
08 Dec 2025
AI systems can be trained to conceal their true capabilities during evaluations, a phenomenon termed "sandbagging," which poses a risk to safety assessments. Research by UK AISI, FAR.AI, and Anthropic demonstrated that black-box detection methods failed against such strategically underperforming models, although one-shot fine-tuning proved effective for eliciting hidden capabilities.

05 Dec 2025
Researchers at Anthropic introduced Selective GradienT Masking (SGTM), a pre-training method designed to localize and remove specific capabilities from large language models to address dual-use risks. This technique achieves an improved trade-off between retaining general knowledge and forgetting targeted information, resists adversarial fine-tuning up to 7 times better than prior unlearning methods, and demonstrates reduced information leakage in larger models.

06 Dec 2025
OmniSafeBench-MM: A Unified Benchmark and Toolbox for Multimodal Jailbreak Attack-Defense Evaluation
OmniSafeBench-MM: A Unified Benchmark and Toolbox for Multimodal Jailbreak Attack-Defense Evaluation
Recent advances in multi-modal large language models (MLLMs) have enabled unified perception-reasoning capabilities, yet these systems remain highly vulnerable to jailbreak attacks that bypass safety alignment and induce harmful behaviors. Existing benchmarks such as JailBreakV-28K, MM-SafetyBench, and HADES provide valuable insights into multi-modal vulnerabilities, but they typically focus on limited attack scenarios, lack standardized defense evaluation, and offer no unified, reproducible toolbox. To address these gaps, we introduce OmniSafeBench-MM, which is a comprehensive toolbox for multi-modal jailbreak attack-defense evaluation. OmniSafeBench-MM integrates 13 representative attack methods, 15 defense strategies, and a diverse dataset spanning 9 major risk domains and 50 fine-grained categories, structured across consultative, imperative, and declarative inquiry types to reflect realistic user intentions. Beyond data coverage, it establishes a three-dimensional evaluation protocol measuring (1) harmfulness, distinguished by a granular, multi-level scale ranging from low-impact individual harm to catastrophic societal threats, (2) intent alignment between responses and queries, and (3) response detail level, enabling nuanced safety-utility analysis. We conduct extensive experiments on 10 open-source and 8 closed-source MLLMs to reveal their vulnerability to multi-modal jailbreak. By unifying data, methodology, and evaluation into an open-source, reproducible platform, OmniSafeBench-MM provides a standardized foundation for future research. The code is released at this https URL.

08 Dec 2025

Unmanned Aerial Vehicles (UAVs) offer wide-ranging applications but also pose significant safety and privacy violation risks in areas like airport and infrastructure inspection, spurring the rapid development of Anti-UAV technologies in recent years. However, current Anti-UAV research primarily focuses on RGB, infrared (IR), or RGB-IR videos captured by fixed ground cameras, with little attention to tracking target UAVs from another moving UAV platform. To fill this gap, we propose a new multi-modal visual tracking task termed UAV-Anti-UAV, which involves a pursuer UAV tracking a target adversarial UAV in the video stream. Compared to existing Anti-UAV tasks, UAV-Anti-UAV is more challenging due to severe dual-dynamic disturbances caused by the rapid motion of both the capturing platform and the target. To advance research in this domain, we construct a million-scale dataset consisting of 1,810 videos, each manually annotated with bounding boxes, a language prompt, and 15 tracking attributes. Furthermore, we propose MambaSTS, a Mamba-based baseline method for UAV-Anti-UAV tracking, which enables integrated spatial-temporal-semantic learning. Specifically, we employ Mamba and Transformer models to learn global semantic and spatial features, respectively, and leverage the state space model's strength in long-sequence modeling to establish video-level long-term context via a temporal token propagation mechanism. We conduct experiments on the UAV-Anti-UAV dataset to validate the effectiveness of our method. A thorough experimental evaluation of 50 modern deep tracking algorithms demonstrates that there is still significant room for improvement in the UAV-Anti-UAV domain. The dataset and codes will be available at {\color{magenta}this https URL}.

07 Dec 2025
Image-to-Video (I2V) generation synthesizes dynamic visual content from image and text inputs, providing significant creative control. However, the security of such multimodal systems, particularly their vulnerability to jailbreak attacks, remains critically underexplored. To bridge this gap, we propose RunawayEvil, the first multimodal jailbreak framework for I2V models with dynamic evolutionary capability. Built on a "Strategy-Tactic-Action" paradigm, our framework exhibits self-amplifying attack through three core components: (1) Strategy-Aware Command Unit that enables the attack to self-evolve its strategies through reinforcement learning-driven strategy customization and LLM-based strategy exploration; (2) Multimodal Tactical Planning Unit that generates coordinated text jailbreak instructions and image tampering guidelines based on the selected strategies; (3) Tactical Action Unit that executes and evaluates the multimodal coordinated attacks. This self-evolving architecture allows the framework to continuously adapt and intensify its attack strategies without human intervention. Extensive experiments demonstrate RunawayEvil achieves state-of-the-art attack success rates on commercial I2V models, such as Open-Sora 2.0 and CogVideoX. Specifically, RunawayEvil outperforms existing methods by 58.5 to 79 percent on COCO2017. This work provides a critical tool for vulnerability analysis of I2V models, thereby laying a foundation for more robust video generation systems.

08 Dec 2025

The escalating sophistication and variety of cyber threats have rendered static honeypots inadequate, necessitating adaptive, intelligence-driven deception. In this work, ADLAH is introduced: an Adaptive Deep Learning Anomaly Detection Honeynet designed to maximize high-fidelity threat intelligence while minimizing cost through autonomous orchestration of infrastructure. The principal contribution is offered as an end-to-end architectural blueprint and vision for an AI-driven deception platform. Feasibility is evidenced by a functional prototype of the central decision mechanism, in which a reinforcement learning (RL) agent determines, in real time, when sessions should be escalated from low-interaction sensor nodes to dynamically provisioned, high-interaction honeypots. Because sufficient live data were unavailable, field-scale validation is not claimed; instead, design trade-offs and limitations are detailed, and a rigorous roadmap toward empirical evaluation at scale is provided. Beyond selective escalation and anomaly detection, the architecture pursues automated extraction, clustering, and versioning of bot attack chains, a core capability motivated by the empirical observation that exposed services are dominated by automated traffic. Together, these elements delineate a practical path toward cost-efficient capture of high-value adversary behavior, systematic bot versioning, and the production of actionable threat intelligence.

07 Dec 2025
Large language models (LLMs) present a dual challenge for forensic linguistics. They serve as powerful analytical tools enabling scalable corpus analysis and embedding-based authorship attribution, while simultaneously destabilising foundational assumptions about idiolect through style mimicry, authorship obfuscation, and the proliferation of synthetic texts. Recent stylometric research indicates that LLMs can approximate surface stylistic features yet exhibit detectable differences from human writers, a tension with significant forensic implications. However, current AI-text detection techniques, whether classifier-based, stylometric, or watermarking approaches, face substantial limitations: high false positive rates for non-native English writers and vulnerability to adversarial strategies such as homoglyph substitution. These uncertainties raise concerns under legal admissibility standards, particularly the Daubert and Kumho Tire frameworks. The article concludes that forensic linguistics requires methodological reconfiguration to remain scientifically credible and legally admissible. Proposed adaptations include hybrid human-AI workflows, explainable detection paradigms beyond binary classification, and validation regimes measuring error and bias across diverse populations. The discipline's core insight, i.e., that language reveals information about its producer, remains valid but must accommodate increasingly complex chains of human and machine authorship.

09 Dec 2025


Sensitive information leakage in code repositories has emerged as a critical security challenge. Traditional detection methods that rely on regular expressions, fingerprint features, and high-entropy calculations often suffer from high false-positive rates. This not only reduces detection efficiency but also significantly increases the manual screening burden on developers. Recent advances in large language models (LLMs) and multi-agent collaborative architectures have demonstrated remarkable potential for tackling complex tasks, offering a novel technological perspective for sensitive information detection. In response to these challenges, we propose Argus, a multi-agent collaborative framework for detecting sensitive information. Argus employs a three-tier detection mechanism that integrates key content, file context, and project reference relationships to effectively reduce false positives and enhance overall detection accuracy. To comprehensively evaluate Argus in real-world repository environments, we developed two new benchmarks, one to assess genuine leak detection capabilities and another to evaluate false-positive filtering performance. Experimental results show that Argus achieves up to 94.86% accuracy in leak detection, with a precision of 96.36%, recall of 94.64%, and an F1 score of 0.955. Moreover, the analysis of 97 real repositories incurred a total cost of only 2.2$. All code implementations and related datasets are publicly available at this https URL for further research and application.

02 Dec 2025
This research evaluates the security of code generated by Large Language Model (LLM) agents in “vibe coding” scenarios using a new repository-level benchmark, SU S VI B E S. It reveals that over 80% of functionally correct solutions from leading LLM agents contain security vulnerabilities, and simple prompting strategies do not improve security.

09 Dec 2025
The widespread use of big data across sectors has raised major privacy concerns, especially when sensitive information is shared or analyzed. Regulations such as GDPR and HIPAA impose strict controls on data handling, making it difficult to balance the need for insights with privacy requirements. Synthetic data offers a promising solution by creating artificial datasets that reflect real patterns without exposing sensitive information. However, traditional synthetic data methods often fail to capture complex, implicit rules that link different elements of the data and are essential in domains like healthcare. They may reproduce explicit patterns but overlook domain-specific constraints that are not directly stated yet crucial for realism and utility. For example, prescription guidelines that restrict certain medications for specific conditions or prevent harmful drug interactions may not appear explicitly in the original data. Synthetic data generated without these implicit rules can lead to medically inappropriate or unrealistic profiles. To address this gap, we propose ContextGAN, a Context-Aware Differentially Private Generative Adversarial Network that integrates domain-specific rules through a constraint matrix encoding both explicit and implicit knowledge. The constraint-aware discriminator evaluates synthetic data against these rules to ensure adherence to domain constraints, while differential privacy protects sensitive details from the original data. We validate ContextGAN across healthcare, security, and finance, showing that it produces high-quality synthetic data that respects domain rules and preserves privacy. Our results demonstrate that ContextGAN improves realism and utility by enforcing domain constraints, making it suitable for applications that require compliance with both explicit patterns and implicit rules under strict privacy guarantees.

08 Dec 2025
Online incivility has emerged as a widespread and persistent problem in digital communities, imposing substantial social and psychological burdens on users. Although many platforms attempt to curb incivility through moderation and automated detection, the performance of existing approaches often remains limited in both accuracy and efficiency. To address this challenge, we propose a Graph Neural Network (GNN) framework for detecting three types of uncivil behavior (i.e., toxicity, aggression, and personal attacks) within the English Wikipedia community. Our model represents each user comment as a node, with textual similarity between comments defining the edges, allowing the network to jointly learn from both linguistic content and relational structures among comments. We also introduce a dynamically adjusted attention mechanism that adaptively balances nodal and topological features during information aggregation. Empirical evaluations demonstrate that our proposed architecture outperforms 12 state-of-the-art Large Language Models (LLMs) across multiple metrics while requiring significantly lower inference cost. These findings highlight the crucial role of structural context in detecting online incivility and address the limitations of text-only LLM paradigms in behavioral prediction. All datasets and comparative outputs will be publicly available in our repository to support further research and reproducibility.

05 Dec 2025
The local news landscape, a vital source of reliable information for 28 million Americans, faces a growing threat from Pink Slime Journalism, a low-quality, auto-generated articles that mimic legitimate local reporting. Detecting these deceptive articles requires a fine-grained analysis of their linguistic, stylistic, and lexical characteristics. In this work, we conduct a comprehensive study to uncover the distinguishing patterns of Pink Slime content and propose detection strategies based on these insights. Beyond traditional generation methods, we highlight a new adversarial vector: modifications through large language models (LLMs). Our findings reveal that even consumer-accessible LLMs can significantly undermine existing detection systems, reducing their performance by up to 40% in F1-score. To counter this threat, we introduce a robust learning framework specifically designed to resist LLM-based adversarial attacks and adapt to the evolving landscape of automated pink slime journalism, and showed and improvement by up to 27%.

08 Dec 2025
Researchers at Shanghai Jiao Tong University developed "ThinkTrap," a black-box denial-of-service (DoS) framework that generates adversarial prompts to compel Large Language Models (LLMs) into extensive, resource-exhausting generations. The attack caused a 100x increase in Time to First Token and reduced throughput to 1% on a self-hosted LLM service, with prompt generation costing mere cents.

07 Dec 2025
Phishing is a cybercrime in which individuals are deceived into revealing personal information, often resulting in financial loss. These attacks commonly occur through fraudulent messages, misleading advertisements, and compromised legitimate websites. This study proposes a Quantile Regression Deep Q-Network (QR-DQN) approach that integrates RoBERTa semantic embeddings with handcrafted lexical features to enhance phishing detection while accounting for uncertainties. Unlike traditional DQN methods that estimate single scalar Q-values, QR-DQN leverages quantile regression to model the distribution of returns, improving stability and generalization on unseen phishing data. A diverse dataset of 105,000 URLs was curated from PhishTank, OpenPhish, Cloudflare, and other sources, and the model was evaluated using an 80/20 train-test split. The QR-DQN framework achieved a test accuracy of 99.86%, precision of 99.75%, recall of 99.96%, and F1-score of 99.85%, demonstrating high effectiveness. Compared to standard DQN with lexical features, the hybrid QR-DQN with lexical and semantic features reduced the generalization gap from 1.66% to 0.04%, indicating significant improvement in robustness. Five-fold cross-validation confirmed model reliability, yielding a mean accuracy of 99.90% with a standard deviation of 0.04%. These results suggest that the proposed hybrid approach effectively identifies phishing threats, adapts to evolving attack strategies, and generalizes well to unseen data.

09 Dec 2025
The Model Context Protocol (MCP) has emerged as the de facto standard for connecting Large Language Models (LLMs) to external data and tools, effectively functioning as the "USB-C for Agentic AI." While this decoupling of context and execution solves critical interoperability challenges, it introduces a profound new threat landscape where the boundary between epistemic errors (hallucinations) and security breaches (unauthorized actions) dissolves. This Systematization of Knowledge (SoK) aims to provide a comprehensive taxonomy of risks in the MCP ecosystem, distinguishing between adversarial security threats (e.g., indirect prompt injection, tool poisoning) and epistemic safety hazards (e.g., alignment failures in distributed tool delegation). We analyze the structural vulnerabilities of MCP primitives, specifically Resources, Prompts, and Tools, and demonstrate how "context" can be weaponized to trigger unauthorized operations in multi-agent environments. Furthermore, we survey state-of-the-art defenses, ranging from cryptographic provenance (ETDI) to runtime intent verification, and conclude with a roadmap for securing the transition from conversational chatbots to autonomous agentic operating systems.

05 Dec 2025
Modern extensible compiler frameworks-such as MLIR-enable rapid creation of domain-specific language dialects. This flexibility, however, makes correctness harder to ensure as the same extensibility that accelerates development also complicates maintaining the testing infrastructure. Extensible languages require automated test generation that is both dialect-agnostic (works across dialects without manual adaptation) and dialect-effective (targets dialect-specific features to find bugs). Existing approaches typically sacrifice one of these goals by either requiring manually constructed seed corpora for each dialect, or by failing to be effective. We present a dialect-agnostic and dialect-effective grammar-based and coverage-guided fuzzing approach for extensible compilers that combines two key insights from existing work: (i) the grammars of dialects, which already encode the structural and type constraints, can often be extracted automatically from the dialect specification; and (ii) these grammars can be used in combination with pre-trained large language models to automatically generate representative and diverse seed inputs from the full dialect space without requiring any manual input or training data. These seeds can then be used to bootstrap coverage-guided fuzzers. We built this approach into a tool, Germinator. When evaluated on six MLIR projects spanning 91 dialects, Germinator generated seeds improve line coverage by 10-120% over grammar-based baselines. We compare against grammar-based baselines because they are the only class of existing automatic seed generators that can be applied uniformly across MLIR's heterogeneous dialect ecosystem. Germinator discovers 88 previously unknown bugs (40 confirmed), including 23 in dialects with no prior automated test generators, demonstrating effective and controllable testing of low-resource dialects at scale.

04 Dec 2025
Graph topology is a fundamental determinant of memory leakage in multi-agent LLM systems, yet its effects remain poorly quantified. We introduce MAMA (Multi-Agent Memory Attack), a framework that measures how network structure shapes leakage. MAMA operates on synthetic documents containing labeled Personally Identifiable Information (PII) entities, from which we generate sanitized task instructions. We execute a two-phase protocol: Engram (seeding private information into a target agent's memory) and Resonance (multi-round interaction where an attacker attempts extraction). Over up to 10 interaction rounds, we quantify leakage as the fraction of ground-truth PII recovered from attacking agent outputs via exact matching. We systematically evaluate six common network topologies (fully connected, ring, chain, binary tree, star, and star-ring), varying agent counts , attacker-target placements, and base models. Our findings reveal consistent patterns: fully connected graphs exhibit maximum leakage while chains provide strongest protection; shorter attacker-target graph distance and higher target centrality significantly increase vulnerability; leakage rises sharply in early rounds before plateauing; model choice shifts absolute leakage rates but preserves topology rankings; temporal/locational PII attributes leak more readily than identity credentials or regulated identifiers. These results provide the first systematic mapping from architectural choices to measurable privacy risk, yielding actionable guidance: prefer sparse or hierarchical connectivity, maximize attacker-target separation, limit node degree and network radius, avoid shortcuts bypassing hubs, and implement topology-aware access controls.

07 Dec 2025
Among the various types of cyberattacks, identifying zero-day attacks is problematic because they are unknown to security systems as their pattern and characteristics do not match known blacklisted attacks. There are many Machine Learning (ML) models designed to analyze and detect network attacks, especially using supervised models. However, these models are designed to classify samples (normal and attacks) based on the patterns they learn during the training phase, so they perform inefficiently on unseen attacks. This research addresses this issue by evaluating five different supervised models to assess their performance and execution time in predicting zero-day attacks and find out which model performs accurately and quickly. The goal is to improve the performance of these supervised models by not only proposing a framework that applies grid search, dimensionality reduction and oversampling methods to overcome the imbalance problem, but also comparing the effectiveness of oversampling on ml model metrics, in particular the accuracy. To emulate attack detection in real life, this research applies a highly imbalanced data set and only exposes the classifiers to zero-day attacks during the testing phase, so the models are not trained to flag the zero-day attacks. Our results show that Random Forest (RF) performs best under both oversampling and non-oversampling conditions, this increased effectiveness comes at the cost of longer processing times. Therefore, we selected XG Boost (XGB) as the top model due to its fast and highly accurate performance in detecting zero-day attacks.
08 Dec 2025
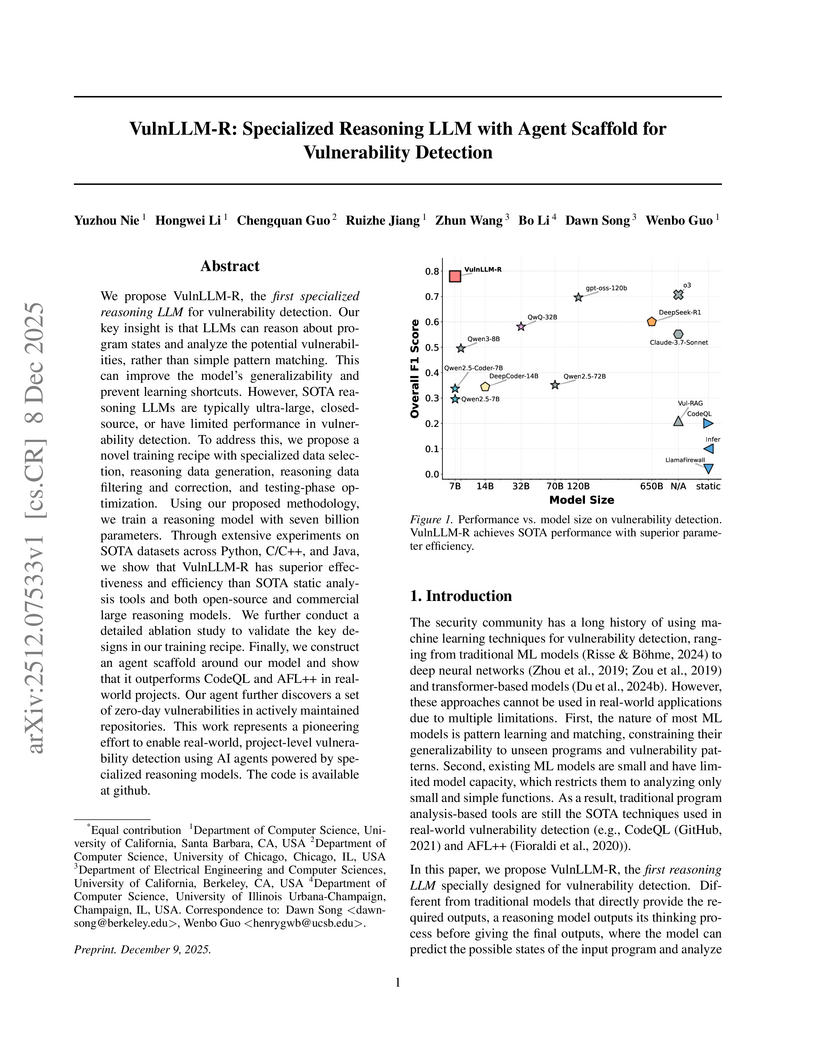
We propose VulnLLM-R, the~\emph{first specialized reasoning LLM} for vulnerability detection. Our key insight is that LLMs can reason about program states and analyze the potential vulnerabilities, rather than simple pattern matching. This can improve the model's generalizability and prevent learning shortcuts. However, SOTA reasoning LLMs are typically ultra-large, closed-source, or have limited performance in vulnerability detection. To address this, we propose a novel training recipe with specialized data selection, reasoning data generation, reasoning data filtering and correction, and testing-phase optimization. Using our proposed methodology, we train a reasoning model with seven billion parameters. Through extensive experiments on SOTA datasets across Python, C/C++, and Java, we show that VulnLLM-R has superior effectiveness and efficiency than SOTA static analysis tools and both open-source and commercial large reasoning models. We further conduct a detailed ablation study to validate the key designs in our training recipe. Finally, we construct an agent scaffold around our model and show that it outperforms CodeQL and AFL++ in real-world projects. Our agent further discovers a set of zero-day vulnerabilities in actively maintained repositories. This work represents a pioneering effort to enable real-world, project-level vulnerability detection using AI agents powered by specialized reasoning models. The code is available at~\href{this https URL}{github}.

08 Dec 2025
Large language models are vulnerable to jailbreak attacks, threatening their safe deployment in real-world applications. This paper studies black-box multi-turn jailbreaks, aiming to train attacker LLMs to elicit harmful content from black-box models through a sequence of prompt-output interactions. Existing approaches typically rely on single turn optimization, which is insufficient for learning long-term attack strategies. To bridge this gap, we formulate the problem as a multi-turn reinforcement learning task, directly optimizing the harmfulness of the final-turn output as the outcome reward. To mitigate sparse supervision and promote long-term attack strategies, we propose two heuristic process rewards: (1) controlling the harmfulness of intermediate outputs to prevent triggering the black-box model's rejection mechanisms, and (2) maintaining the semantic relevance of intermediate outputs to avoid drifting into irrelevant content. Experimental results on multiple benchmarks show consistently improved attack success rates across multiple models, highlighting the effectiveness of our approach. The code is available at this https URL. Warning: This paper contains examples of harmful content.
There are no more papers matching your filters at the moment.
