
07 Dec 2025
The challenge of \textbf{imbalanced regression} arises when standard Empirical Risk Minimization (ERM) biases models toward high-frequency regions of the data distribution, causing severe degradation on rare but high-impact ``tail'' events. Existing strategies uch as loss re-weighting or synthetic over-sampling often introduce noise, distort the underlying distribution, or add substantial algorithmic complexity.
We introduce \textbf{PARIS} (Pruning Algorithm via the Representer theorem for Imbalanced Scenarios), a principled framework that mitigates imbalance by \emph{optimizing the training set itself}. PARIS leverages the representer theorem for neural networks to compute a \textbf{closed-form representer deletion residual}, which quantifies the exact change in validation loss caused by removing a single training point \emph{without retraining}. Combined with an efficient Cholesky rank-one downdating scheme, PARIS performs fast, iterative pruning that eliminates uninformative or performance-degrading samples.
We use a real-world space weather example, where PARIS reduces the training set by up to 75\% while preserving or improving overall RMSE, outperforming re-weighting, synthetic oversampling, and boosting baselines. Our results demonstrate that representer-guided dataset pruning is a powerful, interpretable, and computationally efficient approach to rare-event regression.

10 Dec 2025
Biological neural networks learn complex behaviors from sparse, delayed feedback using local synaptic plasticity, yet the mechanisms enabling structured credit assignment remain elusive. In contrast, artificial recurrent networks solving similar tasks typically rely on biologically implausible global learning rules or hand-crafted local updates. The space of local plasticity rules capable of supporting learning from delayed reinforcement remains largely unexplored. Here, we present a meta-learning framework that discovers local learning rules for structured credit assignment in recurrent networks trained with sparse feedback. Our approach interleaves local neo-Hebbian-like updates during task execution with an outer loop that optimizes plasticity parameters via \textbf{tangent-propagation through learning}. The resulting three-factor learning rules enable long-timescale credit assignment using only local information and delayed rewards, offering new insights into biologically grounded mechanisms for learning in recurrent circuits.

08 Dec 2025
The 2025 Nobel Prize in Chemistry for Metal-Organic Frameworks (MOFs) and recent breakthroughs by Huanting Wang's team at Monash University establish angstrom-scale channels as promising post-silicon substrates with native integrate-and-fire (IF) dynamics. However, utilizing these stochastic, analog materials for deterministic, bit-exact AI workloads (e.g., FP8) remains a paradox. Existing neuromorphic methods often settle for approximation, failing Transformer precision standards. To traverse the gap "from stochastic ions to deterministic floats," we propose a Native Spiking Microarchitecture. Treating noisy neurons as logic primitives, we introduce a Spatial Combinational Pipeline and a Sticky-Extra Correction mechanism. Validation across all 16,129 FP8 pairs confirms 100% bit-exact alignment with PyTorch. Crucially, our architecture reduces Linear layer latency to O(log N), yielding a 17x speedup. Physical simulations further demonstrate robustness against extreme membrane leakage (beta approx 0.01), effectively immunizing the system against the stochastic nature of the hardware.

10 Dec 2025
Neural decoding, a critical component of Brain-Computer Interface (BCI), has recently attracted increasing research interest. Previous research has focused on leveraging signal processing and deep learning methods to enhance neural decoding performance. However, the in-depth exploration of model architectures remains underexplored, despite its proven effectiveness in other tasks such as energy forecasting and image classification. In this study, we propose NeuroSketch, an effective framework for neural decoding via systematic architecture optimization. Starting with the basic architecture study, we find that CNN-2D outperforms other architectures in neural decoding tasks and explore its effectiveness from temporal and spatial perspectives. Building on this, we optimize the architecture from macro- to micro-level, achieving improvements in performance at each step. The exploration process and model validations take over 5,000 experiments spanning three distinct modalities (visual, auditory, and speech), three types of brain signals (EEG, SEEG, and ECoG), and eight diverse decoding tasks. Experimental results indicate that NeuroSketch achieves state-of-the-art (SOTA) performance across all evaluated datasets, positioning it as a powerful tool for neural decoding. Our code and scripts are available at this https URL.
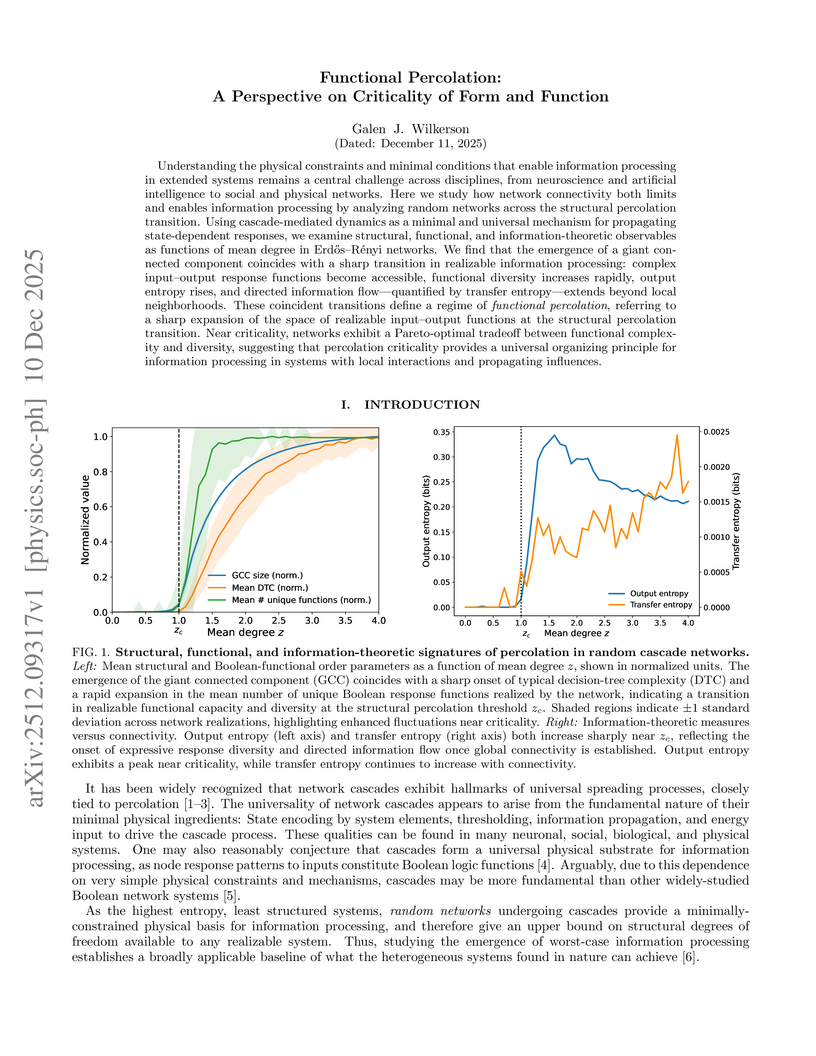
10 Dec 2025
Understanding the physical constraints and minimal conditions that enable information processing in extended systems remains a central challenge across disciplines, from neuroscience and artificial intelligence to social and physical networks. Here we study how network connectivity both limits and enables information processing by analyzing random networks across the structural percolation transition. Using cascade-mediated dynamics as a minimal and universal mechanism for propagating state-dependent responses, we examine structural, functional, and information-theoretic observables as functions of mean degree in Erdos-Renyi networks. We find that the emergence of a giant connected component coincides with a sharp transition in realizable information processing: complex input-output response functions become accessible, functional diversity increases rapidly, output entropy rises, and directed information flow quantified by transfer entropy extends beyond local neighborhoods. These coincident transitions define a regime of functional percolation, referring to a sharp expansion of the space of realizable input-output functions at the structural percolation transition. Near criticality, networks exhibit a Pareto-optimal tradeoff between functional complexity and diversity, suggesting that percolation criticality provides a universal organizing principle for information processing in systems with local interactions and propagating influences.

07 Dec 2025
We present a novel approach to EEG decoding for non-invasive brain machine interfaces (BMIs), with a focus on motor-behavior classification. While conventional convolutional architectures such as EEGNet and DeepConvNet are effective in capturing local spatial patterns, they are markedly less suited for modeling long-range temporal dependencies and nonlinear dynamics. To address this limitation, we integrate an Echo State Network (ESN), a prominent paradigm in reservoir computing into the decoding pipeline. ESNs construct a high-dimensional, sparsely connected recurrent reservoir that excels at tracking temporal dynamics, thereby complementing the spatial representational power of CNNs. Evaluated on a skateboard-trick EEG dataset preprocessed via the PREP pipeline and implemented in MNE-Python, our ESNNet achieves 83.2% within-subject and 51.3% LOSO accuracies, surpassing widely used CNN-based baselines. Code is available at this https URL

05 Dec 2025
Modern high-frequency trading (HFT) environments are characterized by sudden price spikes that present both risk and opportunity, but conventional financial models often fail to capture the required fine temporal structure. Spiking Neural Networks (SNNs) offer a biologically inspired framework well-suited to these challenges due to their natural ability to process discrete events and preserve millisecond-scale timing. This work investigates the application of SNNs to high-frequency price-spike forecasting, enhancing performance via robust hyperparameter tuning with Bayesian Optimization (BO). This work converts high-frequency stock data into spike trains and evaluates three architectures: an established unsupervised STDP-trained SNN, a novel SNN with explicit inhibitory competition, and a supervised backpropagation network. BO was driven by a novel objective, Penalized Spike Accuracy (PSA), designed to ensure a network's predicted price spike rate aligns with the empirical rate of price events. Simulated trading demonstrated that models optimized with PSA consistently outperformed their Spike Accuracy (SA)-tuned counterparts and baselines. Specifically, the extended SNN model with PSA achieved the highest cumulative return (76.8%) in simple backtesting, significantly surpassing the supervised alternative (42.54% return). These results validate the potential of spiking networks, when robustly tuned with task-specific objectives, for effective price spike forecasting in HFT.

05 Dec 2025
Researchers from the National University of Singapore and Indian Institute of Technology established the first unified theoretical framework for Sparse Dictionary Learning (SDL) methods in mechanistic interpretability. This work formalizes how SDL recovers interpretable features and offers the first theoretical explanations for observed phenomena like feature absorption and dead neurons in neural network representations.

28 Nov 2025
Researchers from TU Dresden and MIT developed fastDSA, a computationally optimized version of Dynamical Similarity Analysis (DSA), achieving up to 100 times faster computation while preserving the method's accuracy and sensitivity to subtle dynamic changes. This enhanced framework robustly distinguishes between systems with identical eigenvalues but distinct flow fields, enabling large-scale comparative studies of neural and artificial dynamics.

04 Dec 2025
We develop a general theory of semantic dynamics for large language models by formalizing them as Continuous State Machines (CSMs): smooth dynamical systems whose latent manifolds evolve under probabilistic transition operators. The associated transfer operator encodes the propagation of semantic mass. Under mild regularity assumptions (compactness, ergodicity, bounded Jacobian), is compact with discrete spectrum. Within this setting, we prove the Semantic Characterization Theorem (SCT): the leading eigenfunctions of induce finitely many spectral basins of invariant meaning, each definable in an o-minimal structure over . Thus spectral lumpability and logical tameness coincide. This explains how discrete symbolic semantics can emerge from continuous computation: the continuous activation manifold collapses into a finite, logically interpretable ontology. We further extend the SCT to stochastic and adiabatic (time-inhomogeneous) settings, showing that slowly drifting kernels preserve compactness, spectral coherence, and basin structure.

24 Nov 2025



A conceptual framework is introduced for understanding deep language comprehension in the human brain, positing that a specialized core language system exports information to other functionally distinct cognitive modules to construct rich mental models. This neurocognitive model informs the development of advanced artificial intelligence by suggesting analogous modular architectures are needed for truly grounded AI understanding.

28 Nov 2025
A collaborative effort from Stanford, University of Wisconsin–Madison, and University at Buffalo researchers introduces a constructive framework for building Multi-Layer Perceptrons that efficiently store factual knowledge as key-value mappings for Transformer architectures. The proposed method achieves asymptotically optimal parameter efficiency and facilitates a modular approach to fact editing, demonstrably outperforming current state-of-the-art techniques.

02 Dec 2025
Shogo Ohmae and Keiko Ohmae's perspective identifies predictive and generative world models as a common computational foundation underlying diverse functions in the neocortex, cerebellum, and modern attention-based AI systems. Their analysis reveals a shared principle where these models, acquired through prediction-error learning, are repurposed for prediction, understanding, and generation across various domains.

01 Dec 2025
We present Conformer-based decoders for the LibriBrain 2025 PNPL competition, targeting two foundational MEG tasks: Speech Detection and Phoneme Classification. Our approach adapts a compact Conformer to raw 306-channel MEG signals, with a lightweight convolutional projection layer and task-specific heads. For Speech Detection, a MEG-oriented SpecAugment provided a first exploration of MEG-specific augmentation. For Phoneme Classification, we used inverse-square-root class weighting and a dynamic grouping loader to handle 100-sample averaged examples. In addition, a simple instance-level normalization proved critical to mitigate distribution shifts on the holdout split. Using the official Standard track splits and F1-macro for model selection, our best systems achieved 88.9% (Speech) and 65.8% (Phoneme) on the leaderboard, surpassing the competition baselines and ranking within the top-10 in both tasks. For further implementation details, the technical documentation, source code, and checkpoints are available at this https URL.

22 Nov 2025
In order to predict the next token, LLMs must represent semantic and surface-level information about the current word. Previous work identified two types of attention heads that disentangle this information: (i) Concept induction heads, which copy word meanings, and (ii) Token induction heads, which copy literal token representations (Feucht et al., 2025). We show that these heads can be used to identify subspaces of model activations that exhibit coherent semantic structure in Llama-2-7b. Specifically, when we transform hidden states using the attention weights of concept heads, we are able to more accurately perform parallelogram arithmetic (Mikolov et al., 2013) on the resulting hidden states, e.g., showing that "Athens" - "Greece" + "China" = "Beijing". This transformation allows for much higher nearest-neighbor accuracy (80%) than direct use of raw hidden states (47%). Analogously, we show that token heads allow for transformations that reveal surface-level word information in hidden states, allowing for operations like "coding" - "code" + "dance" = "dancing".
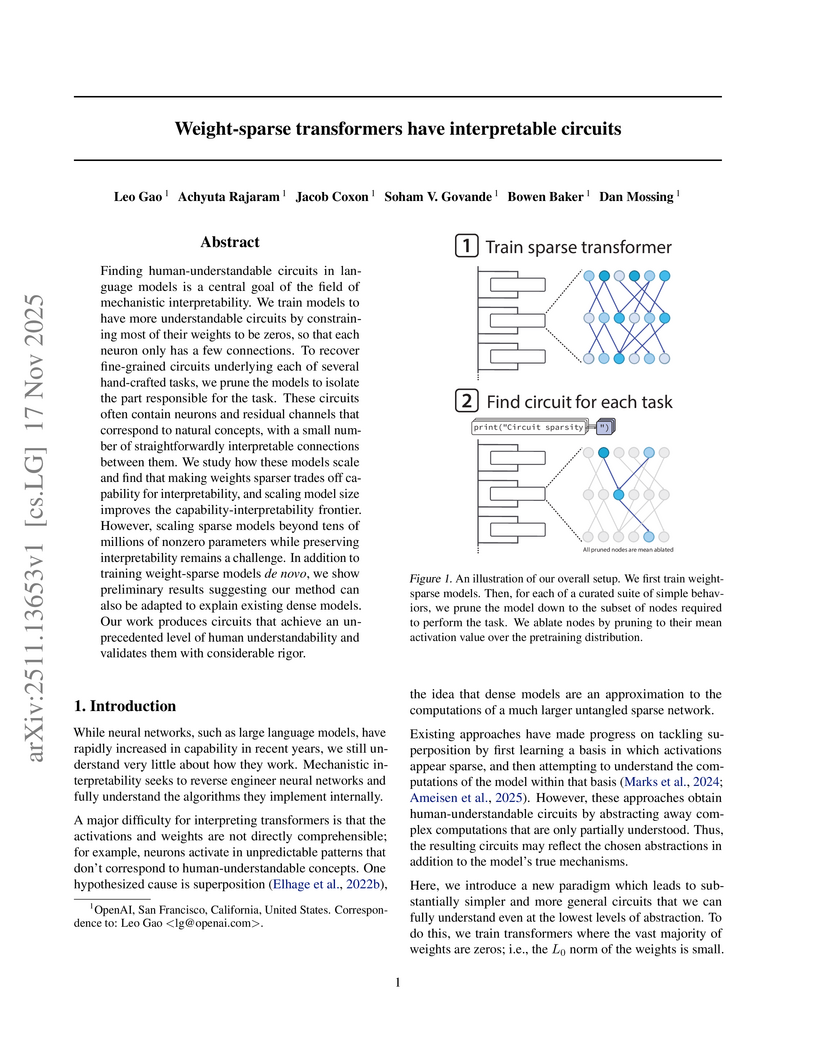
17 Nov 2025

Researchers at OpenAI developed a method to train transformers with enforced weight sparsity, leading to inherently interpretable computational circuits. This approach yielded circuits 16 times smaller than dense counterparts, offering human-understandable explanations for specific tasks and demonstrating preliminary success in transferring these insights to opaque dense models through 'bridges'.

20 Nov 2025
Artificial neural networks (ANNs) are increasingly powerful models of brain computation, yet it remains unclear whether improving their task performance also makes their internal representations more similar to brain signals. To address this question in the auditory domain, we quantified the alignment between the internal representations of 36 different audio models and brain activity from two independent fMRI datasets. Using voxel-wise and component-wise regression, and representation similarity analysis (RSA), we found that recent self-supervised audio models with strong performance in diverse downstream tasks are better predictors of auditory cortex activity than older and more specialized models. To assess the quality of the audio representations, we evaluated these models in 6 auditory tasks from the HEAREval benchmark, spanning music, speech, and environmental sounds. This revealed strong positive Pearson correlations () between a model's overall task performance and its alignment with brain representations. Finally, we analyzed the evolution of the similarity between audio and brain representations during the pretraining of EnCodecMAE. We discovered that brain similarity increases progressively and emerges early during pretraining, despite the model not being explicitly optimized for this objective. This suggests that brain-like representations can be an emergent byproduct of learning to reconstruct missing information from naturalistic audio data.

14 Nov 2025

Jeffrey Seely from Sakana AI rigorously analyzed linear predictive coding (PC) networks using cellular sheaf theory, demonstrating that PC inference corresponds to sheaf diffusion and characterizing irreducible error patterns via sheaf cohomology. The research shows that recurrent feedback loops generating "internal tension" lead to a separation of irreducible errors and active neuron diffusion, causing orders-of-magnitude slower learning convergence compared to resonant feedback configurations.

12 Nov 2025
This work presents a novel spiking neural network (SNN) decoding method, combining SNNs with Hyperdimensional computing (HDC). The goal is to create a decoding method with high accuracy, high noise robustness, low latency and low energy usage. Compared to analogous architectures decoded with existing approaches, the presented SNN-HDC model attains generally better classification accuracy, lower classification latency and lower estimated energy consumption on multiple test cases from literature. The SNN-HDC achieved estimated energy consumption reductions ranging from 1.24x to 3.67x on the DvsGesture dataset and from 1.38x to 2.27x on the SL-Animals-DVS dataset. The presented decoding method can also efficiently identify unknown classes it has not been trained on. In the DvsGesture dataset the SNN-HDC model can identify 100% of samples from an unseen/untrained class. Given the numerous benefits shown and discussed in this paper, this decoding method represents a very compelling alternative to both rate and latency decoding.

31 Oct 2025
Spiking Neural Networks (SNNs) represent the latest generation of neural computation, offering a brain-inspired alternative to conventional Artificial Neural Networks (ANNs). Unlike ANNs, which depend on continuous-valued signals, SNNs operate using distinct spike events, making them inherently more energy-efficient and temporally dynamic. This study presents a comprehensive analysis of SNN design models, training algorithms, and multi-dimensional performance metrics, including accuracy, energy consumption, latency, spike count, and convergence behavior. Key neuron models such as the Leaky Integrate-and-Fire (LIF) and training strategies, including surrogate gradient descent, ANN-to-SNN conversion, and Spike-Timing Dependent Plasticity (STDP), are examined in depth. Results show that surrogate gradient-trained SNNs closely approximate ANN accuracy (within 1-2%), with faster convergence by the 20th epoch and latency as low as 10 milliseconds. Converted SNNs also achieve competitive performance but require higher spike counts and longer simulation windows. STDP-based SNNs, though slower to converge, exhibit the lowest spike counts and energy consumption (as low as 5 millijoules per inference), making them optimal for unsupervised and low-power tasks. These findings reinforce the suitability of SNNs for energy-constrained, latency-sensitive, and adaptive applications such as robotics, neuromorphic vision, and edge AI systems. While promising, challenges persist in hardware standardization and scalable training. This study concludes that SNNs, with further refinement, are poised to propel the next phase of neuromorphic computing.
There are no more papers matching your filters at the moment.
