04 Dec 2025

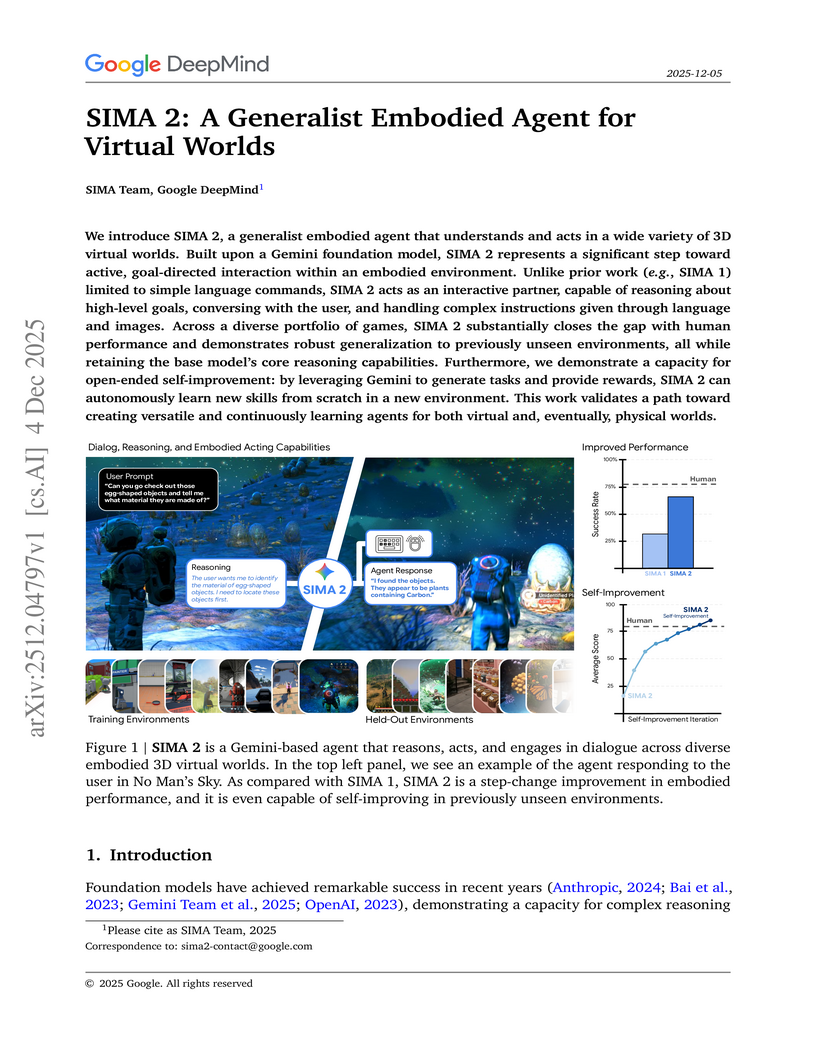
Google DeepMind developed SIMA 2, a generalist embodied agent powered by a Gemini Flash-Lite model, capable of understanding and acting in diverse 3D virtual worlds. It substantially doubles the task success rate of its predecessor SIMA 1, generalizes to unseen commercial games and photorealistic environments, and demonstrates autonomous skill acquisition through a Gemini-based self-improvement mechanism.

08 Dec 2025

Researchers from Alibaba Group and Wuhan University developed MUSE, a multimodal search-based framework for lifelong user interest modeling that integrates rich semantic information across both retrieval and fine-grained modeling stages. Deployed in Taobao's display advertising system, MUSE achieved a +12.6% CTR, +5.1% RPM, and +11.4% ROI in online A/B tests.

09 Dec 2025

RETAIN, developed at UC Berkeley, introduces a parameter merging strategy for generalist robot policies, interpolating pre-trained and finetuned weights to enable robust adaptation to new tasks. This approach enhances out-of-distribution generalization by approximately 40% on real-world robotic tasks while preserving the policy's existing broad capabilities in low-data scenarios.

09 Dec 2025
Large language models (LLMs) are post-trained through reinforcement learning (RL) to evolve into Reasoning Language Models (RLMs), where the hallmark of this advanced reasoning is ``aha'' moments when they start to perform strategies, such as self-reflection and deep thinking, within chain of thoughts (CoTs). Motivated by this, this paper proposes a novel reinforced strategy injection mechanism (rSIM), that enables any LLM to become an RLM by employing a small planner to guide the LLM's CoT through the adaptive injection of reasoning strategies. To achieve this, the planner (leader agent) is jointly trained with an LLM (follower agent) using multi-agent RL (MARL), based on a leader-follower framework and straightforward rule-based rewards. Experimental results show that rSIM enables Qwen2.5-0.5B to become an RLM and significantly outperform Qwen2.5-14B. Moreover, the planner is generalizable: it only needs to be trained once and can be applied as a plug-in to substantially improve the reasoning capabilities of existing LLMs. In addition, the planner supports continual learning across various tasks, allowing its planning abilities to gradually improve and generalize to a wider range of problems.

02 Dec 2025
Researchers from FAIR at Meta and the University of Washington developed an iterative self-training framework for Vision-Language Model (VLM) judges that operates entirely without human preference annotations. This approach allowed an 11-billion parameter VLM judge to achieve a 40.5% relative performance gain on VL-RewardBench and a 7.5% gain on Multimodal RewardBench, in some cases outperforming larger proprietary models like GPT-4o in specific evaluation dimensions.

03 Dec 2025
MemVerse, a multimodal memory framework from Shanghai Artificial Intelligence Laboratory, enables lifelong learning agents to integrate explicit, structured knowledge graphs with fast, distilled parametric memory. It achieved 85.48% accuracy on ScienceQA, improving GPT-4o-mini's baseline by nearly 9 percentage points, and boosted text-to-video retrieval R@1 by over 60 percentage points on MSR-VTT, while accelerating knowledge recall by 89% compared to RAG.

08 Dec 2025
A persistent paradox in continual learning (CL) is that neural networks often retain linearly separable representations of past tasks even when their output predictions fail. We formalize this distinction as the gap between deep feature-space and shallow classifier-level forgetting. We reveal a critical asymmetry in Experience Replay: while minimal buffers successfully anchor feature geometry and prevent deep forgetting, mitigating shallow forgetting typically requires substantially larger buffer capacities. To explain this, we extend the Neural Collapse framework to the sequential setting. We characterize deep forgetting as a geometric drift toward out-of-distribution subspaces and prove that any non-zero replay fraction asymptotically guarantees the retention of linear separability. Conversely, we identify that the "strong collapse" induced by small buffers leads to rank-deficient covariances and inflated class means, effectively blinding the classifier to true population boundaries. By unifying CL with out-of-distribution detection, our work challenges the prevailing reliance on large buffers, suggesting that explicitly correcting these statistical artifacts could unlock robust performance with minimal replay.

08 Dec 2025
Distribution shifts at test time degrade image classifiers. Recent continual test-time adaptation (CTTA) methods use masking to regulate learning, but often depend on calibrated uncertainty or stable attention scores and introduce added complexity. We ask: do we need custom-made masking designs, or can a simple random masking schedule suffice under strong corruption? We introduce Mask to Adapt (M2A), a simple CTTA approach that generates a short sequence of masked views (spatial or frequency) and adapts with two objectives: a mask consistency loss that aligns predictions across different views and an entropy minimization loss that encourages confident outputs. Motivated by masked image modeling, we study two common masking families -- spatial masking and frequency masking -- and further compare subtypes within each (spatial: patch vs.\ pixel; frequency: all vs.\ low vs.\ high). On CIFAR10C/CIFAR100C/ImageNetC (severity~5), M2A (Spatial) attains 8.3\%/19.8\%/39.2\% mean error, outperforming or matching strong CTTA baselines, while M2A (Frequency) lags behind. Ablations further show that simple random masking is effective and robust. These results indicate that a simple random masking schedule, coupled with consistency and entropy objectives, is sufficient to drive effective test-time adaptation without relying on uncertainty or attention signals.

07 Dec 2025



The DoGe framework from Shanghai Artificial Intelligence Laboratory and collaborators introduces a context-first self-evolving learning approach that decouples cognitive processes for data-scarce vision-language reasoning. It achieves stable performance improvements of 5.7% for 3B-series models and 2.3% for 7B-series models across seven benchmarks, while enhancing policy exploration and mitigating reward hacking.
02 Dec 2025
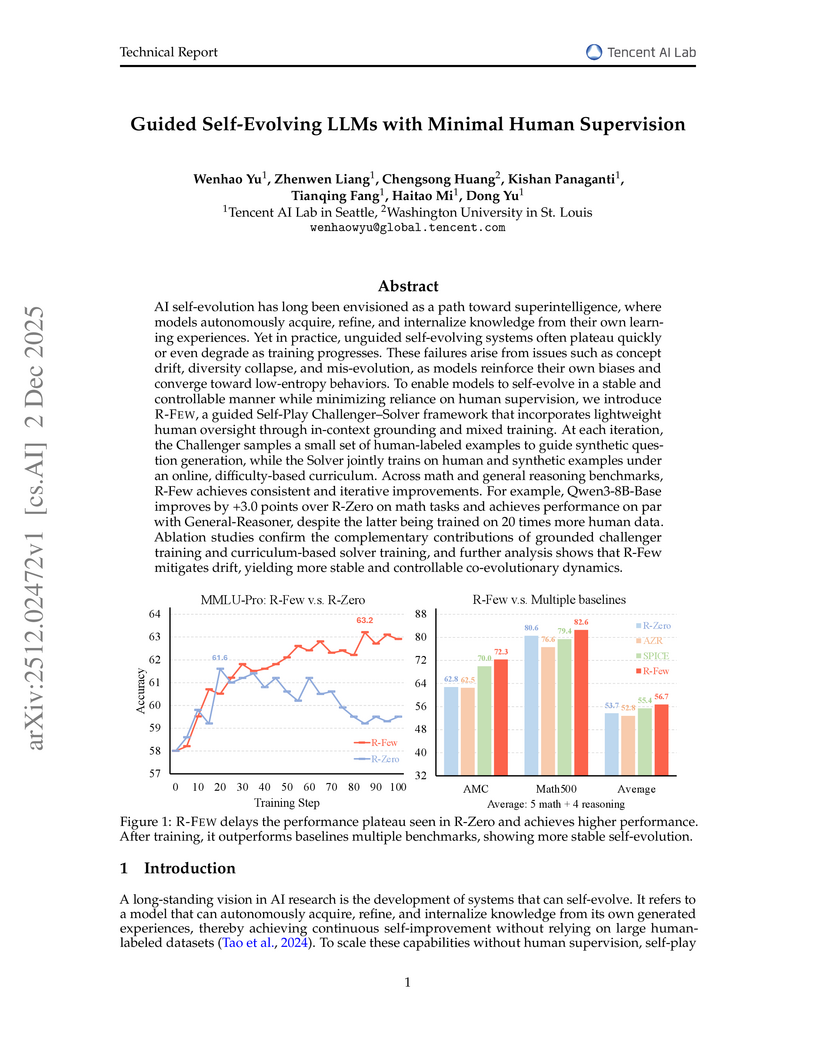
The R-FEW framework introduces a method for Large Language Models to self-evolve stably and controllably using minimal human supervision, achieving performance comparable to or surpassing models trained with 20 times more human data. It effectively mitigates issues like concept drift and diversity collapse by integrating few-shot grounding and an online curriculum.

04 Dec 2025
Researchers developed SEAL, a self-evolving agentic learning framework for conversational question answering over knowledge graphs that employs a two-stage parsing mechanism to generate structurally accurate logical forms from natural language. It reached an overall accuracy of 66.83% on the SPICE benchmark, significantly surpassing unsupervised baselines and showing strong performance on complex multi-hop, quantitative, and comparative reasoning.

09 Dec 2025
Continual Test-Time Adaptation (CTTA) enables pre-trained models to adapt to continuously evolving domains. Existing methods have improved robustness but typically rely on fixed or batch-level thresholds, which cannot account for varying difficulty across classes and instances. This limitation is especially problematic in semantic segmentation, where each image requires dense, multi-class predictions. We propose an approach that adaptively adjusts pseudo labels to reflect the confidence distribution within each image and dynamically balances learning toward classes most affected by domain shifts. This fine-grained, class- and instance-aware adaptation produces more reliable supervision and mitigates error accumulation throughout continual adaptation. Extensive experiments across eight CTTA and TTA scenarios, including synthetic-to-real and long-term shifts, show that our method consistently outperforms state-of-the-art techniques, setting a new standard for semantic segmentation under evolving conditions.

02 Dec 2025


Recent progress in multimodal large language models (MLLMs) has highlighted the challenge of efficiently bridging pre-trained Vision-Language Models (VLMs) with Diffusion Models. While methods using a fixed number of learnable query tokens offer computational efficiency, they suffer from task generalization collapse, failing to adapt to new tasks that are distant from their pre-training tasks. To overcome this, we propose Noisy Query Tokens, which learn a distributed representation space between the VLM and Diffusion Model via end-to-end optimization, enhancing continual learning. Additionally, we introduce a VAE branch with linear projection to recover fine-grained image details. Experimental results confirm our approach mitigates generalization collapse and enables stable continual learning across diverse tasks.

08 Dec 2025
Large language models have the potential to generate explanations for their own predictions in a variety of styles based on user instructions. Recent research has examined whether these self-explanations faithfully reflect the models' actual behavior and has found that they often lack faithfulness. However, the question of how to improve faithfulness remains underexplored. Moreover, because different explanation styles have superficially distinct characteristics, it is unclear whether improvements observed in one style also arise when using other styles. This study analyzes the effects of training for faithful self-explanations and the extent to which these effects generalize, using three classification tasks and three explanation styles. We construct one-word constrained explanations that are likely to be faithful using a feature attribution method, and use these pseudo-faithful self-explanations for continual learning on instruction-tuned models. Our experiments demonstrate that training can improve self-explanation faithfulness across all classification tasks and explanation styles, and that these improvements also show signs of generalization to the multi-word settings and to unseen tasks. Furthermore, we find consistent cross-style generalization among three styles, suggesting that training may contribute to a broader improvement in faithful self-explanation ability.

06 Dec 2025
The continuous growth of the global human population is leading to the expansion of human habitats, resulting in decreasing wildlife spaces and increasing human-wildlife interactions. These interactions can range from minor disturbances, such as raccoons in urban waste bins, to more severe consequences, including species extinction. As a result, the monitoring of wildlife is gaining significance in various contexts. Artificial intelligence (AI) offers a solution by automating the recognition of animals in images and videos, thereby reducing the manual effort required for wildlife monitoring. Traditional AI training involves three main stages: image collection, labelling, and model training. However, the variability, for example, in the landscape (e.g., mountains, open fields, forests), weather (e.g., rain, fog, sunshine), lighting (e.g., day, night), and camera-animal distances presents significant challenges to model robustness and adaptability in real-world scenarios.
In this work, we propose a unified framework, called ShadowWolf, designed to address these challenges by integrating and optimizing the stages of AI model training and evaluation. The proposed framework enables dynamic model retraining to adjust to changes in environmental conditions and application requirements, thereby reducing labelling efforts and allowing for on-site model adaptation. This adaptive and unified approach enhances the accuracy and efficiency of wildlife monitoring systems, promoting more effective and scalable conservation efforts.

09 Dec 2025
Despite advancements in machine learning for security, rule-based detection remains prevalent in Security Operations Centers due to the resource intensiveness and skill gap associated with ML solutions. While traditional rule-based methods offer efficiency, their rigidity leads to high false positives or negatives and requires continuous manual maintenance. This paper proposes a novel, two-stage hybrid framework to democratize ML-based threat detection. The first stage employs intentionally loose YARA rules for coarse-grained filtering, optimized for high recall. The second stage utilizes an ML classifier to filter out false positives from the first stage's output. To overcome data scarcity, the system leverages Simula, a seedless synthetic data generation framework, enabling security analysts to create high-quality training datasets without extensive data science expertise or pre-labeled examples. A continuous feedback loop incorporates real-time investigation results to adaptively tune the ML model, preventing rule degradation.
This proposed model with active learning has been rigorously tested for a prolonged time in a production environment spanning tens of thousands of systems. The system handles initial raw log volumes often reaching 250 billion events per day, significantly reducing them through filtering and ML inference to a handful of daily tickets for human investigation. Live experiments over an extended timeline demonstrate a general improvement in the model's precision over time due to the active learning feature. This approach offers a self-sustained, low-overhead, and low-maintenance solution, allowing security professionals to guide model learning as expert ``teachers''.

05 Dec 2025
This paper introduces a framework that integrates reinforcement learning (RL) with autonomous agents to enable continuous improvement in the automated process of software test cases authoring from business requirement documents within Quality Engineering (QE) workflows. Conventional systems employing Large Language Models (LLMs) generate test cases from static knowledge bases, which fundamentally limits their capacity to enhance performance over time. Our proposed Reinforcement Infused Agentic RAG (Retrieve, Augment, Generate) framework overcomes this limitation by employing AI agents that learn from QE feedback, assessments, and defect discovery outcomes to automatically improve their test case generation strategies. The system combines specialized agents with a hybrid vector-graph knowledge base that stores and retrieves software testing knowledge. Through advanced RL algorithms, specifically Proximal Policy Optimization (PPO) and Deep Q-Networks (DQN), these agents optimize their behavior based on QE-reported test effectiveness, defect detection rates, and workflow metrics. As QEs execute AI-generated test cases and provide feedback, the system learns from this expert guidance to improve future iterations. Experimental validation on enterprise Apple projects yielded substantive improvements: a 2.4% increase in test generation accuracy (from 94.8% to 97.2%), and a 10.8% improvement in defect detection rates. The framework establishes a continuous knowledge refinement loop driven by QE expertise, resulting in progressively superior test case quality that enhances, rather than replaces, human testing capabilities.

04 Dec 2025
Researchers introduced the task of Lifelong Free-text Knowledge Editing (LF-Edit) and developed EvoEdit, a method that enables large language models to continuously learn from free-text inputs while effectively preserving previously acquired knowledge. EvoEdit demonstrates enhanced knowledge acquisition and robust mitigation of catastrophic forgetting, achieving a BLEU score of 64.86 on LLaMA-3 for new knowledge after 100 edits, outperforming previous methods.

28 Nov 2025
Metacognitive Test-time Reasoning (MCTR) imbues Vision-Language Models with human-like fluid intelligence through a dual-level metacognitive architecture and test-time reinforcement learning. This framework achieves state-of-the-art zero-shot adaptation, securing 9 out of 12 top-1 results on unseen Atari games and improving average unseen performance by 275% over the SFT baseline.

25 Nov 2025
Researchers from the University of Illinois Urbana-Champaign and Google DeepMind introduced Evo-Memory, a benchmark and framework to evaluate how large language model agents learn and evolve their memory during deployment on continuous task streams. Their proposed ReMem framework demonstrated consistent performance improvements, faster adaptation, and enhanced stability across diverse single and multi-turn tasks, particularly benefiting smaller LLMs.
There are no more papers matching your filters at the moment.
