
09 Dec 2025
Terrain Diffusion introduces a diffusion-based framework for generating infinite, real-time procedural terrain, delivering highly realistic, boundless virtual worlds with seed-consistency and constant-time random access. The system achieves competitive FID scores and real-time generation latency on consumer hardware, demonstrating its practical applicability.

08 Dec 2025


A new framework, Distribution Matching Variational AutoEncoder (DMVAE), explicitly aligns a VAE's aggregate latent distribution with a pre-defined reference distribution using score-based matching. The approach achieves a state-of-the-art gFID of 1.82 on ImageNet 256x256, demonstrating superior training efficiency for downstream generative models, particularly when utilizing Self-Supervised Learning features as the reference.

10 Dec 2025

The H2R-Grounder framework enables the translation of human interaction videos into physically grounded robot manipulation videos without requiring paired human-robot demonstration data. Researchers at the National University of Singapore's Show Lab developed this approach, which utilizes a simple 2D pose representation and fine-tunes a video diffusion model on unpaired robot videos, achieving higher human preference for motion consistency (54.5%), physical plausibility (63.6%), and visual quality (61.4%) compared to baseline methods.

10 Dec 2025
FALCON introduces a flow-based generative model that enables few-step sampling with accurate likelihoods, addressing the computational bottleneck in Boltzmann Generators for molecular conformation sampling. The model achieves two orders of magnitude faster inference compared to continuous normalizing flows (CNFs) and demonstrates superior performance on larger peptide systems, including tri-alanine and hexa-alanine.

09 Dec 2025
Understanding how the human brain represents visual concepts, and in which brain regions these representations are encoded, remains a long-standing challenge. Decades of work have advanced our understanding of visual representations, yet brain signals remain large and complex, and the space of possible visual concepts is vast. As a result, most studies remain small-scale, rely on manual inspection, focus on specific regions and properties, and rarely include systematic validation. We present a large-scale, automated framework for discovering and explaining visual representations across the human cortex. Our method comprises two main stages. First, we discover candidate interpretable patterns in fMRI activity through unsupervised, data-driven decomposition methods. Next, we explain each pattern by identifying the set of natural images that most strongly elicit it and generating a natural-language description of their shared visual meaning. To scale this process, we introduce an automated pipeline that tests multiple candidate explanations, assigns quantitative reliability scores, and selects the most consistent description for each voxel pattern. Our framework reveals thousands of interpretable patterns spanning many distinct visual concepts, including fine-grained representations previously unreported.
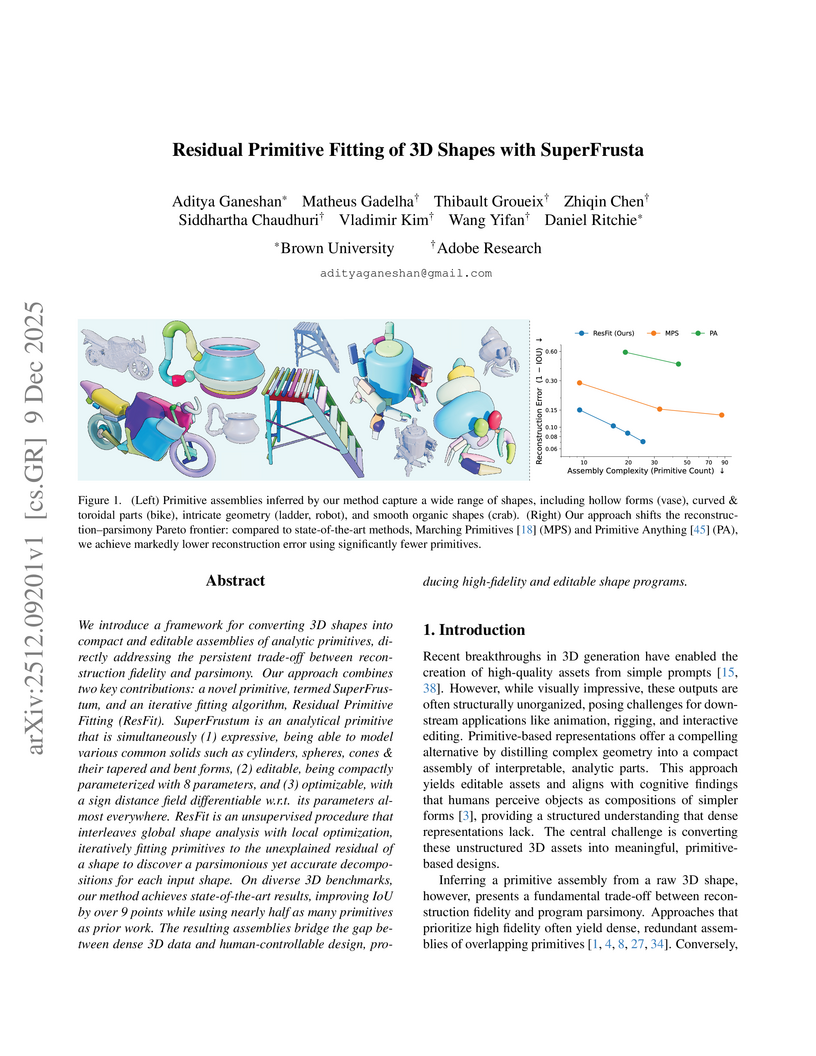
09 Dec 2025


Researchers from Brown University and Adobe Research developed a framework featuring the SuperFrustum primitive and ResFit algorithm to convert unstructured 3D shapes into compact, editable primitive assemblies. The method achieved over 9 points higher IoU on the Toys4K dataset and used nearly half the primitives compared to prior state-of-the-art techniques.

10 Dec 2025
Recent advances in diffusion-based generative models have achieved remarkable visual fidelity, yet a detailed understanding of how specific perceptual attributes - such as color and shape - are internally represented remains limited. This work explores how color is encoded in a generative model through a systematic analysis of the latent representations in Stable Diffusion. Through controlled synthetic datasets, principal component analysis (PCA) and similarity metrics, we reveal that color information is encoded along circular, opponent axes predominantly captured in latent channels c_3 and c_4, whereas intensity and shape are primarily represented in channels c_1 and c_2. Our findings indicate that the latent space of Stable Diffusion exhibits an interpretable structure aligned with a efficient coding representation. These insights provide a foundation for future work in model understanding, editing applications, and the design of more disentangled generative frameworks.

08 Dec 2025
Radio frequency (RF)-based indoor localization offers significant promise for applications such as indoor navigation, augmented reality, and pervasive computing. While deep learning has greatly enhanced localization accuracy and robustness, existing localization models still face major challenges in cross-scene generalization due to their reliance on scene-specific labeled data. To address this, we introduce Radiance-Field Reinforced Pretraining (RFRP). This novel self-supervised pretraining framework couples a large localization model (LM) with a neural radio-frequency radiance field (RF-NeRF) in an asymmetrical autoencoder architecture. In this design, the LM encodes received RF spectra into latent, position-relevant representations, while the RF-NeRF decodes them to reconstruct the original spectra. This alignment between input and output enables effective representation learning using large-scale, unlabeled RF data, which can be collected continuously with minimal effort. To this end, we collected RF samples at 7,327,321 positions across 100 diverse scenes using four common wireless technologies--RFID, BLE, WiFi, and IIoT. Data from 75 scenes were used for training, and the remaining 25 for evaluation. Experimental results show that the RFRP-pretrained LM reduces localization error by over 40% compared to non-pretrained models and by 21% compared to those pretrained using supervised learning.

10 Dec 2025
We examine the non-asymptotic properties of robust density ratio estimation (DRE) in contaminated settings. Weighted DRE is the most promising among existing methods, exhibiting doubly strong robustness from an asymptotic perspective. This study demonstrates that Weighted DRE achieves sparse consistency even under heavy contamination within a non-asymptotic framework. This method addresses two significant challenges in density ratio estimation and robust estimation. For density ratio estimation, we provide the non-asymptotic properties of estimating unbounded density ratios under the assumption that the weighted density ratio function is bounded. For robust estimation, we introduce a non-asymptotic framework for doubly strong robustness under heavy contamination, assuming that at least one of the following conditions holds: (i) contamination ratios are small, and (ii) outliers have small weighted values. This work provides the first non-asymptotic analysis of strong robustness under heavy contamination.

10 Dec 2025
We revisit the signal denoising problem through the lens of optimal transport: the goal is to recover an unknown scalar signal distribution from noisy observations , with being standard Gaussian independent of and a known noise level. Let denote the distribution of . We introduce a hierarchy of denoisers that are agnostic to the signal distribution , depending only on higher-order score functions of . Each denoiser is progressively refined using the -th order score function of at noise resolution , achieving better denoising quality measured by the Wasserstein metric . The limiting denoiser identifies the optimal transport map with .
We provide a complete characterization of the combinatorial structure underlying this hierarchy through Bell polynomial recursions, revealing how higher-order score functions encode the optimal transport map for signal denoising. We study two estimation strategies with convergence rates for higher-order scores from i.i.d. samples drawn from : (i) plug-in estimation via Gaussian kernel smoothing, and (ii) direct estimation via higher-order score matching. This hierarchy of agnostic denoisers opens new perspectives in signal denoising and empirical Bayes.

07 Dec 2025
This survey paper elucidates how diverse machine learning tasks, including generative modeling and network optimization, can be framed as the evolution of probability distributions over time. It provides a unified mathematical framework by connecting optimal transport and diffusion processes, clarifying their applications and distinct properties within advanced machine learning paradigms.

09 Dec 2025
Generative models of complex systems often require post-hoc parameter adjustments to produce useful outputs. For example, energy-based models for protein design are sampled at an artificially low ''temperature'' to generate novel, functional sequences. This temperature tuning is a common yet poorly understood heuristic used across machine learning contexts to control the trade-off between generative fidelity and diversity. Here, we develop an interpretable, physically motivated framework to explain this phenomenon. We demonstrate that in systems with a large ''energy gap'' - separating a small fraction of meaningful states from a vast space of unrealistic states - learning from sparse data causes models to systematically overestimate high-energy state probabilities, a bias that lowering the sampling temperature corrects. More generally, we characterize how the optimal sampling temperature depends on the interplay between data size and the system's underlying energy landscape. Crucially, our results show that lowering the sampling temperature is not always desirable; we identify the conditions where \emph{raising} it results in better generative performance. Our framework thus casts post-hoc temperature tuning as a diagnostic tool that reveals properties of the true data distribution and the limits of the learned model.

10 Dec 2025
Linear spectral mixture models (LMM) provide a concise form to disentangle the constituent materials (endmembers) and their corresponding proportions (abundance) in a single pixel. The critical challenges are how to model the spectral prior distribution and spectral variability. Prior knowledge and spectral variability can be rigorously modeled under the Bayesian framework, where posterior estimation of Abundance is derived by combining observed data with endmember prior distribution. Considering the key challenges and the advantages of the Bayesian framework, a novel method using a diffusion posterior sampler for semiblind unmixing, denoted as DPS4Un, is proposed to deal with these challenges with the following features: (1) we view the pretrained conditional spectrum diffusion model as a posterior sampler, which can combine the learned endmember prior with observation to get the refined abundance distribution. (2) Instead of using the existing spectral library as prior, which may raise bias, we establish the image-based endmember bundles within superpixels, which are used to train the endmember prior learner with diffusion model. Superpixels make sure the sub-scene is more homogeneous. (3) Instead of using the image-level data consistency constraint, the superpixel-based data fidelity term is proposed. (4) The endmember is initialized as Gaussian noise for each superpixel region, DPS4Un iteratively updates the abundance and endmember, contributing to spectral variability modeling. The experimental results on three real-world benchmark datasets demonstrate that DPS4Un outperforms the state-of-the-art hyperspectral unmixing methods.

08 Dec 2025
Inspired by graph-based methodologies, we introduce a novel graph-spanning algorithm designed to identify changes in both offline and online data across low to high dimensions. This versatile approach is applicable to Euclidean and graph-structured data with unknown distributions, while maintaining control over error probabilities. Theoretically, we demonstrate that the algorithm achieves high detection power when the magnitude of the change surpasses the lower bound of the minimax separation rate, which scales on the order of . Our method outperforms other techniques in terms of accuracy for both Gaussian and non-Gaussian data. Notably, it maintains strong detection power even with small observation windows, making it particularly effective for online environments where timely and precise change detection is critical.

08 Dec 2025
Estimation of the conditional independence graph (CIG) of high-dimensional multivariate Gaussian time series from multi-attribute data is considered. Existing methods for graph estimation for such data are based on single-attribute models where one associates a scalar time series with each node. In multi-attribute graphical models, each node represents a random vector or vector time series. In this paper we provide a unified theoretical analysis of multi-attribute graph learning for dependent time series using a penalized log-likelihood objective function formulated in the frequency domain using the discrete Fourier transform of the time-domain data. We consider both convex (sparse-group lasso) and non-convex (log-sum and SCAD group penalties) penalty/regularization functions. We establish sufficient conditions in a high-dimensional setting for consistency (convergence of the inverse power spectral density to true value in the Frobenius norm), local convexity when using non-convex penalties, and graph recovery. We do not impose any incoherence or irrepresentability condition for our convergence results. We also empirically investigate selection of the tuning parameters based on the Bayesian information criterion, and illustrate our approach using numerical examples utilizing both synthetic and real data.

09 Dec 2025
High-resolution imagery is often hindered by limitations in sensor technology, atmospheric conditions, and costs. Such challenges occur in satellite remote sensing, but also with handheld cameras, such as our smartphones. Hence, super-resolution aims to enhance the image resolution algorithmically. Since single-image super-resolution requires solving an inverse problem, such methods must exploit strong priors, e.g. learned from high-resolution training data, or be constrained by auxiliary data, e.g. by a high-resolution guide from another modality. While qualitatively pleasing, such approaches often lead to "hallucinated" structures that do not match reality. In contrast, multi-image super-resolution (MISR) aims to improve the (optical) resolution by constraining the super-resolution process with multiple views taken with sub-pixel shifts. Here, we propose SuperF, a test-time optimization approach for MISR that leverages coordinate-based neural networks, also called neural fields. Their ability to represent continuous signals with an implicit neural representation (INR) makes them an ideal fit for the MISR task.
The key characteristic of our approach is to share an INR for multiple shifted low-resolution frames and to jointly optimize the frame alignment with the INR. Our approach advances related INR baselines, adopted from burst fusion for layer separation, by directly parameterizing the sub-pixel alignment as optimizable affine transformation parameters and by optimizing via a super-sampled coordinate grid that corresponds to the output resolution. Our experiments yield compelling results on simulated bursts of satellite imagery and ground-level images from handheld cameras, with upsampling factors of up to 8. A key advantage of SuperF is that this approach does not rely on any high-resolution training data.

01 Dec 2025



Improved Mean Flows (iMF) enhances one-step generative image models by stabilizing training through an improved objective and enabling flexible Classifier-Free Guidance. This framework achieves a 1-NFE FID of 1.72 on ImageNet 256x256 without distillation, outperforming prior fastforward methods and significantly reducing model size by one-third.
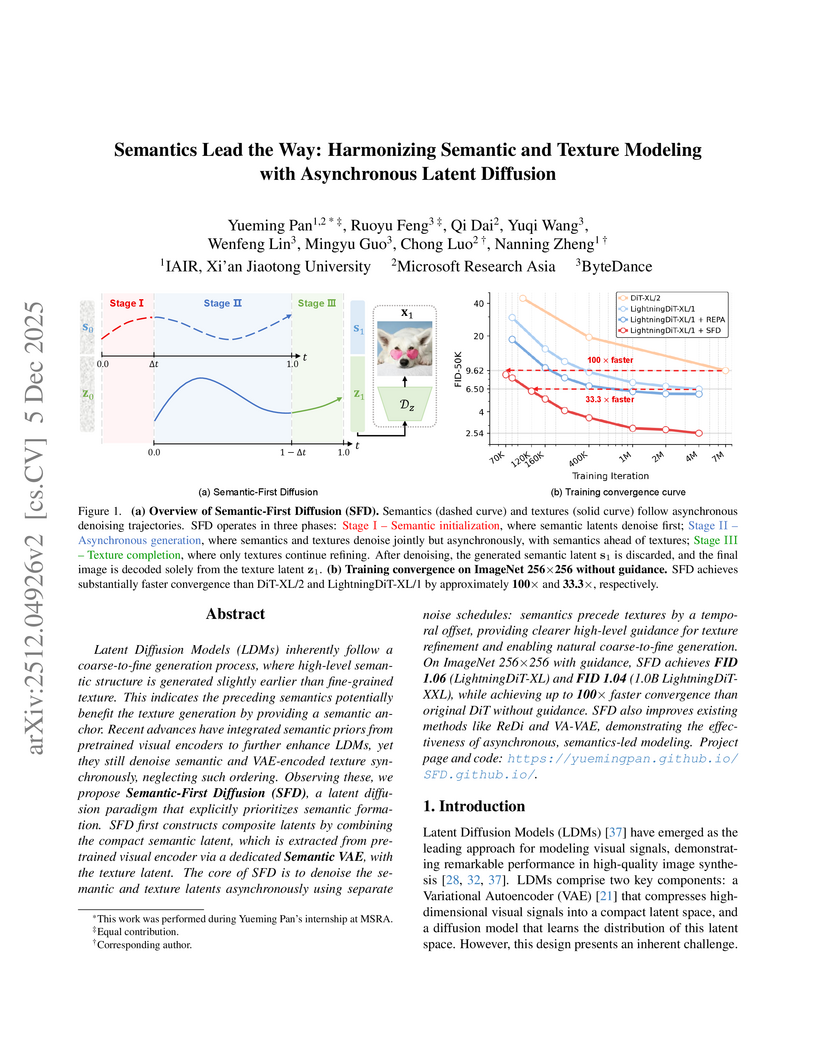
05 Dec 2025
Semantics Lead the Way: Harmonizing Semantic and Texture Modeling with Asynchronous Latent Diffusion
Semantics Lead the Way: Harmonizing Semantic and Texture Modeling with Asynchronous Latent Diffusion


Semantic-First Diffusion (SFD) introduces an asynchronous denoising paradigm for Latent Diffusion Models, prioritizing semantic structure over texture to accelerate training convergence by up to 100x and achieve new state-of-the-art image generation quality with FID 1.04 on ImageNet 256x256.

07 Dec 2025
Estimation of differences in conditional independence graphs (CIGs) of two time series Gaussian graphical models (TSGGMs) is investigated where the two TSGGMs are known to have similar structure. The TSGGM structure is encoded in the inverse power spectral density (IPSD) of the time series. In several existing works, one is interested in estimating the difference in two precision matrices to characterize underlying changes in conditional dependencies of two sets of data consisting of independent and identically distributed (i.i.d.) observations. In this paper we consider estimation of the difference in two IPSDs to characterize the underlying changes in conditional dependencies of two sets of time-dependent data. Our approach accounts for data time dependencies unlike past work. We analyze a penalized D-trace loss function approach in the frequency domain for differential graph learning, using Wirtinger calculus. We consider both convex (group lasso) and non-convex (log-sum and SCAD group penalties) penalty/regularization functions. An alternating direction method of multipliers (ADMM) algorithm is presented to optimize the objective function. We establish sufficient conditions in a high-dimensional setting for consistency (convergence of the inverse power spectral density to true value in the Frobenius norm) and graph recovery. Both synthetic and real data examples are presented in support of the proposed approaches. In synthetic data examples, our log-sum-penalized differential time-series graph estimator significantly outperformed our lasso based differential time-series graph estimator which, in turn, significantly outperformed an existing lasso-penalized i.i.d. modeling approach, with score as the performance metric.

07 Dec 2025

Gaussian Quant (GQ), developed by researchers at Tsinghua University, Zhipu AI, and the University of Cambridge, presents a training-free method to transform pre-trained Gaussian Variational Autoencoders into discrete tokenizers. This approach consistently outperforms existing VQ-VAE variants in image reconstruction across various architectures and bitrates while maintaining high codebook utilization for efficient autoregressive generation.
There are no more papers matching your filters at the moment.
