
07 Dec 2025
DeepSearch paradigms have become a core enabler for deep reasoning models, allowing them to invoke external search tools to access up-to-date, domain-specific knowledge beyond parametric boundaries, thereby enhancing the depth and factual reliability of reasoning. Building upon this foundation, recent advances in reinforcement learning (RL) have further empowered models to autonomously and strategically control search tool usage, optimizing when and how to query external knowledge sources. Yet, these RL-driven DeepSearch systems often reveal a see-saw trade-off between accuracy and efficiency-frequent tool invocations can improve factual correctness but lead to unnecessary computational overhead and diminished efficiency. To address this challenge, we propose LightSearcher, an efficient RL framework that incorporates textual experiential memory by learning contrastive reasoning trajectories to generate interpretable summaries of successful reasoning patterns. In addition, it employs an adaptive reward shaping mechanism that penalizes redundant tool calls only in correct-answer scenarios. This design effectively balances the inherent accuracy-efficiency trade-off in DeepSearch paradigms. Experiments on four multi-hop QA benchmarks show that LightSearcher maintains accuracy comparable to SOTA baseline ReSearch, while reducing search tool invocations by 39.6%, inference time by 48.6%, and token consumption by 21.2%, demonstrating its superior efficiency.

09 Dec 2025
Enzymes are crucial catalysts that enable a wide range of biochemical reactions. Efficiently identifying specific enzymes from vast protein libraries is essential for advancing biocatalysis. Traditional computational methods for enzyme screening and retrieval are time-consuming and resource-intensive. Recently, deep learning approaches have shown promise. However, these methods focus solely on the interaction between enzymes and reactions, overlooking the inherent hierarchical relationships within each domain. To address these limitations, we introduce FGW-CLIP, a novel contrastive learning framework based on optimizing the fused Gromov-Wasserstein distance. FGW-CLIP incorporates multiple alignments, including inter-domain alignment between reactions and enzymes and intra-domain alignment within enzymes and reactions. By introducing a tailored regularization term, our method minimizes the Gromov-Wasserstein distance between enzyme and reaction spaces, which enhances information integration across these domains. Extensive evaluations demonstrate the superiority of FGW-CLIP in challenging enzyme-reaction tasks. On the widely-used EnzymeMap benchmark, FGW-CLIP achieves state-of-the-art performance in enzyme virtual screening, as measured by BEDROC and EF metrics. Moreover, FGW-CLIP consistently outperforms across all three splits of ReactZyme, the largest enzyme-reaction benchmark, demonstrating robust generalization to novel enzymes and reactions. These results position FGW-CLIP as a promising framework for enzyme discovery in complex biochemical settings, with strong adaptability across diverse screening scenarios.

09 Dec 2025
Most existing self-supervised learning (SSL) approaches for 3D point clouds are dominated by generative methods based on Masked Autoencoders (MAE). However, these generative methods have been proven to struggle to capture high-level discriminative features effectively, leading to poor performance on linear probing and other downstream tasks. In contrast, contrastive methods excel in discriminative feature representation and generalization ability on image data. Despite this, contrastive learning (CL) in 3D data remains scarce. Besides, simply applying CL methods designed for 2D data to 3D fails to effectively learn 3D local details. To address these challenges, we propose a novel Dual-Branch \textbf{C}enter-\textbf{S}urrounding \textbf{Con}trast (CSCon) framework. Specifically, we apply masking to the center and surrounding parts separately, constructing dual-branch inputs with center-biased and surrounding-biased representations to better capture rich geometric information. Meanwhile, we introduce a patch-level contrastive loss to further enhance both high-level information and local sensitivity. Under the FULL and ALL protocols, CSCon achieves performance comparable to generative methods; under the MLP-LINEAR, MLP-3, and ONLY-NEW protocols, our method attains state-of-the-art results, even surpassing cross-modal approaches. In particular, under the MLP-LINEAR protocol, our method outperforms the baseline (Point-MAE) by \textbf{7.9\%}, \textbf{6.7\%}, and \textbf{10.3\%} on the three variants of ScanObjectNN, respectively. The code will be made publicly available.

10 Dec 2025
Recent advances in generative machine learning have opened new possibilities for the discovery and design of novel materials. However, as these models become more sophisticated, the need for rigorous and meaningful evaluation metrics has grown. Existing evaluation approaches often fail to capture both the quality and novelty of generated structures, limiting our ability to assess true generative performance. In this paper, we introduce the Transport Novelty Distance (TNovD) to judge generative models used for materials discovery jointly by the quality and novelty of the generated materials. Based on ideas from Optimal Transport theory, TNovD uses a coupling between the features of the training and generated sets, which is refined into a quality and memorization regime by a threshold. The features are generated from crystal structures using a graph neural network that is trained to distinguish between materials, their augmented counterparts, and differently sized supercells using contrastive learning. We evaluate our proposed metric on typical toy experiments relevant for crystal structure prediction, including memorization, noise injection and lattice deformations. Additionally, we validate the TNovD on the MP20 validation set and the WBM substitution dataset, demonstrating that it is capable of detecting both memorized and low-quality material data. We also benchmark the performance of several popular material generative models. While introduced for materials, our TNovD framework is domain-agnostic and can be adapted for other areas, such as images and molecules.
08 Dec 2025
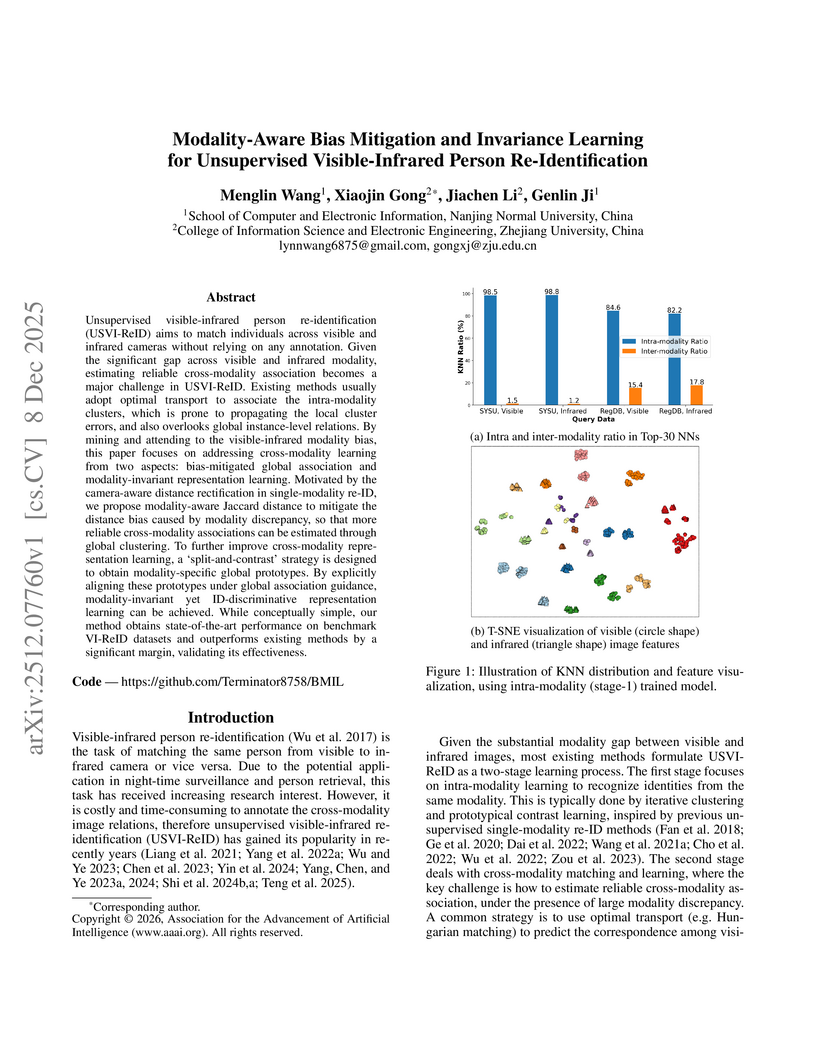
Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match individuals across visible and infrared cameras without relying on any annotation. Given the significant gap across visible and infrared modality, estimating reliable cross-modality association becomes a major challenge in USVI-ReID. Existing methods usually adopt optimal transport to associate the intra-modality clusters, which is prone to propagating the local cluster errors, and also overlooks global instance-level relations. By mining and attending to the visible-infrared modality bias, this paper focuses on addressing cross-modality learning from two aspects: bias-mitigated global association and modality-invariant representation learning. Motivated by the camera-aware distance rectification in single-modality re-ID, we propose modality-aware Jaccard distance to mitigate the distance bias caused by modality discrepancy, so that more reliable cross-modality associations can be estimated through global clustering. To further improve cross-modality representation learning, a `split-and-contrast' strategy is designed to obtain modality-specific global prototypes. By explicitly aligning these prototypes under global association guidance, modality-invariant yet ID-discriminative representation learning can be achieved. While conceptually simple, our method obtains state-of-the-art performance on benchmark VI-ReID datasets and outperforms existing methods by a significant margin, validating its effectiveness.
06 Dec 2025
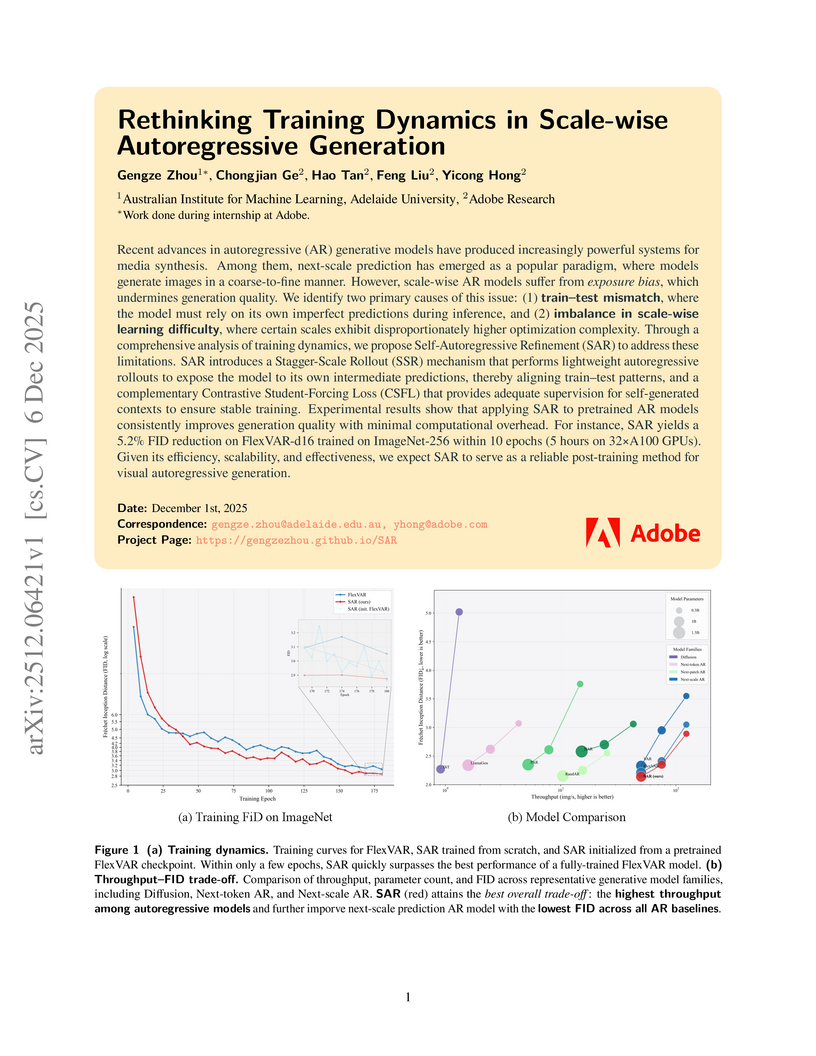
Self-Autoregressive Refinement (SAR) from AIML and Adobe Research enhances scale-wise autoregressive visual generation models by mitigating exposure bias and balancing learning difficulty through controlled student-forcing. This post-training algorithm consistently reduced FID scores on ImageNet-1K (e.g., a 5.2% reduction for the 310M FlexVAR model), establishing improved performance within its model category while requiring minimal additional computation.

09 Dec 2025
Repulsor accelerates the training of denoising generative models like diffusion models by integrating a contrastive memory bank, enabling up to 5x faster convergence and state-of-the-art image generation quality on ImageNet-256 with significantly fewer training steps than prior methods. It enhances the discriminative power of internal representations without external encoders or increased inference cost.

09 Dec 2025


Predicting diseases solely from patient-side information, such as demographics and self-reported symptoms, has attracted significant research attention due to its potential to enhance patient awareness, facilitate early healthcare engagement, and improve healthcare system efficiency. However, existing approaches encounter critical challenges, including imbalanced disease distributions and a lack of interpretability, resulting in biased or unreliable predictions. To address these issues, we propose the Knowledge graph-enhanced, Prototype-aware, and Interpretable (KPI) framework. KPI systematically integrates structured and trusted medical knowledge into a unified disease knowledge graph, constructs clinically meaningful disease prototypes, and employs contrastive learning to enhance predictive accuracy, which is particularly important for long-tailed diseases. Additionally, KPI utilizes large language models (LLMs) to generate patient-specific, medically relevant explanations, thereby improving interpretability and reliability. Extensive experiments on real-world datasets demonstrate that KPI outperforms state-of-the-art methods in predictive accuracy and provides clinically valid explanations that closely align with patient narratives, highlighting its practical value for patient-centered healthcare delivery.

08 Dec 2025
Cross-modal learning has become a fundamental paradigm for integrating heterogeneous information sources such as images, text, and structured attributes. However, multimodal representations often suffer from modality dominance, redundant information coupling, and spurious cross-modal correlations, leading to suboptimal generalization and limited interpretability. In particular, high-variance modalities tend to overshadow weaker but semantically important signals, while naïve fusion strategies entangle modality-shared and modality-specific factors in an uncontrolled manner. This makes it difficult to understand which modality actually drives a prediction and to maintain robustness when some modalities are noisy or missing. To address these challenges, we propose a Dual-Stream Residual Semantic Decorrelation Network (DSRSD-Net), a simple yet effective framework that disentangles modality-specific and modality-shared information through residual decomposition and explicit semantic decorrelation constraints. DSRSD-Net introduces: (1) a dual-stream representation learning module that separates intra-modal (private) and inter-modal (shared) latent factors via residual projection; (2) a residual semantic alignment head that maps shared factors from different modalities into a common space using a combination of contrastive and regression-style objectives; and (3) a decorrelation and orthogonality loss that regularizes the covariance structure of the shared space while enforcing orthogonality between shared and private streams, thereby suppressing cross-modal redundancy and preventing feature collapse. Experimental results on two large-scale educational benchmarks demonstrate that DSRSD-Net consistently improves next-step prediction and final outcome prediction over strong single-modality, early-fusion, late-fusion, and co-attention baselines.

10 Dec 2025
Polysomnography (PSG), the gold standard test for sleep analysis, generates vast amounts of multimodal clinical data, presenting an opportunity to leverage self-supervised representation learning (SSRL) for pre-training foundation models to enhance sleep analysis. However, progress in sleep foundation models is hindered by two key limitations: (1) the lack of a shared dataset and benchmark with diverse tasks for training and evaluation, and (2) the absence of a systematic evaluation of SSRL approaches across sleep-related tasks. To address these gaps, we introduce Stanford Sleep Bench, a large-scale PSG dataset comprising 17,467 recordings totaling over 163,000 hours from a major sleep clinic, including 13 clinical disease prediction tasks alongside canonical sleep-related tasks such as sleep staging, apnea diagnosis, and age estimation. We systematically evaluate SSRL pre-training methods on Stanford Sleep Bench, assessing downstream performance across four tasks: sleep staging, apnea diagnosis, age estimation, and disease and mortality prediction. Our results show that multiple pretraining methods achieve comparable performance for sleep staging, apnea diagnosis, and age estimation. However, for mortality and disease prediction, contrastive learning significantly outperforms other approaches while also converging faster during pretraining. To facilitate reproducibility and advance sleep research, we will release Stanford Sleep Bench along with pretrained model weights, training pipelines, and evaluation code.

09 Dec 2025
Self-supervised representation learning has shown significant improvement in Natural Language Processing and 2D Computer Vision. However, existing methods face difficulties in representing 3D data because of its unordered and uneven density. Through an in-depth analysis of mainstream contrastive and generative approaches, we find that contrastive models tend to suffer from overfitting, while 3D Mask Autoencoders struggle to handle unordered point clouds. This motivates us to learn 3D representations by sharing the merits of diffusion and contrast models, which is non-trivial due to the pattern difference between the two paradigms. In this paper, we propose \textit{PointDico}, a novel model that seamlessly integrates these methods. \textit{PointDico} learns from both denoising generative modeling and cross-modal contrastive learning through knowledge distillation, where the diffusion model serves as a guide for the contrastive model. We introduce a hierarchical pyramid conditional generator for multi-scale geometric feature extraction and employ a dual-channel design to effectively integrate local and global contextual information. \textit{PointDico} achieves a new state-of-the-art in 3D representation learning, \textit{e.g.}, \textbf{94.32\%} accuracy on ScanObjectNN, \textbf{86.5\%} Inst. mIoU on ShapeNetPart.

05 Dec 2025
Multimodal sentiment analysis (MSA) integrates various modalities, such as text, image, and audio, to provide a more comprehensive understanding of sentiment. However, effective MSA is challenged by alignment and fusion issues. Alignment requires synchronizing both temporal and semantic information across modalities, while fusion involves integrating these aligned features into a unified representation. Existing methods often address alignment or fusion in isolation, leading to limitations in performance and efficiency. To tackle these issues, we propose a novel framework called Dual-stream Alignment with Hierarchical Bottleneck Fusion (DashFusion). Firstly, dual-stream alignment module synchronizes multimodal features through temporal and semantic alignment. Temporal alignment employs cross-modal attention to establish frame-level correspondences among multimodal sequences. Semantic alignment ensures consistency across the feature space through contrastive learning. Secondly, supervised contrastive learning leverages label information to refine the modality features. Finally, hierarchical bottleneck fusion progressively integrates multimodal information through compressed bottleneck tokens, which achieves a balance between performance and computational efficiency. We evaluate DashFusion on three datasets: CMU-MOSI, CMU-MOSEI, and CH-SIMS. Experimental results demonstrate that DashFusion achieves state-of-the-art performance across various metrics, and ablation studies confirm the effectiveness of our alignment and fusion techniques. The codes for our experiments are available at this https URL.
04 Dec 2025
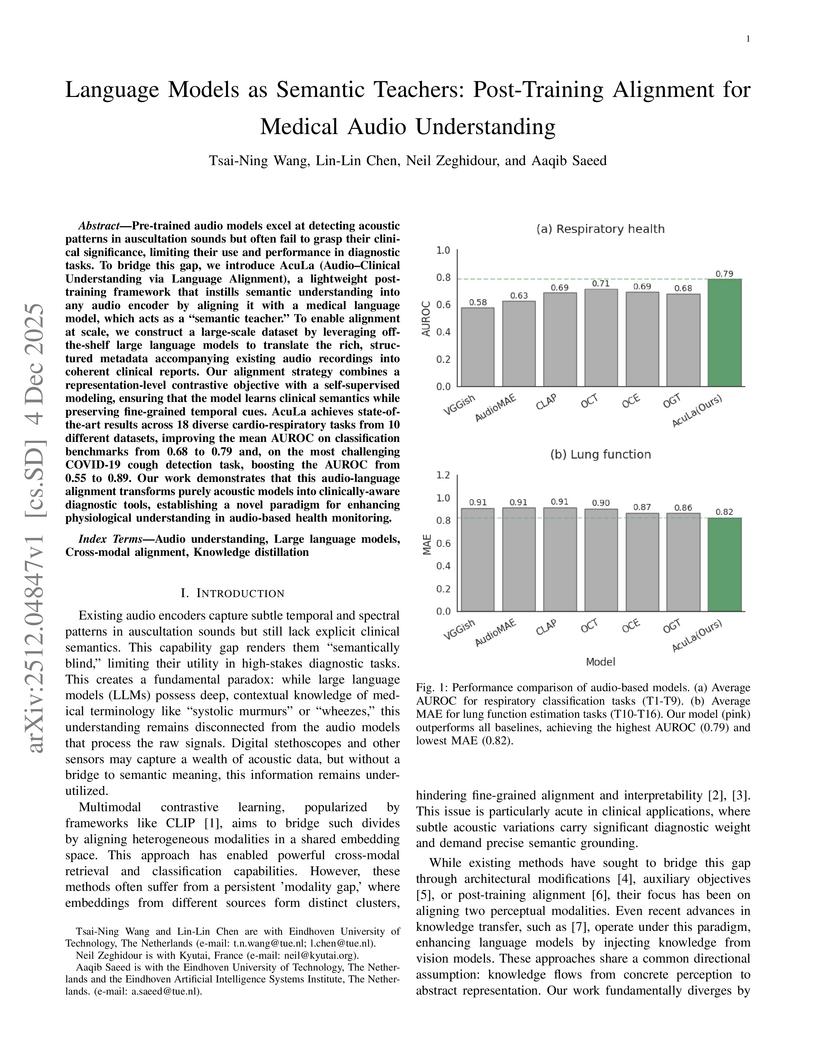
Pre-trained audio models excel at detecting acoustic patterns in auscultation sounds but often fail to grasp their clinical significance, limiting their use and performance in diagnostic tasks. To bridge this gap, we introduce AcuLa (Audio-Clinical Understanding via Language Alignment), a lightweight post-training framework that instills semantic understanding into any audio encoder by aligning it with a medical language model, which acts as a "semantic teacher." To enable alignment at scale, we construct a large-scale dataset by leveraging off-the-shelf large language models to translate the rich, structured metadata accompanying existing audio recordings into coherent clinical reports. Our alignment strategy combines a representation-level contrastive objective with a self-supervised modeling, ensuring that the model learns clinical semantics while preserving fine-grained temporal cues. AcuLa achieves state-of-the-art results across 18 diverse cardio-respiratory tasks from 10 different datasets, improving the mean AUROC on classification benchmarks from 0.68 to 0.79 and, on the most challenging COVID-19 cough detection task, boosting the AUROC from 0.55 to 0.89. Our work demonstrates that this audio-language alignment transforms purely acoustic models into clinically-aware diagnostic tools, establishing a novel paradigm for enhancing physiological understanding in audio-based health monitoring.

01 Dec 2025
The electrocardiogram (ECG) is a key diagnostic tool in cardiovascular health. Single-lead ECG recording is integrated into both clinical-grade and consumer wearables. While self-supervised pretraining of foundation models on unlabeled ECGs improves diagnostic performance, existing approaches do not incorporate domain knowledge from clinical metadata. We introduce a novel contrastive learning approach that utilizes an established clinical risk score to adaptively weight negative pairs: clinically-guided contrastive learning. It aligns the similarities of ECG embeddings with clinically meaningful differences between subjects, with an explicit mechanism to handle missing metadata. On 12-lead ECGs from 161K patients in the MIMIC-IV dataset, we pretrain single-lead ECG foundation models at three scales, collectively called CLEF, using only routinely collected metadata without requiring per-sample ECG annotations. We evaluate CLEF on 18 clinical classification and regression tasks across 7 held-out datasets, and benchmark against 5 foundation model baselines and 3 self-supervised algorithms. When pretrained on 12-lead ECG data and tested on lead-I data, CLEF outperforms self-supervised foundation model baselines: the medium-sized CLEF achieves average AUROC improvements of at least 2.6% in classification and average reductions in MAEs of at least 3.2% in regression. Comparing with existing self-supervised learning algorithms, CLEF improves the average AUROC by at least 1.8%. Moreover, when pretrained only on lead-I data for classification tasks, CLEF performs comparably to the state-of-the-art ECGFounder, which was trained in a supervised manner. Overall, CLEF enables more accurate and scalable single-lead ECG analysis, advancing remote health monitoring. Code and pretrained CLEF models are available at: this http URL.

04 Dec 2025

SEASON introduces a training-free framework that leverages temporally-hard negatives and a token-level self-diagnostic mechanism to reduce temporal and spatial hallucinations in Video Large Language Models. This approach achieves top performance on video hallucination benchmarks among inference-time methods, improving temporal sequence hallucination scores by up to 24.5% while preserving general video understanding.

01 Dec 2025

Kawamura et al. introduce PowerCLIP, a pre-training framework that aligns combinations of image regions with structured textual phrases to enhance compositional understanding in vision-language models. It achieves state-of-the-art performance, including a 7.1% average Top-1 accuracy gain over CLIP on zero-shot classification and a 4.3% average Recall@1 gain on image-text retrieval benchmarks.

05 Dec 2025
Recently, multimodal large language models (MLLMs) have been widely applied to reasoning tasks. However, they suffer from limited multi-rationale semantic modeling, insufficient logical robustness, and are susceptible to misleading interpretations in complex scenarios. Therefore, we propose a Multi-rationale INtegrated Discriminative (MIND) reasoning framework, which is designed to endow MLLMs with human-like cognitive abilities of "Understand -> Rethink -> Correct", and achieves a paradigm evolution from passive imitation-based reasoning to active discriminative reasoning. Specifically, we introduce a Rationale Augmentation and Discrimination (RAD) paradigm, which automatically and efficiently expands existing datasets by generating diverse rationales, providing a unified and extensible data foundation. Meanwhile, we design a Progressive Two-stage Correction Learning (P2CL) strategy. The first phase enhances multi-rationale positive learning, while the second phase enables active logic discrimination and correction. In addition, to mitigate representation entanglement in the multi-rationale semantic space, we propose a Multi-rationale Contrastive Alignment (MCA) optimization strategy, which achieves semantic aggregation of correct reasoning and boundary separation of incorrect reasoning. Extensive experiments demonstrate that the proposed MIND reasoning framework achieves state-of-the-art (SOTA) performance on multiple public datasets covering scientific, commonsense, and mathematical scenarios. It provides a new perspective for advancing MLLMs towards higher levels of cognitive intelligence. Our code is available at this https URL

03 Dec 2025
M3DR, developed by CognitiveLab, presents a framework for universal multilingual multimodal document retrieval across 22 diverse languages, achieving a 152% relative improvement in cross-lingual retrieval (NDCG@5) over baselines and maintaining strong English performance through synthetic data generation and efficient VLM-based models.

04 Dec 2025
This extended abstract introduces Self-Explaining Contrastive Evidence Re-Ranking (CER), a novel method that restructures retrieval around factual evidence by fine-tuning embeddings with contrastive learning and generating token-level attribution rationales for each retrieved passage. Hard negatives are automatically selected using a subjectivity-based criterion, forcing the model to pull factual rationales closer while pushing subjective or misleading explanations apart. As a result, the method creates an embedding space explicitly aligned with evidential reasoning. We evaluated our method on clinical trial reports, and initial experimental results show that CER improves retrieval accuracy, mitigates the potential for hallucinations in RAG systems, and provides transparent, evidence-based retrieval that enhances reliability, especially in safety-critical domains.

04 Dec 2025
Speech emotion recognition (SER) is an important technology in human-computer interaction. However, achieving high performance is challenging due to emotional complexity and scarce annotated data. To tackle these challenges, we propose a multi-loss learning (MLL) framework integrating an energy-adaptive mixup (EAM) method and a frame-level attention module (FLAM). The EAM method leverages SNR-based augmentation to generate diverse speech samples capturing subtle emotional variations. FLAM enhances frame-level feature extraction for multi-frame emotional cues. Our MLL strategy combines Kullback-Leibler divergence, focal, center, and supervised contrastive loss to optimize learning, address class imbalance, and improve feature separability. We evaluate our method on four widely used SER datasets: IEMOCAP, MSP-IMPROV, RAVDESS, and SAVEE. The results demonstrate our method achieves state-of-the-art performance, suggesting its effectiveness and robustness.
There are no more papers matching your filters at the moment.
