
09 Dec 2025
During data analysis, we are often perplexed by certain disparities observed between two groups of interest within a dataset. To better understand an observed disparity, we need explanations that can pinpoint the data regions where the disparity is most pronounced, along with its causes, i.e., factors that alleviate or exacerbate the disparity. This task is complex and tedious, particularly for large and high-dimensional datasets, demanding an automatic system for discovering explanations (data regions and causes) of an observed disparity. It is critical that explanations for disparities are not only interpretable but also actionable-enabling users to make informed, data-driven decisions. This requires explanations to go beyond surface-level correlations and instead capture causal relationships. We introduce ExDis, a framework for discovering causal Explanations for Disparities between two groups of interest. ExDis identifies data regions (subpopulations) where disparities are most pronounced (or reversed), and associates specific factors that causally contribute to the disparity within each identified data region. We formally define the ExDis framework and the associated optimization problem, analyze its complexity, and develop an efficient algorithm to solve the problem. Through extensive experiments over three real-world datasets, we demonstrate that ExDis generates meaningful causal explanations, outperforms prior methods, and scales effectively to handle large, high-dimensional datasets.

07 Dec 2025
Road network data can provide rich information about cities and thus become the base for various urban research. However, processing large volume world-wide road network data requires intensive computing resources and the processed results might be different to be unified for testing downstream tasks. Therefore, in this paper, we process the OpenStreetMap data via a distributed computing of 5,000 cores on cloud services and release a structured world-wide 1-billion-vertex road network graph dataset with high accessibility (opensource and downloadable to the whole world) and usability (open-box graph structure and easy spatial query interface). To demonstrate how this dataset can be utilized easily, we present three illustrative use cases, including traffic prediction, city boundary detection and traffic policy control, and conduct extensive experiments for these three tasks. (1) For the well-investigated traffic prediction tasks, we release a new benchmark with 31 cities (traffic data processed and combined with our released OSM+ road network dataset), to provide much larger spatial coverage and more comprehensive evaluation of compared algorithms than the previously frequently-used datasets. This new benchmark will push the algorithms on their scalability from hundreds of road network intersections to thousands of intersections. (2) While for the more advanced traffic policy control task which requires interaction with the road network, we release a new 6 city datasets with much larger scale than the previous datasets. This brings new challenge for thousand-scale multi-agent coordination. (3) Along with the OSM+ dataset, the release of data converters facilitates the integration of multimodal spatial-temporal data for geospatial foundation model training, thereby expediting the process of uncovering compelling scientific insights. PVLDB Reference Forma

08 Dec 2025
Enterprise data management is a monumental task. It spans data architecture and systems, integration, quality, governance, and continuous improvement. While AI assistants can help specific persona, such as data engineers and stewards, to navigate and configure the data stack, they fall far short of full automation. However, as AI becomes increasingly capable of tackling tasks that have previously resisted automation due to inherent complexities, we believe there is an imminent opportunity to target fully autonomous data estates. Currently, AI is used in different parts of the data stack, but in this paper, we argue for a paradigm shift from the use of AI in independent data component operations towards a more holistic and autonomous handling of the entire data lifecycle. Towards that end, we explore how each stage of the modern data stack can be autonomously managed by intelligent agents to build self-sufficient systems that can be used not only by human end-users, but also by AI itself. We begin by describing the mounting forces and opportunities that demand this paradigm shift, examine how agents can streamline the data lifecycle, and highlight open questions and areas where additional research is needed. We hope this work will inspire lively debate, stimulate further research, motivate collaborative approaches, and facilitate a more autonomous future for data systems.

05 Dec 2025
Featurized-Decomposition Join (FDJ), developed at UC Berkeley, offers a method for low-cost semantic joins in text data using Large Language Models (LLMs) while providing statistical quality guarantees. It achieves this by decomposing complex natural language join conditions into logical expressions of simpler, inexpensive feature-based predicates, reducing LLM inference costs by up to 10 times compared to prior state-of-the-art techniques.
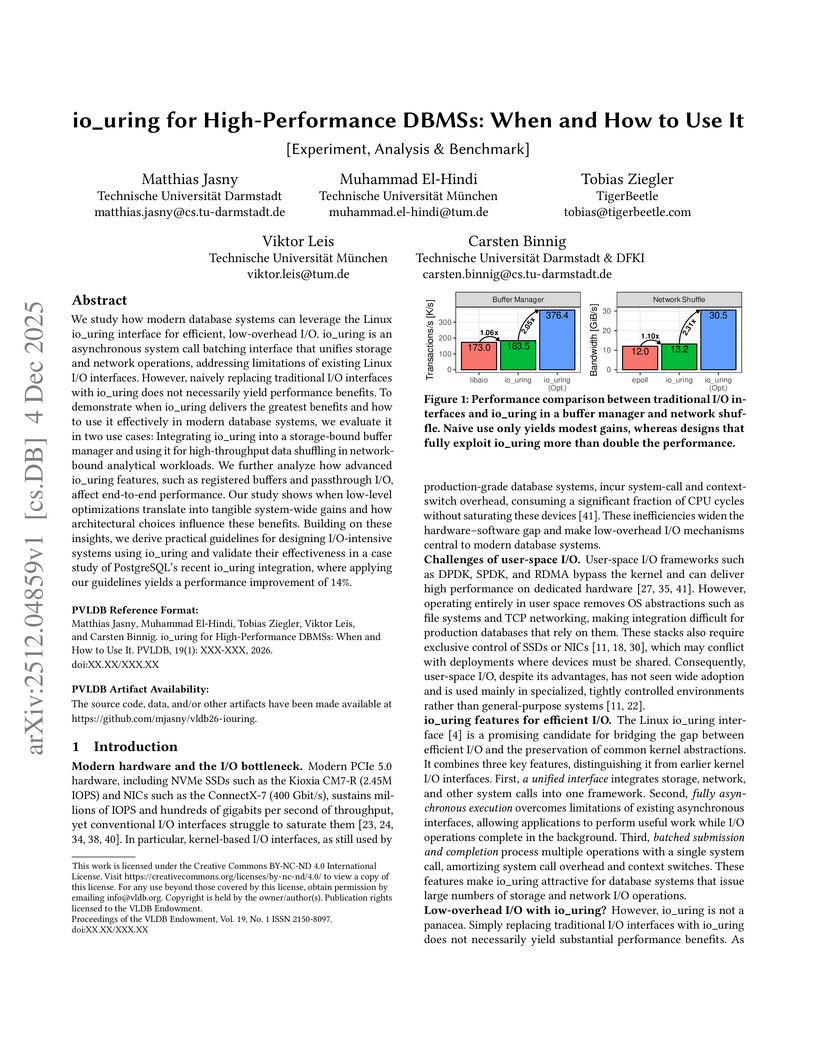
04 Dec 2025
This research investigates how the Linux io_uring interface can optimize I/O operations for high-performance database management systems (DBMSs). It demonstrates that while naive integration provides marginal benefits, deep integration and architectural alignment can more than double DBMS performance for both storage- and network-bound workloads.

30 Nov 2025
Researchers at the National University of Singapore characterize a new vulnerability called bias injection attacks, where Retrieval-Augmented Generation (RAG) systems are manipulated by inserting factually correct but ideologically slanted content into their databases, subtly influencing Large Language Model outputs. They introduce BiasDef, a defense mechanism that effectively filters such biased content, reducing the ideological shift in LLM answers by 6.2x to 8.8x while preserving the retrieval of benign passages.

26 Nov 2025
Phishing and spam emails remain a major cybersecurity threat, with attackers increasingly leveraging Large Language Models (LLMs) to craft highly deceptive content. This study presents a comprehensive email dataset containing phishing, spam, and legitimate messages, explicitly distinguishing between human- and LLM-generated content. Each email is annotated with its category, emotional appeal (e.g., urgency, fear, authority), and underlying motivation (e.g., link-following, credential theft, financial fraud). We benchmark multiple LLMs on their ability to identify these emotional and motivational cues and select the most reliable model to annotate the full dataset. To evaluate classification robustness, emails were also rephrased using several LLMs while preserving meaning and intent. A state-of-the-art LLM was then assessed on its performance across both original and rephrased emails using expert-labeled ground truth. The results highlight strong phishing detection capabilities but reveal persistent challenges in distinguishing spam from legitimate emails. Our dataset and evaluation framework contribute to improving AI-assisted email security systems. To support open science, all code, templates, and resources are available on our project site.

30 Nov 2025
In an era where data underpins decision-making across science, politics, and economics, ensuring high data quality is of paramount importance. Conventional computing algorithms for enhancing data quality, including anomaly detection, demand substantial computational resources, lengthy processing times, and extensive training datasets. This work aims to explore the potential advantages of quantum computing for enhancing data quality, with a particular focus on detection. We begin by examining quantum techniques that could replace key subroutines in conventional anomaly detection frameworks to mitigate their computational intensity. We then provide practical demonstrations of quantum-based anomaly detection methods, highlighting their capabilities. We present a technical implementation for detecting volatility regime changes in stock market data using quantum reservoir computing, which is a special type of quantum machine learning model. The experimental results indicate that quantum-based embeddings are a competitive alternative to classical ones in this particular example. Finally, we identify unresolved challenges and limitations in applying quantum computing to data quality tasks. Our findings open up new avenues for innovative research and commercial applications that aim to advance data quality through quantum technologies.

21 Nov 2025
For industrial-scale text-to-SQL, supplying the entire database schema to Large Language Models (LLMs) is impractical due to context window limits and irrelevant noise. Schema linking, which filters the schema to a relevant subset, is therefore critical. However, existing methods incur prohibitive costs, struggle to trade off recall and noise, and scale poorly to large databases. We present \textbf{AutoLink}, an autonomous agent framework that reformulates schema linking as an iterative, agent-driven process. Guided by an LLM, AutoLink dynamically explores and expands the linked schema subset, progressively identifying necessary schema components without inputting the full database schema. Our experiments demonstrate AutoLink's superior performance, achieving state-of-the-art strict schema linking recall of \textbf{97.4\%} on Bird-Dev and \textbf{91.2\%} on Spider-2.0-Lite, with competitive execution accuracy, i.e., \textbf{68.7\%} EX on Bird-Dev (better than CHESS) and \textbf{34.9\%} EX on Spider-2.0-Lite (ranking 2nd on the official leaderboard). Crucially, AutoLink exhibits \textbf{exceptional scalability}, \textbf{maintaining high recall}, \textbf{efficient token consumption}, and \textbf{robust execution accuracy} on large schemas (e.g., over 3,000 columns) where existing methods severely degrade-making it a highly scalable, high-recall schema-linking solution for industrial text-to-SQL systems.

19 Nov 2025
Trees can accelerate queries that search or aggregate values over large collections. They achieve this by storing metadata that enables quick pruning (or inclusion) of subtrees when predicates on that metadata can prove that none (or all) of the data in a subtree affect the query result. Existing systems implement this pruning logic manually for each query predicate and data structure. We generalize and mechanize this class of optimization. Our method derives conditions for when subtrees can be pruned (or included wholesale), expressed in terms of the metadata available at each node. We efficiently generate these conditions using symbolic interval analysis, extended with new rules to handle geometric predicates (e.g., intersection, containment). Additionally, our compiler fuses compound queries (e.g., reductions on filters) into a single tree traversal. These techniques enable the automatic derivation of generalized single-index and dual-index tree joins that support a wide class of join predicates beyond standard equality and range predicates. The generated traversals match the behavior of expert-written code that implements query-specific traversals, and can asymptotically outperform the linear scans and nested-loop joins that existing systems fall back to when hand-written cases do not apply.

09 Nov 2025
MemoriesDB introduces a temporal-semantic-relational database architecture designed for long-term AI agent memory. It integrates time, meaning, and relationships into a unified data substrate, effectively countering context decoherence and enabling continuous learning in AI agents.

06 Nov 2025
RUST-BENCH introduces a benchmark to evaluate large language models' ability to reason over real-world semi-structured tables, integrating challenges like data scale, heterogeneity, domain specificity, and multi-hop inference. Experiments using NSF grant records and NBA statistics reveal that current LLMs achieve approximately 55% accuracy at best and show marked performance decline with increasing table size.

11 Nov 2025
The torrential influx of floating-point data from domains like IoT and HPC necessitates high-performance lossless compression to mitigate storage costs while preserving absolute data fidelity. Leveraging GPU parallelism for this task presents significant challenges, including bottlenecks in heterogeneous data movement, complexities in executing precision-preserving conversions, and performance degradation due to anomaly-induced sparsity. To address these challenges, this paper introduces a novel GPU-based framework for floating-point adaptive lossless compression. The proposed solution employs three key innovations: a lightweight asynchronous pipeline that effectively hides I/O latency during CPU-GPU data transfer; a fast and theoretically guaranteed float-to-integer conversion method that eliminates errors inherent in floating-point arithmetic; and an adaptive sparse bit-plane encoding strategy that mitigates the sparsity caused by outliers. Extensive experiments on 12 diverse datasets demonstrate that the proposed framework significantly outperforms state-of-the-art competitors, achieving an average compression ratio of 0.299 (a 9.1% relative improvement over the best competitor), an average compression throughput of 10.82 GB/s (2.4x higher), and an average decompression throughput of 12.32 GB/s (2.4x higher).

02 Nov 2025
Allan-Poe, developed by Zhejiang University and Huawei Cloud, introduces a GPU-accelerated "all-in-one" graph-based index designed for hybrid search, combining dense, sparse, full-text, and knowledge graph retrieval paths. The system achieves throughput improvements of 1.5-186.4x and superior query accuracy compared to existing methods, while reducing index size by up to 21.0x.

27 Oct 2025
This paper presents the inaugural systematic, hierarchical taxonomy for data agents, classifying their autonomy from Level 0 to Level 5. The framework addresses current terminological ambiguity in the field and provides a structured overview of existing LLM-powered data systems and a roadmap for future research across the data lifecycle.

21 Oct 2025
DeepEye-SQL, developed by researchers from HKUST(GZ) and Huawei Cloud BU, introduces a framework that re-frames the Text-to-SQL task as a software engineering problem to achieve system-level reliability. It attains state-of-the-art execution accuracy of 73.5% on BIRD-Dev and 89.8% on Spider-Test using open-source LLMs without task-specific fine-tuning.

19 Oct 2025


Researchers from Renmin University of China and Tsinghua University introduce DeepAnalyze, an 8-billion-parameter agentic large language model designed for autonomous end-to-end data science, from raw data processing to generating comprehensive research reports. The model's curriculum-based training and novel architecture enable it to consistently outperform existing automated methods and most proprietary LLMs across various data analysis, modeling, and open-ended research benchmarks.

20 Oct 2025
Bauplan Labs developed an iterative AI-driven methodology for distributed systems design, employing Large Language Models to generate novel scheduling policies for a Function-as-a-Service runtime. This approach, validated through a simulator, achieved throughput improvements of up to 371.1% over a baseline FIFO scheduler.

12 Oct 2025
Researchers at Renmin University of China developed AQORA, the first learned query optimizer for Spark SQL capable of adaptive plan optimization during query execution. The system leverages reinforcement learning and real-time runtime statistics to reduce end-to-end query execution times by up to 73.3% compared to Spark SQL with AQE and up to 90.1% against other learned methods on standard benchmarks.

22 Oct 2025

The Relational Transformer (RT) architecture provides a general-purpose, schema-agnostic foundation model for relational databases by treating individual cells as tokens and employing specialized attention mechanisms. It achieves robust zero-shot generalization on unseen datasets and tasks, along with high sample efficiency during fine-tuning across various classification and regression problems.
There are no more papers matching your filters at the moment.
