07 Oct 2025

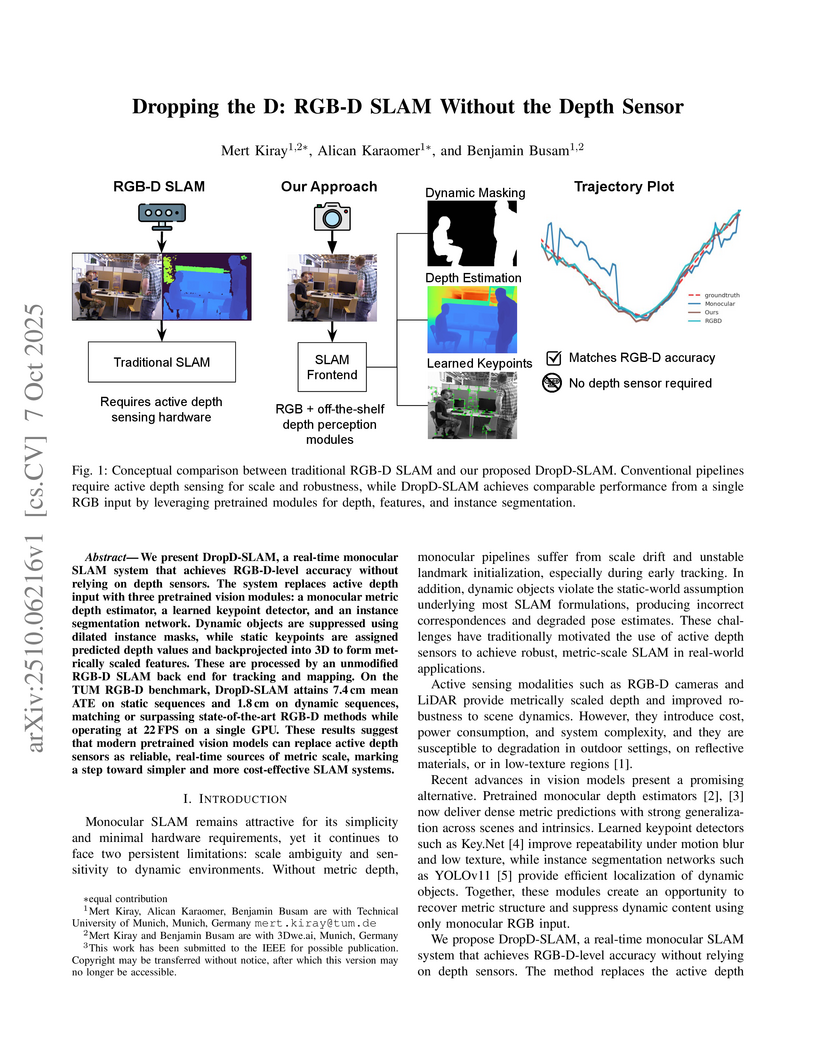
DropD-SLAM is a real-time monocular system that achieves RGB-D level accuracy and robustness by integrating pretrained deep vision models for metric depth estimation, learned keypoint detection, and instance segmentation into an unmodified classical RGB-D SLAM backend. The system achieves a mean Absolute Trajectory Error (ATE) of 2.27 cm on dynamic sequences, outperforming most existing RGB-D baselines, and operates at 22 FPS on an NVIDIA RTX 4090.

20 Aug 2025
Contrastive learning has gained significant attention in skeleton-based action recognition for its ability to learn robust representations from unlabeled data. However, existing methods rely on a single skeleton convention, which limits their ability to generalize across datasets with diverse joint structures and anatomical coverage. We propose Multi-Skeleton Contrastive Learning (MS-CLR), a general self-supervised framework that aligns pose representations across multiple skeleton conventions extracted from the same sequence. This encourages the model to learn structural invariances and capture diverse anatomical cues, resulting in more expressive and generalizable features. To support this, we adapt the ST-GCN architecture to handle skeletons with varying joint layouts and scales through a unified representation scheme. Experiments on the NTU RGB+D 60 and 120 datasets demonstrate that MS-CLR consistently improves performance over strong single-skeleton contrastive learning baselines. A multi-skeleton ensemble further boosts performance, setting new state-of-the-art results on both datasets.

01 Jun 2025
PromptVFX enables real-time text-driven 3D animation by applying time-varying field transformations directly to 3D Gaussian splats. The system allows users to generate and refine complex animations in seconds using natural language, achieving superior semantic alignment and speed compared to existing methods.

26 Mar 2023
Learning-based methods to solve dense 3D vision problems typically train on 3D sensor data. The respectively used principle of measuring distances provides advantages and drawbacks. These are typically not compared nor discussed in the literature due to a lack of multi-modal datasets. Texture-less regions are problematic for structure from motion and stereo, reflective material poses issues for active sensing, and distances for translucent objects are intricate to measure with existing hardware. Training on inaccurate or corrupt data induces model bias and hampers generalisation capabilities. These effects remain unnoticed if the sensor measurement is considered as ground truth during the evaluation. This paper investigates the effect of sensor errors for the dense 3D vision tasks of depth estimation and reconstruction. We rigorously show the significant impact of sensor characteristics on the learned predictions and notice generalisation issues arising from various technologies in everyday household environments. For evaluation, we introduce a carefully designed dataset\footnote{dataset available at this https URL} comprising measurements from commodity sensors, namely D-ToF, I-ToF, passive/active stereo, and monocular RGB+P. Our study quantifies the considerable sensor noise impact and paves the way to improved dense vision estimates and targeted data fusion.

09 Dec 2025
Object pose estimation is a fundamental task in computer vision and robotics, yet most methods require extensive, dataset-specific training. Concurrently, large-scale vision language models show remarkable zero-shot capabilities. In this work, we bridge these two worlds by introducing ConceptPose, a framework for object pose estimation that is both training-free and model-free. ConceptPose leverages a vision-language-model (VLM) to create open-vocabulary 3D concept maps, where each point is tagged with a concept vector derived from saliency maps. By establishing robust 3D-3D correspondences across concept maps, our approach allows precise estimation of 6DoF relative pose. Without any object or dataset-specific training, our approach achieves state-of-the-art results on common zero shot relative pose estimation benchmarks, significantly outperforming existing methods by over 62% in ADD(-S) score, including those that utilize extensive dataset-specific training.

21 Aug 2023
6D pose estimation pipelines that rely on RGB-only or RGB-D data show limitations for photometrically challenging objects with e.g. textureless surfaces, reflections or transparency. A supervised learning-based method utilising complementary polarisation information as input modality is proposed to overcome such limitations. This supervised approach is then extended to a self-supervised paradigm by leveraging physical characteristics of polarised light, thus eliminating the need for annotated real data. The methods achieve significant advancements in pose estimation by leveraging geometric information from polarised light and incorporating shape priors and invertible physical constraints.
There are no more papers matching your filters at the moment.
