06 Dec 2025
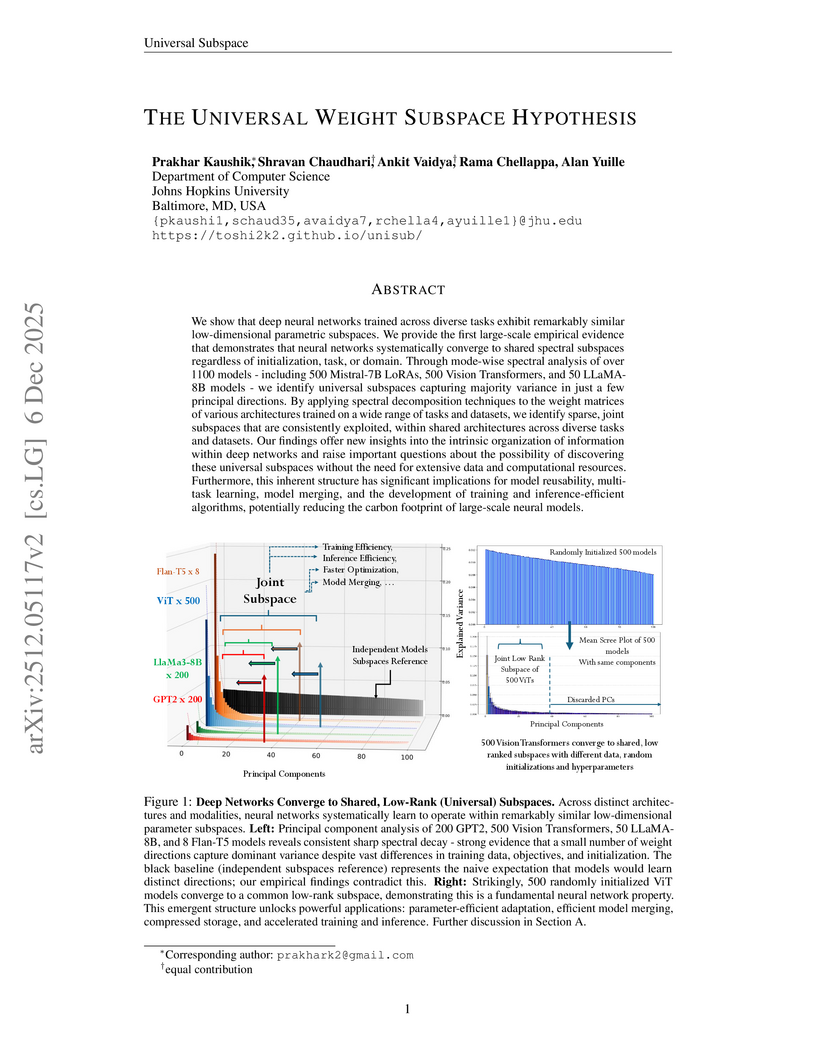
This paper presents the Universal Weight Subspace Hypothesis, demonstrating empirically that deep neural networks trained across diverse tasks and modalities converge to shared low-dimensional parametric subspaces. This convergence enables significant memory savings, such as up to 100x for Vision Transformers and LLaMA models, and 19x for LoRA adapters, while preserving model performance and enhancing efficiency in model merging and adaptation.

10 Dec 2025

Recent research has developed several LLM architectures suitable for inference on end-user devices, such as the Mixture of Lookup Experts (MoLE)~\parencite{jie_mixture_2025}. A key feature of MoLE is that each token id is associated with a dedicated group of experts. For a given input, only the experts corresponding to the input token id will be activated. Since the communication overhead of loading this small number of activated experts into RAM during inference is negligible, expert parameters can be offloaded to storage, making MoLE suitable for resource-constrained devices. However, MoLE's context-independent expert selection mechanism, based solely on input ids, may limit model performance. To address this, we propose the \textbf{M}ixture \textbf{o}f \textbf{L}ookup \textbf{K}ey-\textbf{V}alue Experts (\textbf{MoLKV}) model. In MoLKV, each expert is structured as a key-value pair. For a given input, the input-derived query interacts with the cached key-value experts from the current sequence, generating a context-aware expert output. This context-aware mechanism alleviates the limitation of MoLE, and experimental results demonstrate that MoLKV achieves significantly lower validation loss in small-scale evaluations.

09 Dec 2025
LLM agents are widely deployed in complex interactive tasks, yet privacy constraints often preclude centralized optimization and co-evolution across dynamic environments. While Federated Learning (FL) has proven effective on static datasets, its extension to the open-ended self-evolution of agents remains underexplored. Directly applying standard FL is challenging: heterogeneous tasks and sparse, trajectory-level rewards introduce severe gradient conflicts, destabilizing the global optimization process. To bridge this gap, we propose Fed-SE, a Federated Self-Evolution framework for LLM agents. Fed-SE establishes a local evolution-global aggregation paradigm. Locally, agents employ parameter-efficient fine-tuning on filtered, high-return trajectories to achieve stable gradient updates. Globally, Fed-SE aggregates updates within a low-rank subspace that disentangles environment-specific dynamics, effectively reducing negative transfer across clients. Experiments across five heterogeneous environments demonstrate that Fed-SE improves average task success rates by approximately 18% over federated baselines, validating its effectiveness in robust cross-environment knowledge transfer in privacy-constrained deployments.

03 Dec 2025
The Qwen Team at Alibaba Inc. developed a theoretical formulation that justifies token-level optimization for sequence-level rewards in Large Language Model (LLM) reinforcement learning, identifying training–inference discrepancy and policy staleness as key instability factors. Their work also provides empirically validated strategies, including Routing Replay and clipping, to achieve stable and high-performing RL training for Mixture-of-Experts (MoE) LLMs.

05 Dec 2025
This research from NYU develops and validates hyperparameter scaling rules for matrix-preconditioned optimizers like Muon and Shampoo, enabling consistent speedups of 1.3x to 1.4x over AdamW for large language models. The work provides a framework for reliably comparing and deploying advanced optimizers at scale by showing how proper hyperparameter transfer unlocks their full compute-efficiency potential.

09 Dec 2025



Recent research in Vision-Language Models (VLMs) has significantly advanced our capabilities in cross-modal reasoning. However, existing methods suffer from performance degradation with domain changes or require substantial computational resources for fine-tuning in new domains. To address this issue, we develop a new adaptation method for large vision-language models, called \textit{Training-free Dual Hyperbolic Adapters} (T-DHA). We characterize the vision-language relationship between semantic concepts, which typically has a hierarchical tree structure, in the hyperbolic space instead of the traditional Euclidean space. Hyperbolic spaces exhibit exponential volume growth with radius, unlike the polynomial growth in Euclidean space. We find that this unique property is particularly effective for embedding hierarchical data structures using the Poincaré ball model, achieving significantly improved representation and discrimination power. Coupled with negative learning, it provides more accurate and robust classifications with fewer feature dimensions. Our extensive experimental results on various datasets demonstrate that the T-DHA method significantly outperforms existing state-of-the-art methods in few-shot image recognition and domain generalization tasks.

08 Dec 2025
Large language models (LLMs) possess vast knowledge acquired from extensive training corpora, but they often cannot remove specific pieces of information when needed, which makes it hard to handle privacy, bias mitigation, and knowledge correction. Traditional model unlearning approaches require computationally expensive fine-tuning or direct weight editing, making them impractical for real-world deployment. In this work, we introduce LoRA-based Unlearning with Negative Examples (LUNE), a lightweight framework that performs negative-only unlearning by updating only low-rank adapters while freezing the backbone, thereby localizing edits and avoiding disruptive global changes. Leveraging Low-Rank Adaptation (LoRA), LUNE targets intermediate representations to suppress (or replace) requested knowledge with an order-of-magnitude lower compute and memory than full fine-tuning or direct weight editing. Extensive experiments on multiple factual unlearning tasks show that LUNE: (I) achieves effectiveness comparable to full fine-tuning and memory-editing methods, and (II) reduces computational cost by about an order of magnitude.

10 Dec 2025
Continual learning in Neural Machine Translation (NMT) faces the dual challenges of catastrophic forgetting and the high computational cost of retraining. This study establishes Low-Rank Adaptation (LoRA) as a parameter-efficient framework to address these challenges in dedicated NMT architectures. We first demonstrate that LoRA-based fine-tuning adapts NMT models to new languages and domains with performance on par with full-parameter techniques, while utilizing only a fraction of the parameter space. Second, we propose an interactive adaptation method using a calibrated linear combination of LoRA modules. This approach functions as a gate-free mixture of experts, enabling real-time, user-controllable adjustments to domain and style without retraining. Finally, to mitigate catastrophic forgetting, we introduce a novel gradient-based regularization strategy specifically designed for low-rank decomposition matrices. Unlike methods that regularize the full parameter set, our approach weights the penalty on the low-rank updates using historical gradient information. Experimental results indicate that this strategy efficiently preserves prior domain knowledge while facilitating the acquisition of new tasks, offering a scalable paradigm for interactive and continual NMT.

08 Dec 2025
Pre-training decoder-only language models relies on vast amounts of high-quality data, yet the availability of such data is increasingly reaching its limits. While metadata is commonly used to create and curate these datasets, its potential as a direct training signal remains under-explored. We challenge this status quo and propose LIME (Linguistic Metadata Embeddings), a method that enriches token embeddings with metadata capturing syntax, semantics, and contextual properties. LIME substantially improves pre-training efficiency. Specifically, it adapts up to 56% faster to the training data distribution, while introducing only 0.01% additional parameters at negligible compute overhead. Beyond efficiency, LIME improves tokenization, leading to remarkably stronger language modeling capabilities and generative task performance. These benefits persist across model scales (500M to 2B). In addition, we develop a variant with shifted metadata, LIME+1, that can guide token generation. Given prior metadata for the next token, LIME+1 improves reasoning performance by up to 38% and arithmetic accuracy by up to 35%.

09 Dec 2025
With the rise of Large Language Models (LLMs) such as GPT-3, these models exhibit strong generalization capabilities. Through transfer learning techniques such as fine-tuning and prompt tuning, they can be adapted to various downstream tasks with minimal parameter adjustments. This approach is particularly common in the field of Natural Language Processing (NLP). This paper aims to explore the effectiveness of common prompt tuning methods in 3D object detection. We investigate whether a model trained on the large-scale Waymo dataset can serve as a foundation model and adapt to other scenarios within the 3D object detection field. This paper sequentially examines the impact of prompt tokens and prompt generators, and further proposes a Scene-Oriented Prompt Pool (\textbf{SOP}). We demonstrate the effectiveness of prompt pools in 3D object detection, with the goal of inspiring future researchers to delve deeper into the potential of prompts in the 3D field.

08 Dec 2025
Large language models (LLMs) have demonstrated remarkable performance due to their large parameter counts and extensive training data. However, their scale leads to significant memory bottlenecks during training, especially when using memory-intensive optimizers like Adam. Existing memory-efficient approaches often rely on techniques such as singular value decomposition (SVD), projections, or weight freezing, which can introduce substantial computational overhead, require additional memory for projections, or degrade model performance. In this paper, we propose Folded Optimizer with Approximate Moment (FOAM), a method that compresses optimizer states by computing block-wise gradient means and incorporates a residual correction to recover lost information. Theoretically, FOAM achieves convergence rates equivalent to vanilla Adam under standard non-convex optimization settings. Empirically, FOAM reduces total training memory by approximately 50\%, eliminates up to 90\% of optimizer state memory overhead, and accelerates convergence. Furthermore, FOAM is compatible with other memory-efficient optimizers, delivering performance and throughput that match or surpass both full-rank and existing memory-efficient baselines.

08 Dec 2025
Background: The deployment of personalized Large Language Models (LLMs) is currently constrained by the stability-plasticity dilemma. Prevailing alignment methods, such as Supervised Fine-Tuning (SFT), rely on stochastic weight updates that often incur an "alignment tax" -- degrading general reasoning capabilities.
Methods: We propose the Soul Engine, a framework based on the Linear Representation Hypothesis, which posits that personality traits exist as orthogonal linear subspaces. We introduce SoulBench, a dataset constructed via dynamic contextual sampling. Using a dual-head architecture on a frozen Qwen-2.5 base, we extract disentangled personality vectors without modifying the backbone weights.
Results: Our experiments demonstrate three breakthroughs. First, High-Precision Profiling: The model achieves a Mean Squared Error (MSE) of 0.011 against psychological ground truth. Second, Geometric Orthogonality: T-SNE visualization confirms that personality manifolds are distinct and continuous, allowing for "Zero-Shot Personality Injection" that maintains original model intelligence. Third, Deterministic Steering: We achieve robust control over behavior via vector arithmetic, validated through extensive ablation studies.
Conclusion: This work challenges the necessity of fine-tuning for personalization. By transitioning from probabilistic prompting to deterministic latent intervention, we provide a mathematically rigorous foundation for safe, controllable AI personalization.

04 Dec 2025

Semantic Soft Bootstrapping (SSB), an RL-free self-distillation framework developed at the University of Maryland, enhances large language model reasoning by having the model act as both teacher and student. It boosted pass@1 accuracy on the MATH500 benchmark by 10.6% and on AIME2024 by 10% over a GRPO baseline, while utilizing a smaller dataset and maintaining concise response lengths.

06 Dec 2025
Diffusion Transformers (DiTs) have emerged as a highly scalable and effective backbone for image generation, outperforming U-Net architectures in both scalability and performance. However, their real-world deployment remains challenging due to high computational and memory demands. Mixed-Precision Quantization (MPQ), designed to push the limits of quantization, has demonstrated remarkable success in advancing U-Net quantization to sub-4bit settings while significantly reducing computational and memory overhead. Nevertheless, its application to DiT architectures remains limited and underexplored. In this work, we propose TreeQ, a unified framework addressing key challenges in DiT quantization. First, to tackle inefficient search and proxy misalignment, we introduce Tree Structured Search (TSS). This DiT-specific approach leverages the architecture's linear properties to traverse the solution space in O(n) time while improving objective accuracy through comparison-based pruning. Second, to unify optimization objectives, we propose Environmental Noise Guidance (ENG), which aligns Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT) configurations using a single hyperparameter. Third, to mitigate information bottlenecks in ultra-low-bit regimes, we design the General Monarch Branch (GMB). This structured sparse branch prevents irreversible information loss, enabling finer detail generation. Through extensive experiments, our TreeQ framework demonstrates state-of-the-art performance on DiT-XL/2 under W3A3 and W4A4 PTQ/PEFT settings. Notably, our work is the first to achieve near-lossless 4-bit PTQ performance on DiT models. The code and models will be available at this https URL

05 Dec 2025
Researchers at the University of Science and Technology Beijing introduced Group Orthogonal Low-Rank Adaptation (GOLA), a parameter-efficient fine-tuning framework that mitigates redundancy in the low-rank space of existing LoRA methods for RGB-T tracking. GOLA achieves state-of-the-art performance across multiple RGB-T benchmarks, such as 92.8% MPR on RGBT234, while reducing trainable parameters by 23% and maintaining efficient inference speeds of 125 fps.

04 Dec 2025

MemLoRA introduces a framework for deploying memory-augmented conversational AI systems directly on edge devices by distilling specialized expert adapters into small language models. This approach reduces memory and computational costs by 10-20x while achieving performance comparable to cloud-based large models, and MemLoRA-V further enables native visual understanding with high accuracy.

05 Dec 2025


Researchers from HKUST, Moffett AI, and ByteDance Seed developed SQ-format, a unified sparse-quantized hardware-friendly data format for Large Language Models (LLMs). This format enables a 1.71x inference speedup for Llama-3-70B while maintaining accuracy and reduces the total silicon area for dedicated hardware units by 35.8%.

06 Dec 2025
Pruning and quantization techniques have been broadly successful in reducing the number of parameters needed for large neural networks, yet theoretical justification for their empirical success falls short. We consider a randomized greedy compression algorithm for pruning and quantization post-training and use it to rigorously show the existence of pruned/quantized subnetworks of multilayer perceptrons (MLPs) with competitive performance. We further extend our results to structured pruning of MLPs and convolutional neural networks (CNNs), thus providing a unified analysis of pruning in wide networks. Our results are free of data assumptions, and showcase a tradeoff between compressibility and network width. The algorithm we consider bears some similarities with Optimal Brain Damage (OBD) and can be viewed as a post-training randomized version of it. The theoretical results we derive bridge the gap between theory and application for pruning/quantization, and provide a justification for the empirical success of compression in wide multilayer perceptrons.

08 Dec 2025
This work introduces Concrete Ticket Search (CTS), an algorithm that frames lottery ticket discovery as a holistic combinatorial optimization problem, efficiently finding sparse subnetworks that preserve the training dynamics of their dense counterparts. CTS, particularly with a knowledge distillation-inspired objective, achieves accuracy comparable to or better than Iterative Magnitude Pruning (LTR) at high sparsities while drastically reducing computational overhead and robustly passing sanity checks.

08 Dec 2025
DreamerV3 is a state-of-the-art online model-based reinforcement learning (MBRL) algorithm known for remarkable sample efficiency. Concurrently, Kolmogorov-Arnold Networks (KANs) have emerged as a promising alternative to Multi-Layer Perceptrons (MLPs), offering superior parameter efficiency and interpretability. To mitigate KANs' computational overhead, variants like FastKAN leverage Radial Basis Functions (RBFs) to accelerate inference. In this work, we investigate integrating KAN architectures into the DreamerV3 framework. We introduce KAN-Dreamer, replacing specific MLP and convolutional components of DreamerV3 with KAN and FastKAN layers. To ensure efficiency within the JAX-based World Model, we implement a tailored, fully vectorized version with simplified grid management. We structure our investigation into three subsystems: Visual Perception, Latent Prediction, and Behavior Learning. Empirical evaluations on the DeepMind Control Suite (walker_walk) analyze sample efficiency, training time, and asymptotic performance. Experimental results demonstrate that utilizing our adapted FastKAN as a drop-in replacement for the Reward and Continue predictors yields performance on par with the original MLP-based architecture, maintaining parity in both sample efficiency and training speed. This report serves as a preliminary study for future developments in KAN-based world models.
There are no more papers matching your filters at the moment.
