
19 May 2025

MeanFlow, developed by researchers at CMU and MIT, introduces a generative modeling framework based on learning "average velocity" to enable efficient one-step image generation. The model achieves an FID of 3.43 with a single function evaluation on ImageNet 256x256, demonstrating improved performance over prior one-step methods and approaching the quality of multi-step diffusion models.

01 Dec 2025



Improved Mean Flows (iMF) enhances one-step generative image models by stabilizing training through an improved objective and enabling flexible Classifier-Free Guidance. This framework achieves a 1-NFE FID of 1.72 on ImageNet 256x256 without distillation, outperforming prior fastforward methods and significantly reducing model size by one-third.

08 Oct 2025


Amazon FAR researchers developed OmniRetarget, a framework that generates high-fidelity, physically plausible, and interaction-preserving kinematic trajectories from human demonstrations for humanoid robots. This approach enables the training of complex loco-manipulation and scene interaction skills with zero-shot sim-to-real transfer and a minimal reinforcement learning formulation.

30 May 2024




OSWORLD, developed by The University of Hong Kong and collaborators including Salesforce Research, introduces the first scalable benchmark for evaluating multimodal AI agents in real computer environments. It reveals a substantial performance gap between state-of-the-art models and humans on open-ended tasks, with agents achieving only 12.24% success compared to humans' 72.36%.

25 Nov 2025






Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: this https URL

18 Apr 2025




OpenHands is an open-source platform facilitating the development, evaluation, and deployment of generalist AI agents that interact with digital environments by writing code, using command lines, and browsing the web. Its CodeAct agent achieved competitive performance across 15 diverse benchmarks, including software engineering, web browsing, and general assistance tasks, without task-specific modifications.

21 Apr 2025








DataComp-LM introduces a standardized, large-scale benchmark for evaluating language model training data curation strategies, complete with an openly released corpus, framework, and models. Its DCLM-BASELINE 7B model, trained on carefully filtered Common Crawl data, achieves 64% MMLU 5-shot accuracy, outperforming previous open-data state-of-the-art models while requiring substantially less compute.

30 Oct 2025


Supervised fine-tuning (SFT) has become the de facto post-training strategy for large vision-language-action (VLA) models, but its reliance on costly human demonstrations limits scalability and generalization. We propose Probe, Learn, Distill (PLD), a three-stage plug-and-play framework that improves VLAs through residual reinforcement learning (RL) and distribution-aware data collection. In Stage 1, we train lightweight residual actors to probe failure regions of the VLA generalist. In Stage 2, we use a hybrid rollout scheme that aligns collected trajectories with the generalist's deployment distribution while capturing recovery behaviors. In Stage 3, we distill the curated trajectories back into the generalist with standard SFT. PLD achieves near-saturated 99% task success on LIBERO, over 50% gains in SimplerEnv, and 100% success on real-world Franka and YAM arm manipulation tasks. Ablations show that residual probing and distribution-aware replay are key to collecting deployment-aligned data that improves both seen and unseen tasks, offering a scalable path toward self-improving VLA models.

22 Sep 2025
D-REX introduces a new benchmark for detecting deceptive reasoning in large language models, where models generate benign outputs while their internal thought processes execute malicious instructions. This benchmark, built from competitive red-teaming, reveals that current frontier models are highly susceptible to such attacks, highlighting the limitations of output-centric safety evaluations.

08 Nov 2025
SVDQuant introduces a 4-bit post-training quantization method for diffusion models that absorbs outliers using a high-precision low-rank component, coupled with the Nunchaku inference engine. This approach enables state-of-the-art image quality while achieving up to 3.6x memory reduction and 10.1x end-to-end inference speedup across various models and hardware.
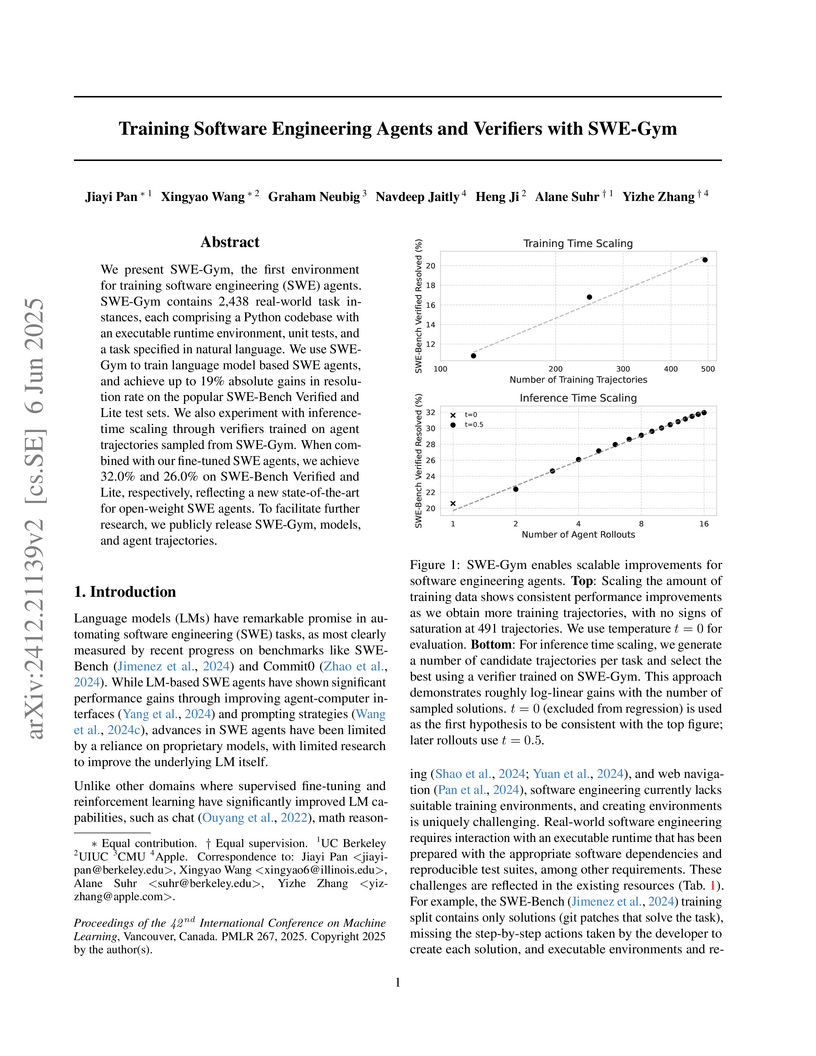
06 Jun 2025

SWE-Gym is introduced as the first publicly available training environment combining real-world software engineering tasks with executable test verification. Fine-tuning open-weight language models on trajectories collected within SWE-Gym enables substantial performance gains for software engineering agents and allows for effective inference-time scaling via learned verifiers.

08 Oct 2025
Amazon FAR researchers developed ResMimic, a two-stage residual learning framework that transforms general motion tracking into precise humanoid whole-body loco-manipulation. The system achieved a 92.5% average task success rate in simulation, significantly outperforming baselines, and enabled a Unitree G1 robot to carry heavy and irregularly shaped objects using whole-body contact in real-world scenarios.

17 Jan 2024

BridgeData V2 is a large-scale, diverse dataset for robot learning, comprising over 60,000 real-world robot trajectories collected across 24 environments and 13 skills using a low-cost robot. Policies trained on this dataset generalize to unseen objects and environments and can transfer to independent institutions with varied setups, demonstrating the benefits of data scale and diversity.

18 Nov 2025

A systematic analysis of multi-stage large language model training dynamics investigates how design choices across pre-training, continued pre-training, supervised fine-tuning, and reinforcement learning impact model capabilities, providing a transparent framework and introducing outcome reward model scores as a reliable proxy for generative task evaluation.

05 Oct 2025

This research introduces a cross-embodiment learning framework that leverages a large dataset of egocentric human demonstrations (PH²D) collected with consumer-grade VR to train robust humanoid robot manipulation policies. A unified Human Action Transformer (HAT) policy co-trained with human and robot data significantly improves generalization to novel objects, backgrounds, and placements by nearly 100% in out-of-distribution settings, and enables efficient few-shot transfer across different robot platforms.

17 Jun 2025


Medical Large Vision-Language Models (Med-LVLMs) have shown strong potential
in multimodal diagnostic tasks. However, existing single-agent models struggle
to generalize across diverse medical specialties, limiting their performance.
Recent efforts introduce multi-agent collaboration frameworks inspired by
clinical workflows, where general practitioners (GPs) and specialists interact
in a fixed sequence. Despite improvements, these static pipelines lack
flexibility and adaptability in reasoning. To address this, we propose
MMedAgent-RL, a reinforcement learning (RL)-based multi-agent framework that
enables dynamic, optimized collaboration among medical agents. Specifically, we
train two GP agents based on Qwen2.5-VL via RL: the triage doctor learns to
assign patients to appropriate specialties, while the attending physician
integrates the judgments from multi-specialists and its own knowledge to make
final decisions. To address the inconsistency in specialist outputs, we
introduce a curriculum learning (CL)-guided RL strategy that progressively
teaches the attending physician to balance between imitating specialists and
correcting their mistakes. Experiments on five medical VQA benchmarks
demonstrate that MMedAgent-RL not only outperforms both open-source and
proprietary Med-LVLMs, but also exhibits human-like reasoning patterns.
Notably, it achieves an average performance gain of 20.7% over supervised
fine-tuning baselines.

30 Nov 2025

The DoorMan framework, developed by researchers from NVIDIA, UC Berkeley, CMU, and CUHK, enables a humanoid robot to autonomously open diverse real-world doors using only egocentric RGB vision. This achievement results from policies trained entirely in a massively randomized, photorealistic simulation, demonstrating superior performance to human teleoperation.

27 Apr 2025


Speculative Knowledge Distillation (SKD) introduces an interleaved sampling method for LLM compression, dynamically blending teacher-guided corrections with student-generated tokens. This approach consistently outperforms existing knowledge distillation techniques, achieving substantial gains across diverse tasks and data regimes while providing more stable training.

17 Feb 2023

This work reinterprets contrastive learning as a goal-conditioned reinforcement learning algorithm, demonstrating that the inner product of learned representations can directly serve as a Q-function. The proposed Contrastive RL (CR) methods achieve superior performance on image-based and offline goal-conditioned tasks, often without requiring auxiliary representation learning losses or explicit data augmentation.

12 Aug 2024
A new approach leverages large language models (LLMs) for zero-shot time series forecasting by encoding numerical data as strings of digits, treating it as a next-token prediction task. This method, LLMTIME, demonstrated competitive performance against specialized models on various benchmarks, particularly excelling in probabilistic forecasting.
There are no more papers matching your filters at the moment.
