ensures a linear phase dependence on size. For systems which do not saturate this bound, with h = \lambda_L / 2\alpha <1, the winding with Pauli size becomes , behaving as . We illustrate these results with two microscopic models: the Sachdev-Ye-Kitaev (SYK) model and a disordered -local spin model.

21 Oct 2025

We present two new types of syndrome extraction circuits for the color code. Our first construction, which after [M. McEwen, D. Bacon, and C. Gidney, Quantum 7, 1172 (2023)] we call the semi-wiggling color code, promises to mitigate leakage errors by periodically interchanging the roles of bulk data and measurement qubits. The second construction reduces circuit depth relative to [C. Gidney and C. Jones, arXiv:2312.08813 (2023)] by employing the CXSWAP gate instead of CNOT. This optimization leads to improvement in teraquop footprint under the uniform error model with the physical error rate .

14 Sep 2023
Google Quantum AI researchers developed a method to re-engineer surface code circuits by leveraging time-dynamic "detecting regions," enabling implementations on lower-connectivity hardware, with alternative native gate sets, and with inherent leakage mitigation. This approach achieves comparable logical performance to standard surface code circuits while relaxing stringent hardware demands.
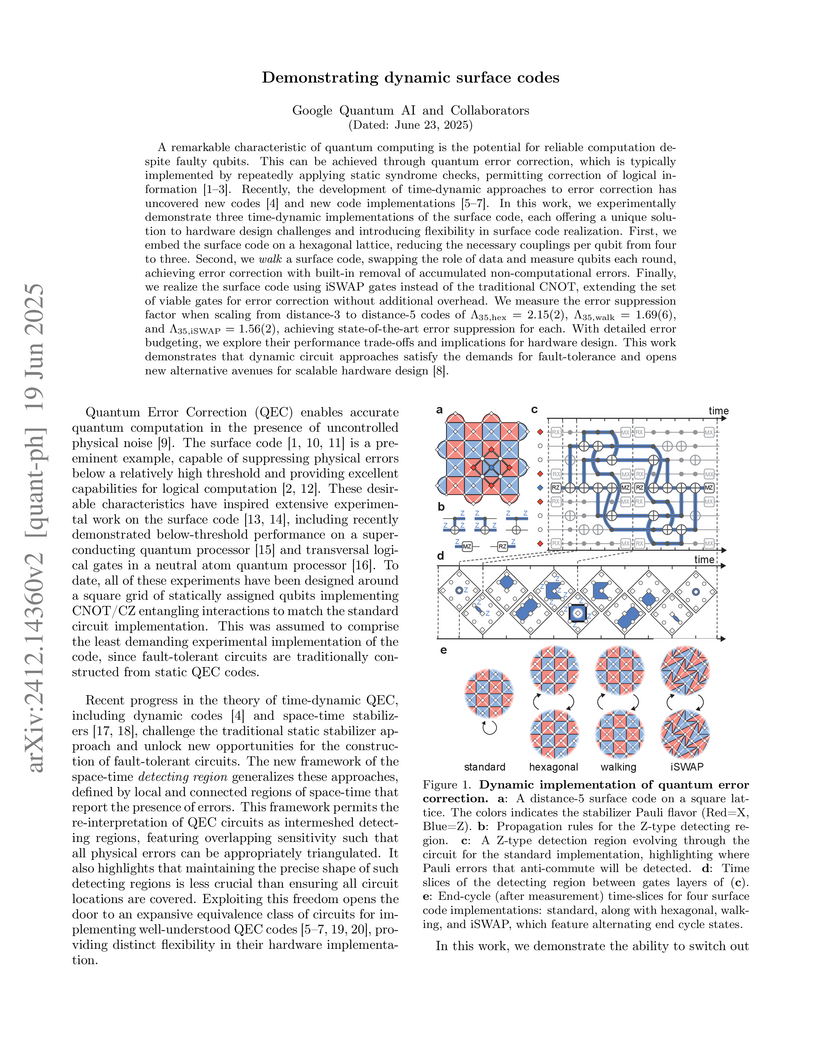
19 Jun 2025
Scientists at Google Quantum AI experimentally demonstrated three time-dynamic surface code implementations—hexagonal, walking, and iSWAP—each achieving error suppression with increasing code distance. These implementations address critical hardware challenges by relaxing qubit connectivity requirements, intrinsically mitigating non-computational errors like leakage, and expanding the viable set of entangling gates for quantum error correction.

18 Sep 2025



Decoherence errors arising from noisy environments remain a central obstacle to progress in quantum computation and information processing. Quantum error correction (QEC) based on the Gottesman-Kitaev-Preskill (GKP) protocol offers a powerful strategy to overcome this challenge, with successful demonstrations in trapped ions, superconducting circuits, and photonics. Beyond active QEC, a compelling alternative is to engineer Hamiltonians that intrinsically enforce stabilizers, offering passive protection akin to topological models. Inspired by the GKP encoding scheme, we implement a superconducting qubit whose eigenstates form protected grid states - long envisioned but not previously realized - by integrating an effective Cooper-quartet junction with a quantum phase-slip element embedded in a high-impedance circuit. Spectroscopic measurements reveal pairs of degenerate states separated by large energy gaps, in excellent agreement with theoretical predictions. Remarkably, our observations indicate that the circuit tolerates small disorders and gains robustness against environmental noise as its parameters approach the ideal regime, establishing a new framework for exploring superconducting hardware. These findings also showcase the versatility of the superconducting circuit toolbox, setting the stage for future exploration of advanced solid-state devices with emergent properties.

09 Oct 2025
The nature of randomness and complexity growth in systems governed by unitary dynamics is a fundamental question in quantum many-body physics. This problem has motivated the study of models such as local random circuits and their convergence to Haar-random unitaries in the long-time limit. However, these models do not correspond to any family of physical time-independent Hamiltonians. In this work, we address this gap by studying the indistinguishability of time-independent Hamiltonian dynamics from truly random unitaries. On one hand, we establish a no-go result showing that for any ensemble of constant-local Hamiltonians and any evolution times, the resulting time-evolution unitary can be efficiently distinguished from Haar-random and fails to form a -design or a pseudorandom unitary (PRU). On the other hand, we prove that this limitation can be overcome by increasing the locality slightly: there exist ensembles of random polylog-local Hamiltonians in one-dimension such that under constant evolution time, the resulting time-evolution unitary is indistinguishable from Haar-random, i.e. it forms both a unitary -design and a PRU. Moreover, these Hamiltonians can be efficiently simulated under standard cryptographic assumptions.

21 Oct 2025
This research investigates the evolution of quantum complexity for subsystems within chaotic quantum systems, modeled by random unitary circuits. The study establishes rigorous bounds for complexity growth in both large and small subsystems and provides evidence for a discontinuous collapse of complexity for small subsystems upon thermalization.

14 Jan 2025

In this work, we introduce a fast implementation of the minimum-weight
perfect matching (MWPM) decoder, the most widely used decoder for several
important families of quantum error correcting codes, including surface codes.
Our algorithm, which we call sparse blossom, is a variant of the blossom
algorithm which directly solves the decoding problem relevant to quantum error
correction. Sparse blossom avoids the need for all-to-all Dijkstra searches,
common amongst MWPM decoder implementations. For 0.1% circuit-level
depolarising noise, sparse blossom processes syndrome data in both and
bases of distance-17 surface code circuits in less than one microsecond per
round of syndrome extraction on a single core, which matches the rate at which
syndrome data is generated by superconducting quantum computers. Our
implementation is open-source, and has been released in version 2 of the
PyMatching library.

13 Oct 2025
Decoded Quantum Interferometry (DQI) provides a framework for superpolynomial quantum speedups by reducing certain optimization problems to reversible decoding tasks. We apply DQI to the Optimal Polynomial Intersection (OPI) problem, whose dual code is Reed-Solomon (RS). We establish that DQI for OPI is the first known candidate for verifiable quantum advantage with optimal asymptotic speedup: solving instances with classical hardness requires only quantum gates, matching the theoretical lower bound. Realizing this speedup requires highly efficient reversible RS decoders. We introduce novel quantum circuits for the Extended Euclidean Algorithm, the decoder's bottleneck. Our techniques, including a new representation for implicit Bézout coefficient access, and optimized in-place architectures, reduce the leading-order space complexity to the theoretical minimum of qubits while significantly lowering gate counts. These improvements are broadly applicable, including to Shor's algorithm for the discrete logarithm. We analyze OPI over binary extension fields , assess hardness against new classical attacks, and identify resilient instances. Our resource estimates show that classically intractable OPI instances (requiring classical trials) can be solved with approximately 5.72 million Toffoli gates. This is substantially less than the count required for breaking RSA-2048, positioning DQI as a compelling candidate for practical, verifiable quantum advantage.

30 Sep 2025
We present a simple algorithm that implements an arbitrary -qubit unitary operator using a Clifford+T circuit with T-count . This improves upon the previous best known upper bound of , while the best known lower bound remains . Our construction is based on a recursive application of the cosine-sine decomposition, together with a generalization of the optimal diagonal unitary synthesis method by Gosset, Kothari, and Wu to multi-controlled -qubit unitaries.
There are no more papers matching your filters at the moment.
