
25 May 2019
BERT, developed by Google AI Language, introduces a deep bidirectional Transformer encoder pre-trained with Masked Language Model and Next Sentence Prediction objectives. This model established new state-of-the-art results across eleven natural language processing tasks, including an 80.5% GLUE score and a 93.2 SQuAD v1.1 F1 score, by effectively learning rich contextual representations from unlabeled text.

27 Nov 2024
Code-mixing is the practice of using two or more languages in a single sentence, which often occurs in multilingual communities such as India where people commonly speak multiple languages. Classic NLP tools, trained on monolingual data, face challenges when dealing with code-mixed data. Extracting meaningful information from sentences containing multiple languages becomes difficult, particularly in tasks like hate speech detection, due to linguistic variation, cultural nuances, and data sparsity. To address this, we aim to analyze the significance of code-mixed embeddings and evaluate the performance of BERT and HingBERT models (trained on a Hindi-English corpus) in hate speech detection. Our study demonstrates that HingBERT models, benefiting from training on the extensive Hindi-English dataset L3Cube-HingCorpus, outperform BERT models when tested on hate speech text datasets. We also found that code-mixed Hing-FastText performs better than standard English FastText and vanilla BERT models.

28 Aug 2018
We release a corpus of 43 million atomic edits across 8 languages. These edits are mined from Wikipedia edit history and consist of instances in which a human editor has inserted a single contiguous phrase into, or deleted a single contiguous phrase from, an existing sentence. We use the collected data to show that the language generated during editing differs from the language that we observe in standard corpora, and that models trained on edits encode different aspects of semantics and discourse than models trained on raw, unstructured text. We release the full corpus as a resource to aid ongoing research in semantics, discourse, and representation learning.

30 Aug 2018



We introduce the syntactic scaffold, an approach to incorporating syntactic information into semantic tasks. Syntactic scaffolds avoid expensive syntactic processing at runtime, only making use of a treebank during training, through a multitask objective. We improve over strong baselines on PropBank semantics, frame semantics, and coreference resolution, achieving competitive performance on all three tasks.

22 Jul 2019



Natural language understanding has recently seen a surge of progress with the
use of sentence encoders like ELMo (Peters et al., 2018a) and BERT (Devlin et
al., 2019) which are pretrained on variants of language modeling. We conduct
the first large-scale systematic study of candidate pretraining tasks,
comparing 19 different tasks both as alternatives and complements to language
modeling. Our primary results support the use language modeling, especially
when combined with pretraining on additional labeled-data tasks. However, our
results are mixed across pretraining tasks and show some concerning trends: In
ELMo's pretrain-then-freeze paradigm, random baselines are worryingly strong
and results vary strikingly across target tasks. In addition, fine-tuning BERT
on an intermediate task often negatively impacts downstream transfer. In a more
positive trend, we see modest gains from multitask training, suggesting the
development of more sophisticated multitask and transfer learning techniques as
an avenue for further research.

05 Nov 2018
We study approaches to improve fine-grained short answer Question Answering models by integrating coarse-grained data annotated for paragraph-level relevance and show that coarsely annotated data can bring significant performance gains. Experiments demonstrate that the standard multi-task learning approach of sharing representations is not the most effective way to leverage coarse-grained annotations. Instead, we can explicitly model the latent fine-grained short answer variables and optimize the marginal log-likelihood directly or use a newly proposed \emph{posterior distillation} learning objective. Since these latent-variable methods have explicit access to the relationship between the fine and coarse tasks, they result in significantly larger improvements from coarse supervision.

25 Dec 2018
We propose a method to efficiently learn diverse strategies in reinforcement
learning for query reformulation in the tasks of document retrieval and
question answering. In the proposed framework an agent consists of multiple
specialized sub-agents and a meta-agent that learns to aggregate the answers
from sub-agents to produce a final answer. Sub-agents are trained on disjoint
partitions of the training data, while the meta-agent is trained on the full
training set. Our method makes learning faster, because it is highly
parallelizable, and has better generalization performance than strong
baselines, such as an ensemble of agents trained on the full data. We show that
the improved performance is due to the increased diversity of reformulation
strategies.

07 Aug 2019

We introduce a set of nine challenge tasks that test for the understanding of
function words. These tasks are created by structurally mutating sentences from
existing datasets to target the comprehension of specific types of function
words (e.g., prepositions, wh-words). Using these probing tasks, we explore the
effects of various pretraining objectives for sentence encoders (e.g., language
modeling, CCG supertagging and natural language inference (NLI)) on the learned
representations. Our results show that pretraining on language modeling
performs the best on average across our probing tasks, supporting its
widespread use for pretraining state-of-the-art NLP models, and CCG
supertagging and NLI pretraining perform comparably. Overall, no pretraining
objective dominates across the board, and our function word probing tasks
highlight several intuitive differences between pretraining objectives, e.g.,
that NLI helps the comprehension of negation.

19 Aug 2021

Although automated metrics are commonly used to evaluate NLG systems, they often correlate poorly with human judgements. Newer metrics such as BERTScore have addressed many weaknesses in prior metrics such as BLEU and ROUGE, which rely on n-gram matching. These newer methods, however, are still limited in that they do not consider the generation context, so they cannot properly reward generated text that is correct but deviates from the given reference.
In this paper, we propose Language Model Augmented Relevance Score (MARS), a new context-aware metric for NLG evaluation. MARS leverages off-the-shelf language models, guided by reinforcement learning, to create augmented references that consider both the generation context and available human references, which are then used as additional references to score generated text. Compared with seven existing metrics in three common NLG tasks, MARS not only achieves higher correlation with human reference judgements, but also differentiates well-formed candidates from adversarial samples to a larger degree.
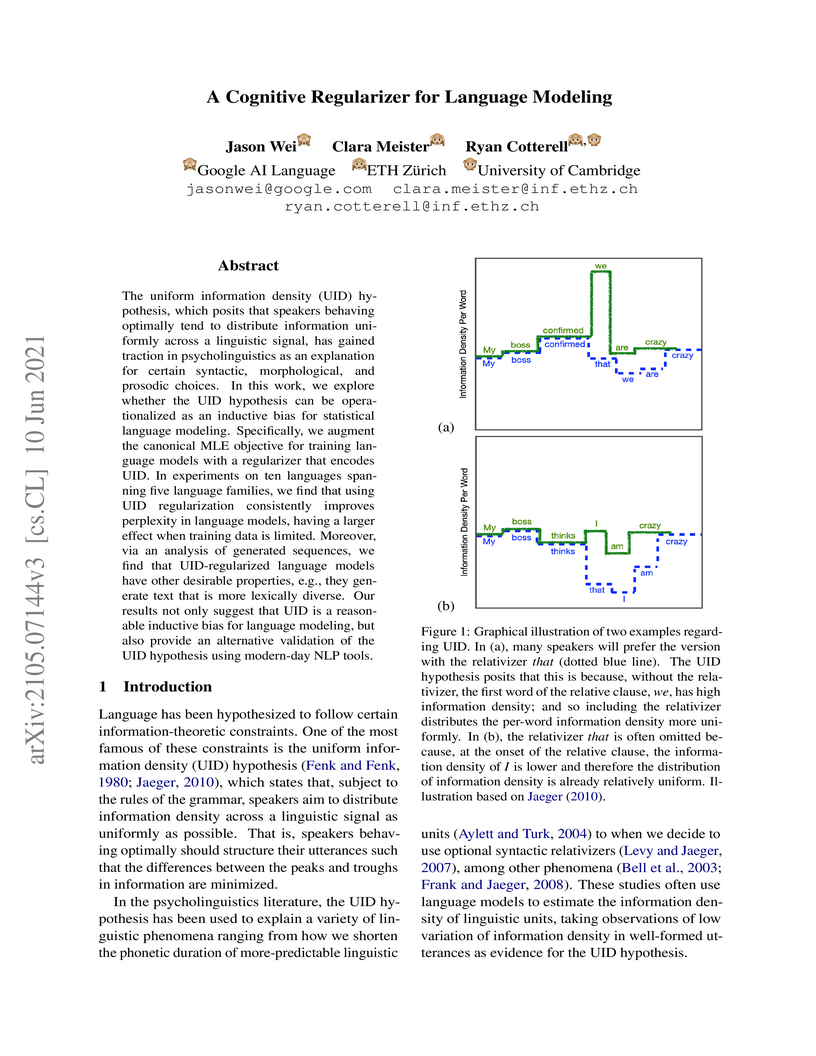
10 Jun 2021


The uniform information density (UID) hypothesis, which posits that speakers
behaving optimally tend to distribute information uniformly across a linguistic
signal, has gained traction in psycholinguistics as an explanation for certain
syntactic, morphological, and prosodic choices. In this work, we explore
whether the UID hypothesis can be operationalized as an inductive bias for
statistical language modeling. Specifically, we augment the canonical MLE
objective for training language models with a regularizer that encodes UID. In
experiments on ten languages spanning five language families, we find that
using UID regularization consistently improves perplexity in language models,
having a larger effect when training data is limited. Moreover, via an analysis
of generated sequences, we find that UID-regularized language models have other
desirable properties, e.g., they generate text that is more lexically diverse.
Our results not only suggest that UID is a reasonable inductive bias for
language modeling, but also provide an alternative validation of the UID
hypothesis using modern-day NLP tools.

26 Jan 2019
Hierarchical neural architectures are often used to capture long-distance dependencies and have been applied to many document-level tasks such as summarization, document segmentation, and sentiment analysis. However, effective usage of such a large context can be difficult to learn, especially in the case where there is limited labeled data available. Building on the recent success of language model pretraining methods for learning flat representations of text, we propose algorithms for pre-training hierarchical document representations from unlabeled data. Unlike prior work, which has focused on pre-training contextual token representations or context-independent {sentence/paragraph} representations, our hierarchical document representations include fixed-length sentence/paragraph representations which integrate contextual information from the entire documents. Experiments on document segmentation, document-level question answering, and extractive document summarization demonstrate the effectiveness of the proposed pre-training algorithms.
There are no more papers matching your filters at the moment.
