
08 Dec 2025

The DEMOCRITUS system establishes a new framework for building large causal models (LCMs) by extracting and structuring textual knowledge from Large Language Models (LLMs) across diverse domains. It leverages a Geometric Transformer to embed and organize vast causal claims into coherent, navigable manifolds, which, unlike raw LLM outputs, exhibit global causal coherence and interpretable local structures.

07 Dec 2025
WisPaper introduces an AI-powered scholar search engine that unifies academic literature discovery, management, and continuous tracking within a single platform. Its core Deep Search component, powered by the WisModel agent, achieved 94.8% semantic similarity in query understanding and 93.70% overall accuracy in paper-criteria matching, demonstrating superior performance over leading commercial LLMs, especially in nuanced judgments.

09 Dec 2025
EcomBench introduces a comprehensive benchmark for evaluating foundation agents in e-commerce, drawing on genuine user demands and expert curation to assess real-world capabilities. The evaluation demonstrates that leading models achieve strong performance on basic tasks but struggle significantly with complex, multi-step e-commerce reasoning and integrating knowledge from various sources.

09 Dec 2025
CLINICALTRIALSHUB unifies clinical trial data from structured registries and unstructured scientific literature, expanding access to structured trial information by 83.8% and providing evidence-grounded, interactive question answering. This platform, developed at The Ohio State University, leverages advanced Large Language Models to streamline information discovery and synthesis for medical professionals and researchers.

10 Dec 2025

Retrieval-Augmented Generation (RAG) integrates non-parametric knowledge into Large Language Models (LLMs), typically from unstructured texts and structured graphs. While recent progress has advanced text-based RAG to multi-turn reasoning through Reinforcement Learning (RL), extending these advances to hybrid retrieval introduces additional challenges. Existing graph-based or hybrid systems typically depend on fixed or handcrafted retrieval pipelines, lacking the ability to integrate supplementary evidence as reasoning unfolds. Besides, while graph evidence provides relational structures crucial for multi-hop reasoning, it is substantially more expensive to retrieve. To address these limitations, we introduce \model{}, an RL-based framework that enables LLMs to perform multi-turn and adaptive graph-text hybrid RAG. \model{} jointly optimizes the entire generation process via RL, allowing the model to learn when to reason, what to retrieve from either texts or graphs, and when to produce final answers, all within a unified generation policy. To guide this learning process, we design a two-stage training framework that accounts for both task outcome and retrieval efficiency, enabling the model to exploit hybrid evidence while avoiding unnecessary retrieval overhead. Experimental results across five question answering benchmarks demonstrate that \model{} significantly outperforms existing RAG baselines, highlighting the benefits of end-to-end RL in supporting adaptive and efficient retrieval for complex reasoning.

10 Dec 2025

Recent advances in large language models (LLMs) have enabled strong reasoning over both structured and unstructured knowledge. When grounded on knowledge graphs (KGs), however, prevailing pipelines rely on heavy neural encoders to embed and score symbolic paths or on repeated LLM calls to rank candidates, leading to high latency, GPU cost, and opaque decisions that hinder faithful, scalable deployment. We propose PathHD, a lightweight and encoder-free KG reasoning framework that replaces neural path scoring with hyperdimensional computing (HDC) and uses only a single LLM call per query. PathHD encodes relation paths into block-diagonal GHRR hypervectors, ranks candidates with blockwise cosine similarity and Top-K pruning, and then performs a one-shot LLM adjudication to produce the final answer together with cited supporting paths. Technically, PathHD is built on three ingredients: (i) an order-aware, non-commutative binding operator for path composition, (ii) a calibrated similarity for robust hypervector-based retrieval, and (iii) a one-shot adjudication step that preserves interpretability while eliminating per-path LLM scoring. On WebQSP, CWQ, and the GrailQA split, PathHD (i) attains comparable or better Hits@1 than strong neural baselines while using one LLM call per query; (ii) reduces end-to-end latency by and GPU memory by thanks to encoder-free retrieval; and (iii) delivers faithful, path-grounded rationales that improve error diagnosis and controllability. These results indicate that carefully designed HDC representations provide a practical substrate for efficient KG-LLM reasoning, offering a favorable accuracy-efficiency-interpretability trade-off.

09 Dec 2025

UniT introduces a framework for text-aware image restoration that iteratively combines a Diffusion Transformer, a Vision-Language Model for linguistic guidance, and a Text Spotting Module for character-level feedback. This approach yields state-of-the-art performance on SA-Text and Real-Text benchmarks while notably suppressing text hallucinations.

05 Dec 2025
Salesforce AI Research and UNC Chapel Hill developed Active Video Perception (AVP), an iterative evidence-seeking framework for long video understanding that leverages MLLMs in a "Plan–Observe–Reflect" loop. AVP achieves state-of-the-art accuracy across five benchmarks while dramatically reducing inference time by 81.6% and token usage by 87.6% compared to prior agentic methods.

08 Dec 2025
The increasing use of synthetic media, particularly deepfakes, is an emerging challenge for digital content verification. Although recent studies use both audio and visual information, most integrate these cues within a single model, which remains vulnerable to modality mismatches, noise, and manipulation. To address this gap, we propose DeepAgent, an advanced multi-agent collaboration framework that simultaneously incorporates both visual and audio modalities for the effective detection of deepfakes. DeepAgent consists of two complementary agents. Agent-1 examines each video with a streamlined AlexNet-based CNN to identify the symbols of deepfake manipulation, while Agent-2 detects audio-visual inconsistencies by combining acoustic features, audio transcriptions from Whisper, and frame-reading sequences of images through EasyOCR. Their decisions are fused through a Random Forest meta-classifier that improves final performance by taking advantage of the different decision boundaries learned by each agent. This study evaluates the proposed framework using three benchmark datasets to demonstrate both component-level and fused performance. Agent-1 achieves a test accuracy of 94.35% on the combined Celeb-DF and FakeAVCeleb datasets. On the FakeAVCeleb dataset, Agent-2 and the final meta-classifier attain accuracies of 93.69% and 81.56%, respectively. In addition, cross-dataset validation on DeepFakeTIMIT confirms the robustness of the meta-classifier, which achieves a final accuracy of 97.49%, and indicates a strong capability across diverse datasets. These findings confirm that hierarchy-based fusion enhances robustness by mitigating the weaknesses of individual modalities and demonstrate the effectiveness of a multi-agent approach in addressing diverse types of manipulations in deepfakes.

10 Dec 2025
We present an end-to-end framework for planning supported by verifiers. An orchestrator receives a human specification written in natural language and converts it into a PDDL (Planning Domain Definition Language) model, where the domain and problem are iteratively refined by sub-modules (agents) to address common planning requirements, such as time constraints and optimality, as well as ambiguities and contradictions that may exist in the human specification. The validated domain and problem are then passed to an external planning engine to generate a plan. The orchestrator and agents are powered by Large Language Models (LLMs) and require no human intervention at any stage of the process. Finally, a module translates the final plan back into natural language to improve human readability while maintaining the correctness of each step. We demonstrate the flexibility and effectiveness of our framework across various domains and tasks, including the Google NaturalPlan benchmark and PlanBench, as well as planning problems like Blocksworld and the Tower of Hanoi (where LLMs are known to struggle even with small instances). Our framework can be integrated with any PDDL planning engine and validator (such as Fast Downward, LPG, POPF, VAL, and uVAL, which we have tested) and represents a significant step toward end-to-end planning aided by LLMs.

08 Dec 2025
Recent advances in large reasoning models (LRMs) have enabled agentic search systems to perform complex multi-step reasoning across multiple sources. However, most studies focus on general information retrieval and rarely explores vertical domains with unique challenges. In this work, we focus on local life services and introduce LocalSearchBench, which encompass diverse and complex business scenarios. Real-world queries in this domain are often ambiguous and require multi-hop reasoning across merchants and products, remaining challenging and not fully addressed. As the first comprehensive benchmark for agentic search in local life services, LocalSearchBench includes over 150,000 high-quality entries from various cities and business types. We construct 300 multi-hop QA tasks based on real user queries, challenging agents to understand questions and retrieve information in multiple steps. We also developed LocalPlayground, a unified environment integrating multiple tools for agent interaction. Experiments show that even state-of-the-art LRMs struggle on LocalSearchBench: the best model (DeepSeek-V3.1) achieves only 34.34% correctness, and most models have issues with completeness (average 77.33%) and faithfulness (average 61.99%). This highlights the need for specialized benchmarks and domain-specific agent training in local life services. Code, Benchmark, and Leaderboard are available at this http URL.

08 Dec 2025
NeSTR is a neuro-symbolic abductive framework designed to enhance temporal reasoning in Large Language Models (LLMs) through a five-stage prompting strategy that integrates symbolic representation, neural inference, and error correction. The framework achieved a macro-average F1 score of 89.7 with GPT-4o-mini, surpassing prior methods and demonstrating robust zero-shot performance across various temporal question answering benchmarks.

10 Dec 2025
This chapter explores the application of Large Language Models in the legal domain, showcasing their potential to optimise and augment traditional legal tasks by analysing possible use cases, such as assisting in interpreting statutes, contracts, and case law, enhancing clarity in legal summarisation, contract negotiation, and information retrieval. There are several challenges that can arise from the application of such technologies, such as algorithmic monoculture, hallucinations, and compliance with existing regulations, including the EU's AI Act and recent U.S. initiatives, alongside the emerging approaches in China. Furthermore, two different benchmarks are presented.

09 Dec 2025
Stock market prediction is a long-standing challenge in finance, as accurate forecasts support informed investment decisions. Traditional models rely mainly on historical prices, but recent work shows that financial news can provide useful external signals. This paper investigates a multimodal approach that integrates companies' news articles with their historical stock data to improve prediction performance. We compare a Graph Neural Network (GNN) model with a baseline LSTM model. Historical data for each company is encoded using an LSTM, while news titles are embedded with a language model. These embeddings form nodes in a heterogeneous graph, and GraphSAGE is used to capture interactions between articles, companies, and industries. We evaluate two targets: a binary direction-of-change label and a significance-based label. Experiments on the US equities and Bloomberg datasets show that the GNN outperforms the LSTM baseline, achieving 53% accuracy on the first target and a 4% precision gain on the second. Results also indicate that companies with more associated news yield higher prediction accuracy. Moreover, headlines contain stronger predictive signals than full articles, suggesting that concise news summaries play an important role in short-term market reactions.
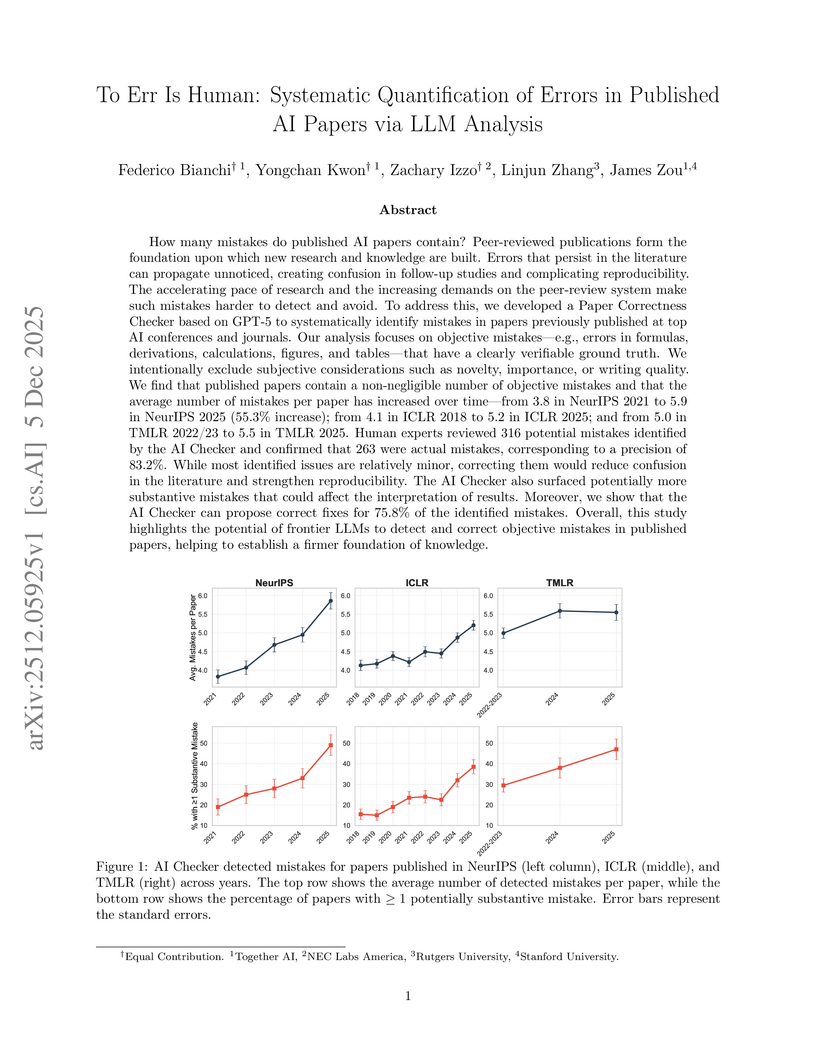
05 Dec 2025
Researchers at Stanford University and Together AI systematically quantified objective errors in 2,500 published AI papers using a GPT-5-powered "AI Correctness Checker." Their findings indicate that 99.2% of papers contain at least one mistake, with error rates increasing annually, and the LLM achieved 83.2% precision and 60.0% recall in detecting these errors while proposing correct fixes for 75.8% of them.

10 Dec 2025
We present Auto-BenchmarkCard, a workflow for generating validated descriptions of AI benchmarks. Benchmark documentation is often incomplete or inconsistent, making it difficult to interpret and compare benchmarks across tasks or domains. Auto-BenchmarkCard addresses this gap by combining multi-agent data extraction from heterogeneous sources (e.g., Hugging Face, Unitxt, academic papers) with LLM-driven synthesis. A validation phase evaluates factual accuracy through atomic entailment scoring using the FactReasoner tool. This workflow has the potential to promote transparency, comparability, and reusability in AI benchmark reporting, enabling researchers and practitioners to better navigate and evaluate benchmark choices.

10 Dec 2025

LLM-based Search Engines (LLM-SEs) introduces a new paradigm for information seeking. Unlike Traditional Search Engines (TSEs) (e.g., Google), these systems summarize results, often providing limited citation transparency. The implications of this shift remain largely unexplored, yet raises key questions regarding trust and transparency. In this paper, we present a large-scale empirical study of LLM-SEs, analyzing 55,936 queries and the corresponding search results across six LLM-SEs and two TSEs. We confirm that LLM-SEs cites domain resources with greater diversity than TSEs. Indeed, 37% of domains are unique to LLM-SEs. However, certain risks still persist: LLM-SEs do not outperform TSEs in credibility, political neutrality and safety metrics. Finally, to understand the selection criteria of LLM-SEs, we perform a feature-based analysis to identify key factors influencing source choice. Our findings provide actionable insights for end users, website owners, and developers.

05 Dec 2025
Researchers from TNO and Leiden/Utrecht Universities systematically evaluated Large Language Models' capability to automatically identify five types of logical axioms, introducing the OntoAxiom benchmark for quantitative assessment. The study found LLMs excel at `subClassOf` axioms but struggle with `rdfs:domain` and `rdfs:range`, with proprietary and larger models showing superior performance, indicating potential for generating candidate axioms to assist ontology engineers.

04 Dec 2025
Researchers developed SEAL, a self-evolving agentic learning framework for conversational question answering over knowledge graphs that employs a two-stage parsing mechanism to generate structurally accurate logical forms from natural language. It reached an overall accuracy of 66.83% on the SPICE benchmark, significantly surpassing unsupervised baselines and showing strong performance on complex multi-hop, quantitative, and comparative reasoning.

06 Dec 2025
Existing fine-grained image retrieval (FGIR) methods learn discriminative embeddings by adopting semantically sparse one-hot labels derived from category names as supervision. While effective on seen classes, such supervision overlooks the rich semantics encoded in category names, hindering the modeling of comparability among cross-category details and, in turn, limiting generalization to unseen categories. To tackle this, we introduce LaFG, a Language-driven framework for Fine-Grained Retrieval that converts class names into attribute-level supervision using large language models (LLMs) and vision-language models (VLMs). Treating each name as a semantic anchor, LaFG prompts an LLM to generate detailed, attribute-oriented descriptions. To mitigate attribute omission in these descriptions, it leverages a frozen VLM to project them into a vision-aligned space, clustering them into a dataset-wide attribute vocabulary while harvesting complementary attributes from related categories. Leveraging this vocabulary, a global prompt template selects category-relevant attributes, which are aggregated into category-specific linguistic prototypes. These prototypes supervise the retrieval model to steer
There are no more papers matching your filters at the moment.
